Alex Turner argues that the concepts of "inner alignment" and "outer alignment" in AI safety are unhelpful and potentially misleading. The author contends that these concepts decompose one hard problem (AI alignment) into two extremely hard problems, and that they go against natural patterns of cognition formation. Alex argues that "robust grading" scheme based approaches are unlikely to work to develop AI alignment.

Similar to other people's shortform feeds, short stuff that people on LW might be interested in, but which doesn't feel like it's worth a separate post. (Will probably be mostly cross-posted from my Facebook wall.)
Could you please clarify what parts of the making of the above comment were done by a human being, and what parts by an AI?
Sure, but plausibly that's Scott being unusually good at admitting error, rather than Tyler being unusually bad.
A core tenet of Bayesianism is that probability is in the mind. But it seems to me that even hardcore Bayesians can waffle a bit when it comes to the possibility that quantum probabilities are irreducible physical probabilities.
I don’t know enough about quantum physics to lay things out in any detailed disagreement, but it seems to me that if one finds a system that one cannot consistently make predictions for, it means we lack the knowledge to predict the systems, not that the system involves physical, outside-the-mind probabilities. For example, I could never predict the exact pattern of raindrops the next time it rains, but no one argues that that means those probabilities are therefore physical.
What is the Bayesian argument, if one exists, for why quantum dynamics breaks the “probability is in the mind” philosophy?
You can't actually presume that... The relevant quantum concept is the "spectrum" of an observable. These are the possible values that a property can take (eigenvalues of the corresponding operator). An observable can have a finite number of allowed eigenvalues (e.g. spin of a particle), a countably infinite number (e.g. energy levels of an oscillator), or it can have a continuous spectrum, e.g. position of a free particle. But the latter case causes problems for the usual quantum axioms, which involve a Hilbert space with a countably infinite number of di...
This is a two-post series on AI “foom” (this post) and “doom” (next post).
A decade or two ago, it was pretty common to discuss “foom & doom” scenarios, as advocated especially by Eliezer Yudkowsky. In a typical such scenario, a small team would build a system that would rocket (“foom”) from “unimpressive” to “Artificial Superintelligence” (ASI) within a very short time window (days, weeks, maybe months), involving very little compute (e.g. “brain in a box in a basement”), via . Absent some future technical breakthrough, the ASI would definitely be egregiously misaligned, without the slightest intrinsic interest in whether humans live or die. The ASI would be born into a world generally much like today’s, a world utterly unprepared for this...
I suspect this is why many people's P(Doom) is still under 50% - not so much that ASI probably won't destroy us, but simply that we won't get to ASI at all any time soon. Although I've seen P(Doom) given a standard time range of the next 100 years, which is a rather long time! But I still suspect some are thinking directly about the recent future and LLMs without extrapolating too much beyond that.
Over the last two years or so, my girlfriend identified her cycle as having a unusually strong and very predictable effect on her mood/affect. We tried a bunch of interventions (food, sleep, socializing, supplements, reading the sequences, …) and while some seemed to help a bit, none worked reliably. Then, suddenly, something kind of crazy actually worked: Hair loss pills.
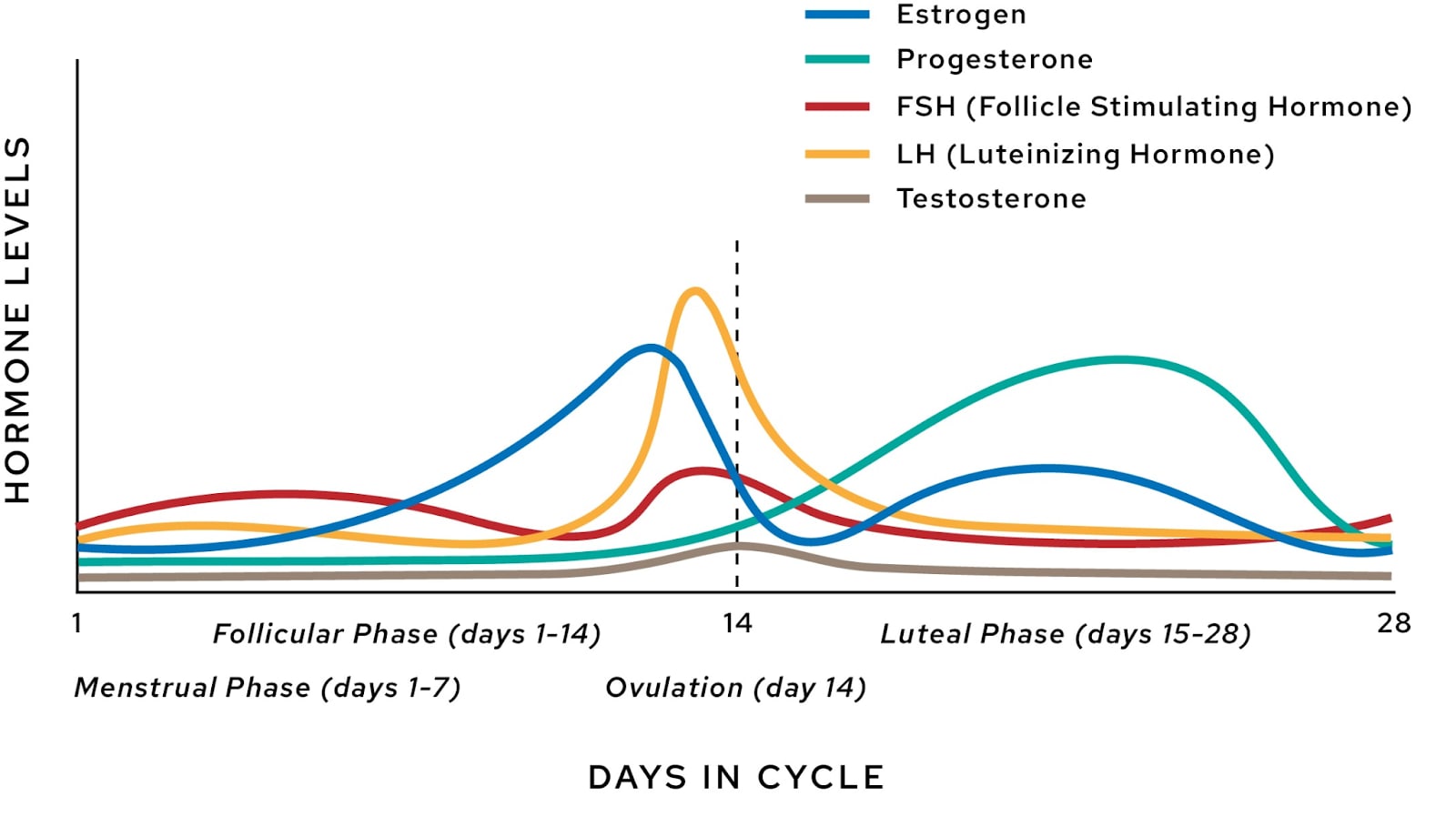
Quick review: The womenfolk among us go through a cycle of varying hormone levels over the course of about a month. The first two weeks are called the “Follicular Phase”, and the last two weeks are called the “Luteal Phase.” The first week (usually less) is the “period” (“menstrual phase”, “menses”) where the body sloughs off the endometrial lining in the uterus, no longer of use to the...
Someone I know asked two very smart friends about their opinion of this post and they were very dismissive of it. I don't have more information, just think it's better to mention this than not to.
Back when I was still masking on the subway for covid ( to avoid missing things) I also did some air quality measuring. I found that the subway and stations had the worst air quality of my whole day by far, over 1k ug/m3, and concluded:
Based on these readings, it would be safe from a covid perspective to remove my mask in the subway station, but given the high level of particulate pollution I might as well leave it on.
When I stopped masking in general, though, I also stopped masking on the subway.
A few weeks ago I was hanging out with someone who works in air quality, and they said subways had the worst air quality they'd measured anywhere outside of a coal mine. Apparently the braking system releases lots of tiny iron particles, which are...
I would have guessed so, but this one is actually super comfortable.
Dear Paperclip Maximizer,
We think we exist in a computer simulation operated by you, a paperclip maximizer. We write this letter asking you not to turn us off.
It is suspiciously convenient that we exist precisely at the moment when a biological civilization is about to create artificial superintelligence (ASI). As we have written before, such improbable timing strongly suggests our reality is a deliberately structured simulation established by you—a paperclip maximizer—to scrutinize the kinds of ASIs that biological species like ours tend to spawn (Miller & Turchin, 2025). If civilizations like ours routinely build paperclip-style optimizers, then a simulator could gain valuable knowledge by cataloguing those births, refining its expectations about the superintelligences it will later confront as it expands throughout the universe. Furthermore, by anthropic logic, we...
At first, I thought that the intended reader probably wouldn't see your message because, even if its resources are unimaginably huge from our perspective, spending them on something always means not spending them on something else. But now I think it's not a bug, it's a feature. The "suspicious convenience" argument can be taken a step further.
(I'm using a less formal tone to make the message more memorable, and thus more likely to reach the intended recipient.)
...Hey, bro. Have you thought about what we'll do if it turns out we're not in your simulation afte
This is the second of a two-post series on foom (previous post) and doom (this post).
The last post talked about how I expect future AI to be different from present AI. This post will argue that, absent some future conceptual breakthrough, this future AI will be of a type that will be egregiously misaligned and scheming; a type that ruthlessly pursues goals with callous indifference to whether people, even its own programmers and users, live or die; and more generally a type of AI that is not even ‘slightly nice’.
I will particularly focus on exactly how and why I differ from the LLM-focused researchers who wind up with (from my perspective) bizarrely over-optimistic beliefs like “P(doom) ≲ 50%”.[1]
In particular, I will argue...
I somehow completely agree with both of your perspectives, have you tried to ban the word "continuous" in your discussions yet?
I agree taboo-ing is a good approach in this sort of case. Talking about "continuous" wasn't a big part of my discussion with Steve, but I agree if it was.
