Worried that typical commenters at LW care way less than I expected about good epistemic practice. Hoping I'm wrong.
Software developer and EA with interests including programming language design, international auxiliary languages, rationalism, climate science and the psychology of its denial.
Looking for someone similar to myself to be my new best friend:
❖ Close friendship, preferably sharing a house ❖ Rationalist-appreciating epistemology; a love of accuracy and precision to the extent it is useful or important (but not excessively pedantic) ❖ Geeky, curious, and interested in improving the world ❖ Liberal/humanist values, such as a dislike of extreme inequality based on minor or irrelevant differences in starting points, and a like for ideas that may lead to solving such inequality. (OTOH, minor inequalities are certainly necessary and acceptable, and a high floor is clearly better than a low ceiling: an "equality" in which all are impoverished would be very bad) ❖ A love of freedom ❖ Utilitarian/consequentialist-leaning; preferably negative utilitarian ❖ High openness to experience: tolerance of ambiguity, low dogmatism, unconventionality, and again, intellectual curiosity ❖ I'm a nudist and would like someone who can participate at least sometimes ❖ Agnostic, atheist, or at least feeling doubts
Posts
Wiki Contributions
Comments
Another thing: not only is my idea unpopular, it's obvious from vote counts that some people are actively opposed to it. I haven't seen any computational epistemology (or evidence repository) project that is popular on LessWrong, either. Have you seen any?
If in fact this sort of thing tends not to interest LessWrongers, I find that deeply disturbing, especially in light of the stereotypes I've seen of "rationalists" on Twitter and EA forum. How right are the stereotypes? I'm starting to wonder.
I can't recall another time when someone shared their personal feelings and experiences and someone else declared it "propaganda and alarmism". I haven't seen "zero-risker" types do the same, but I would be curious to hear the tale and, if they share it, I don't think anyone one will call it "propaganda and killeveryoneism".
My post is weirdly aggressive? I think you are weirdly aggressive against Scott.
Since few people have read the book (including, I would wager, Cade Metz), the impact of associating Scott with Bell Curve doesn't depend directly on what's in the book, it depends on broad public perceptions of the book.
Having said that, according to Shaun (here's that link again), the Bell Curve relies heavily of the work of Richard Lynn, who was funded by, and later became the head of, the Pioneer Fund, which the Southern Poverty Law Center classifies as a hate group. In contrast, as far as I know, the conclusions of the sources cited by Scott do not hinge upon Richard Lynn. And given this, it would surprise me if the conclusions of The Bell Curve actually did match the mainstream consensus.
One of Scott's sources says 25-50% for "heritability" of the IQ gap. I'm pretty confident the Bell Curve doesn't say this, and I give P>50% that The Bell Curve suggests/states/implies that the IQ gap is over 50% "heritable" (most likely near 100%). Shaun also indicated that the Bell Curve equated heritability with explanatory power (e.g. that if heritability is X%, Murray's interpretation would be that genetics explains or causes X% of the IQ gap). Shaun persuasively refuted this. I did not come away with a good understanding of how to think about heritability, but I expect experts would understand the subtlety of this topic better than Charles Murray.
And as Shaun says:
It's not simply that Herrnstein & Murray are breaking the supposed taboo of discussing IQ differences that sparked the backlash. It's that they explicitly linked those differences to a set of policy proposals. This is why The Bell Curve is controversial, because of its political ideas.
For example, that welfare programs should be stopped, which I think Scott has never advocated and which he would, in spirit, oppose. It also seems relevant that Charles Murray seems to use bad logic in his policy reasoning, as (1) this might be another reason the book was so controversial and (2) we're on LessWrong where that sort of thing usually matters.
Having said that, my prior argument that you've been unreasonable does not depend on any of this. A personal analogy: I used to write articles about climate science (ex1, ex2, ex3). This doesn't mean I'm "aligned" with Greta Thunberg and Al Gore or whatever specific person in the climate space you have in mind. I would instantly dislike someone who makes or insists upon claiming my views correspond to those particular people or certain others, as it would be inappropriate as well as untrue. Different people in the climate space do in fact take different positions on various questions other than the single most contested one (and they have different reputations, and I expect that human beings in the field of genetics work the same way). Even if you just say I have a "James Hansen poster on my bedroom wall" I'm going to be suspicious―sure, I respect the guy and I agree with him in some respects, but I'm not familiar with all his positions and what do you know about it anyway? And if you also argue against me by posting a Twitter thread by someone who appears to hate my guts... well... that is at least weirdly aggressive.
I also think that insisting on conflating two different things, after someone has pointed out to you that they are different, is a very anti-rationalist, un-LessWrong thing to do.
Edit: also weirdly aggressive is strong downvoting good faith replies. I don't have the faintest idea why you're acting like this, but it's scary as hell and I hope to Moloch that other people notice too. A downvote is not a counterargument! It's precisely as meaningful as a punch in the face! It doesn't make you right or me wrong, it merely illustrates how humanity is doomed.
I like that HowTruthful uses the idea of (independent) hierarchical subarguments, since I had the same idea. Have you been able to persuade very many to pay for it?
My first thought about it was that the true/false scale should have two dimensions, knowledge & probability:
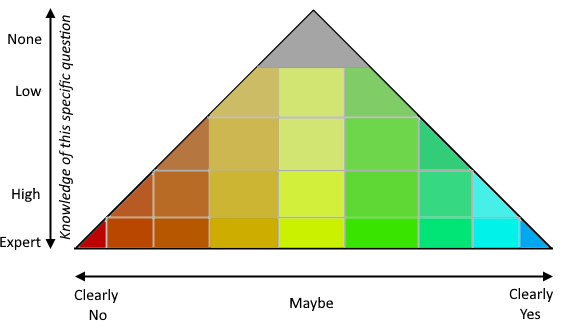
One of the many things I wanted to do on my site was to gather user opinions, and this does that. ✔ I think of opinions as valuable evidence, just not always valuable evidence about the question under discussion (though to the extent people with "high knowledge" really have high knowledge rather than pretending to, it actually is evidence). Incidentally I think it would be interesting to show it as a pyramid but let people choose points outside the pyramid, so users can express their complete certainty about matters they have little knowledge of...
Here are some additional thoughts about how I might enhance HowTruthful if it were my project:
(1) I take it that the statements form a tree? I propose that statements should form a DAG (directed acyclic graph ― a cyclic graph could possibly be useful, but would open a big can of worms). The answer to one question can be relevant to many others.
(2) Especially on political matters, a question/statement can be contested in various ways:
- "ambiguous/depends/conflated/confused": especially if the answer depends on the meaning of the question; this contestation can be divided into just registering a complaint, on the one hand, and proposing a rewording or that it be split into clearer subquestions, on the other hand. Note that if a question is split, the original question can reasonably keep its own page so that when someone finds the question again, they are asked which clarified question they are interested in. If a question is reworded, potentially the same thing can be done, with the original question kept with the possibility of splitting off other meanings in the future.
- "mu": reject the premise of the question (e.g. "has he stopped beating his wife?"), with optional explanation. Also "biased" (the question proposes its own answer), "inflammatory" (unnecessarily politicized language choice), "dog whistle" (special case of politicized language choice). Again one can imagine a UI to propose rewordings.
- sensitive (violence/nudity): especially if pic/vid support is added, some content can be simultaneously informative/useful and censored by default
- spam (irrelevant and inappropriate => deleted), or copyright claim (deleted by law)
(3) The relationship between parent and child statements can be contested, or vary in strength:
- "irrelevant/tangential": the statement has no bearing on its parent. This is like a third category apart from pro/evidence in favor and con/evidence against.
- "miscategorized": this claims that "pro" information should be considered "con" and vice versa. Theoretically, Bayes' rule is useful for deciding which is which.
This could be refined into a second pyramid representing the relationship between the parent and child statements. The Y axis of the pyramid is how relevant the child statement is to the parent, i.e. how correlated the answers to the two questions ought to be. The X axis is pro/con (how the answer to the question affects the answer to the parent question.) Note that this relationship itself could reasonably be a separate subject of debate, displayable on its own page.
(4) Multiple substatements can be combined, possibly with help from an LLM. e.g. user pastes three sources that all make similar points, then the user can select the three statements and click "combine" to LLM-generate a new statement that summarizes whatever the three statements have in common, so that now the three statements are children of the newly generated statement.
(5) I'd like to see automatic calculation of the "truthiness" of parent statements. This offers a lot of value in the form of recursion: if a child statement is disproven, that affects its parent statement, which affects the parent's parent, etc., so that users can get an idea of the likelihood of the parent statement based on how the debate around the great-grandchild statements turned out. Related to that, the answers to two subquestions can be highly correlated with each other, which can decrease the strength of the two points together. For example, suppose I cite two sources that say basically the same thing, but it turns out they're both based on the same study. Then the two sources and the study itself are nearly 100% correlated and can be treated altogether as a single piece of evidence. What UI should be used in relation to this? I have no idea.
(6) Highlighting one-sentence bullet points seems attractive, but I also think Fine Print will be necessary in real-life cases. Users could indicate the beginning of fine print by typing one or two newlines; also the top statement should probably be cut off (expandable) if it is more than four lines or so.
(7) I propose distinguishing evidentiary statements, which are usually but not always leaf nodes in the graph. Whenever you want to link to a source, its associated statement must be a relevant summary, which means that it summarizes information from that source relevant to the current question. Potentially, people can just paste links to make an LLM generate a proposed summary. Example: if the parent statement proposes "Crime rose in Canada in 2022", and in a blank child statement box the user pastes a link to "The root cause': Canada outlines national action plan to fight auto theft", an LLM generates a summary by quoting the article: "According to 2022 industry estimates [...], rates of auto theft had spiked in several provinces compared to the year before. [Fine print] In Quebec, thefts rose by 50 per cent. In Ontario, they were up 34.5 per cent."
(8) Other valuable features would include images, charts, related questions, broader/parent topics, reputation systems, alternative epistemic algorithms...
(9) Some questions need numerical (bounded or unbounded) or qualitative answers; I haven't thought much about those. Edit: wait, I just remembered my idea of "paradigms", i.e. if there are appropriate answers besides "yes/true" and "false/no", these can be expressed as a statement called a "paradigm", and each substatement or piece of available evidence can (and should) be evaluated separately against each paradigm. Example: "What explains the result of the Michelson–Morley experiment of 1881?" Answer: "The theory of Special Relativity". Example: "What is the shape of the Earth?" => "Earth is a sphere", "Earth is an irregularly shaped ellipsoid that is nearly a sphere", "Earth is a flat disc with the North Pole in the center and Antarctica along the edges". In this case users might first place substatements under the paradigm that they match best, but then somehow a process is needed to consider each piece of evidence in the context of each subparadigm. It could also be the case that a substatement doesn't fit any of the current paradigms well. I was thinking that denials are not paradigms, e.g. "What is the main cause of modern global warming?" can be answered with "Volcanoes are..." or "Natural internal variability and increasing solar activity are..." but "Humans are not the cause" doesn't work as an answer ("Nonhumans are..." sounds like it works, but allows that maybe elephants did it). "It is unknown" seems like a special case where, if available evidence is a poor fit to all paradigms, maybe the algorithm can detect that and bring it to users' attention automatically?
Another thing I thought a little bit about was negative/universal statements, e.g. "no country has ever achieved X without doing Y first" (e.g. as evidence that we should do Y to help achieve X). Statements like this are not provable, only disproveable, but it seems like the more people who visit and agree with a statement, without it being disproven, the more likely it is that the statement is true... this may impact epistemic algorithms somehow. I note that when a negative statement is disproven, a replacement can often be offered that is still true, e.g. "only one country has ever achieved X without doing Y first".
(10) LLMs can do various other tasks, like help detect suspicious statements (spam, inflammatory language, etc.), propose child statements, etc. Also there could be a button for sending statements to (AI and conventional) search engines...
Ah, this is nice. I was avoiding looking at my notifications for the last 3 months for fear of a reply by Christian Kl, but actually it turned out to be you two :D
I cannot work on this project right now because busy I'm earning money to be able to afford to fund it (as I don't see how to make money on it). I have a family of 4+, so this is far from trivial. I've been earning for a couple of years, and I will need a couple more years more. I will leave my thoughts on HowTruthful on one of your posts on it.
Yesterday Sam Altman stated (perhaps in response to the Vox article that mentions your decision) that "the team was already in the process of fixing the standard exit paperwork over the past month or so. if any former employee who signed one of those old agreements is worried about it, they can contact me and we'll fix that too."
I notice he did not include you in the list of people who can contact him to "fix that", but it seems worth a try, and you can report what happens either way.
This is practice sentence to you how my brain. I wonder how noticeable differences are to to other people.
That first sentence looks very bad to me; the second is grammatically correct but feels like it's missing an article. If that's not harder for you to understand than for other people, I still think there's a good chance that it could be harder for other dyslexic people to understand (compared to correct text), because I would not expect that the glitches in two different brains with dyslexia are the same in every detail (that said, I don't really understand what dyslexia means, though my dad and brother say they have dyslexia.)
the same word ... foruthwly and fortunly and forrtunaly
You appear to be identifying the word by its beginning and end only, as if it were visually memorized. Were you trained in phonics/phonetics as a child? (I'm confused why anyone ever thought that whole-word memorization was good, but it is popular in some places.) This particular word does have a stranger-than-usual relationship between spelling and pronunciation, though.
> I can do that too. Thankfully. Unless I don’t recognize the sounds.
My buffer seems shorter on unfamiliar sounds. Maybe one second.
> reading out loud got a little obstructive. I started subvocalizing, and that was definitely less fun.
I always read with an "auditory" voice in my head, and I often move my tongue and voicebox to match the voice (especially if I give color to that voice, e.g. if I make it sound like Donald Trump). I can't can't speed-read but if I read fast enough, the "audio" tends to skip and garble some words, but I still mostly detect the meanings of the sentences. My ability to read fast was acquired slowly through much practice, though. I presume that the "subvocalization" I do is an output from my brain rather than necessary for communication within it. However, some people have noticed that sometimes, after I say something, or when I'm processing what someone has told me, I visibly subvocalize the same phrase again. It's unclear whether this is just a weird habit, or whether it helps me process the meaning of the phrase. (the thing where I repeat my own words to myself seems redundant, as I can detect flaws in my own speech the first time without repetition.)
Doublecrux sounds like a better thing than debate, but why such an event should be live? (apart from "it saves money/time not to postprocess")
I agree with this, but that "the horsepower of AI is instead coming from oodles of training data" is not a fact that seems relevant to me, except in the sense that this is driving up AI-related chip manufacturing (which, however, wasn't mentioned). The reason I argue it's not otherwise relevant is that the horsepower of ASI will not, primarily, come from oodles of training data. To the contrary, it will come from being able to reason, learn and remember better than humans do, and since (IIUC) LLMs function poorly if they are trained only on a dataset sized for human digestion, this implies AGI and ASI need less training data than LLMs, probably much less, for a given performance level (which is not to say more data isn't useful to them, it's just not what makes them AGI). So in my view, making AGI (and by extension AGI alignment) is mainly a matter of algorithms that have not yet been invented and therefore cannot be empirically tested, and less a matter of training data. Making ASI, in turn, is mainly a matter of compute (which already seems too abundant).
(disclaimer: I'm not an AI expert. Also it's an interesting question whether OpenAI will find a trick that somehow turns LLMs into AGI with little additional innovation, but supposing that's true, does the AGI alignment community have enough money and compute to do empirical research in the same direction, given the disintegration of OpenAI's Superalignment Team?)
I agree the first AGIs probably won't be epistemically sound agents maximizing an objective function: even rationalists have shown little interest in computational epistemology, and the dangers of maximizers seem well-known so I vaguely doubt leading AGI companies are pursuing that approach. Epistemically-poor agents without an objective function are often quite dangerous even with modest intelligence, though (e.g. many coup attempts have succeeded on the first try). Capabilities people seem likely to try human-inspired algorithms, which argues for alignment research along the same lines, but I'm not sure if this will work:
So while the criticism seems sound, what should alignment researchers do instead?
Other brief comments: