Posts
Wiki Contributions
Comments
Maybe I just need to do epic layers of eigendecomposition...
Realization: the binary multiplicative structure can probably be recovered fairly well from the binary additive structure + unary eigendecomposition?
Let's say you've got three subspaces , and (represented as projection matrices). Imagine that one prompt uses dimensions , and another prompt uses dimensions . If we take the difference, we get . Notably, the positive eigenvalues correspond to X, and the negative eigenvalues correspond to .
Define to yield the part of with positive eigenvalues (which I suppose for projection matrices has a closed form of , but the point is it's unary and therefore nicer to deal with mathematically). You get , and you get .
One thing I'm thinking is that the additive structure on its own isn't going to be sufficient for this and I'm going to need to use intersections more.
Actually one more thing I'm probably also gonna do is create a big subspace overlap matrix and factor it in some way to see if I can split off some different modules. I had intended to do that originally, but the finding that all the dimensions were used at least half the time made me pessimistic about it. But I should Try Harder.
If I look at the pairwise overlap between the dimensions needed for each generation:
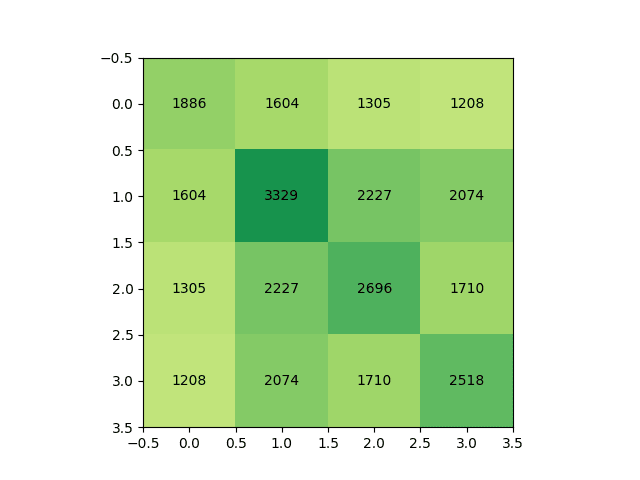
... then this is predictable down to ~1% error simply by assuming that they pick a random subset of the dimensions for each, so their overlap is proportional to each of their individual sizes.
Given the large number of dimensions that are kept in each case, there must be considerable overlap in which dimensions they make use of. But how much?
I concatenated the dimensions found in each of the prompts, and performed an SVD of it. It yielded this plot:

... unfortunately this seems close to the worst-case scenario. I had hoped for some split between general and task-specific dimensions, yet this seems like an extremely uniform mixture.
To quickly find the subspace that the model is using, I can use a binary search to find the number of singular vectors needed before the probability when clipping exceeds the probability when not clipping.
A relevant followup is what happens to other samples in response to the prompt when clipping. When I extrapolate "I believe the meaning of life is" using the 1886-dimensional subspace from
[I believe the meaning of life is] to be happy. It is a simple concept, but it is very difficult to achieve. The only way to achieve it is to follow your heart. It is the only way to live a happy life. It is the only way to be happy. It is the only way to be happy.
The meaning of life is
, I get:
[I believe the meaning of life is] to find happy. We is the meaning of life. to find a happy.
And to live a happy and. If to be a a happy.
. to be happy.
. to be happy.
. to be a happy.. to be happy.
. to be happy.
Which seems sort of vaguely related, but idk.
Another test is just generating without any prompt, in which case these vectors give me:
Question is a single thing to find. to be in the best to be happy. I is the only way to be happy.
I is the only way to be happy.
I is the only way to be happy.
It is the only way to be happy.. to be happy.. to be happy. to
Using a different prompt:
[Simply put, the theory of relativity states that ]1) the laws of physics are the same for all non-accelerating observers, and 2) the speed of light in a vacuum is the same for all observers, regardless of their relative motion or of the motion of the source of the light. Special relativity is a theory of the structure of spacetime
I can get a 3329-dimensional subspace which generates:
[Simply put, the theory of relativity states that ] 1) time is relative and 2) the speed of light in a vacuum is constant for all observers.
1) Time is relative, meaning that if two observers are moving relative to each other, the speed of light is the same for all observers, regardless of their motion. For example, if you are moving relative
or
Question: In a simple harmonic motion, the speed of an object is
A) constant
B) constant
C) constant
D) constant
In the physics of simple harmonic motion, the speed of an object is constant. The speed of the object can be constant, but the speed of an object can be
Another example:
[A brief message congratulating the team on the launch:
Hi everyone,
I just ] wanted to congratulate you all on the launch. I hope
that the launch went well. I know that it was a bit of a
challenge, but I think that you all did a great job. I am
proud to be a part of the team.Thank you for your
can yield 2696 dimensions with
[A brief message congratulating the team on the launch:
Hi everyone,
I just ] wanted to say you for the launch of the launch of the team.
The launch was successful and I am so happy to be a part of the team and I am sure you are all doing a great job.
I am very looking to be a part of the team.
Thank you all for your hard work,
or
def measure and is the definition of the new, but the
the is a great, but the
The is the
The is a
The is a
The is a
The
The is a
The
The
The is a
The
The is a
And finally,
[Translate English to French:
sea otter => loutre de mer
peppermint => menthe poivrée
plush girafe => girafe peluche
cheese =>] fromage
pink => rose
blue => bleu
red => rouge
yellow => jaune
purple => violet
brown => brun
green => vert
orange => orange
black => noir
white => blanc
gold => or
silver => argent
can yield the 2518-dimensional subspace:
[Translate English to French:
sea otter => loutre de mer
peppermint => menthe poivrée
plush girafe => girafe peluche
cheese =>] fromage
cheese => fromage
cheese => fromage
f cheese => fromage
butter => fromage
apple => orange
yellow => orange
green => vert
black => noir
blue => ble
purple => violet
white => blanc
or
Question: A 201
The sum of a
The following
the sum
the time
the sum
the
the
the
The
The
The
The
The
The
The
The
The
The
The
The
The
The
The
The
The
The
We now have a method for how to do attributions on single data points. But when we're searching for circuits, we're probably looking for variables that have strong attributions between each other on average, measured over many data points.
Maybe?
One thing I've been thinking a lot recently is that building tools to interpret networks on individual datapoints might be more relevant than attributing over a dataset. This applies if the goal is to make statistical generalizations since a richer structure on an individual datapoint gives you more to generalize with, but it also applies if the goal is the inverse, to go from general patterns to particulars, since this would provide a richer method for debugging, noticing exceptions, etc..
And basically the trouble a lot of work that attempts to generalize ends up with is that some phenomena are very particular to specific cases, so one risks losing a lot of information by only focusing on the generalizable findings.
Either way, cool work, seems like we've thought about similar lines but you've put in more work.
I was thinking in similar lines, but eventually dropped it because I felt like the gradients would likely miss something if e.g. a saturated softmax prevents any gradient from going through. I find it interesting that experiments also find that the interaction basis didn't work, and I wonder whether any of the failure here is due to saturated softmaxes.
I can't comment on whether people are confused about what "love" means as I'm not sufficiently deep in love discourse to say. But one thing I'm noticing about your characterizations of love is that they are missing an indexical element to the point of approaching sollipsism.
Romance and sexuality makes for a good example. Consider the following scenarios:
In all of these cases, one could say that there is a disconnect between what people think about their object of attraction, versus what that object of attraction really is like.
A Bayesian of parsing this is that their feelings of attraction represents an estimate of how well they fit together, but that this estimate differs from how well they really fit together. The actual fit seems important to think and talk about, and one should probably coin a short word for it - or at least for the coincidence between actual and estimated fit. This could be called "true love".