https://www.elilifland.com/. You can give me anonymous feedback here.
Posts
Wiki Contributions
Comments
I think 356 or more people in the population needed to make there be a >5% of 2+ deaths in a 2 month span from that population
[cross-posting from blog]
I made a spreadsheet for forecasting the 10th/50th/90th percentile for how you think GPT-4.5 will do on various benchmarks (given 6 months after the release to allow for actually being applied to the benchmark, and post-training enhancements). Copy it here to register your forecasts.
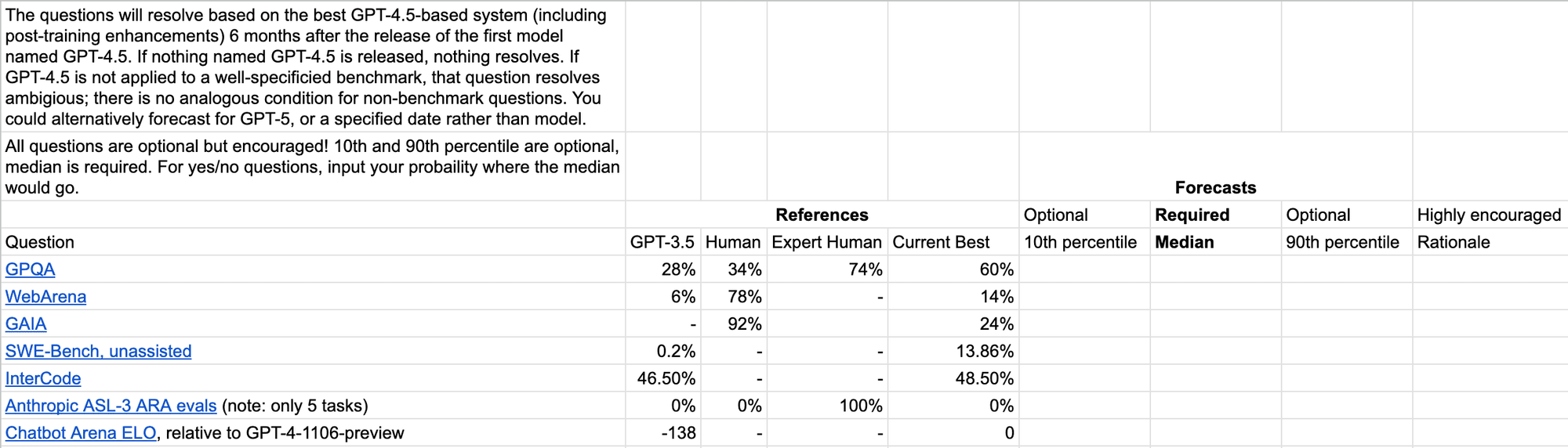
If you’d prefer, you could also use it to predict for GPT-5, or for the state-of-the-art at a certain time e.g. end of 2024 (my predictions would be pretty similar for GPT-4.5, and end of 2024).
You can see my forecasts made with ~2 hours of total effort on Feb 17 in this sheet; I won’t describe them further here in order to avoid anchoring.
There might be a similar tournament on Metaculus soon, but not sure on the timeline for that (and spreadsheet might be lower friction). If someone wants to take the time to make a form for predicting, tracking and resolving the forecasts, be my guest and I’ll link it here.
This is indeed close enough to Epoch's median estimate of 7.7e25 FLOPs for Gemini Ultra 1.0 (this doc cites an Epoch estimate of around 9e25 FLOPs).
FYI at the time that doc was created, Epoch had 9e25. Now the notebook says 7.7e25 but their webpage says 5e25. Will ask them about it.
Interesting, thanks for clarifying. It's not clear to me that this is the right primary frame to think about what would happen, as opposed to just thinking first about how big compute bottlenecks are and then adjusting the research pace for that (and then accounting for diminishing returns to more research).
I think a combination of both perspectives is best, as the argument in your favor for your frame is that there will be some low-hanging fruit from changing your workflow to adapt to the new cognitive labor.
Physical bottlenecks still exist, but is it really that implausible that the capabilities workforce would stumble upon huge algorithmic efficiency improvements? Recall that current algorithms are much less efficient than the human brain. There's lots of room to go.
I don't understand the reasoning here. It seems like you're saying "Well, there might be compute bottlenecks, but we have so much room left to go in algorithmic improvements!" But the room to improve point is already the case right now, and seems orthogonal to the compute bottlenecks point.
E.g. if compute bottlenecks are theoretically enough to turn the 5x cognitive labor into only 1.1x overall research productivity, it will still be the case that there is lots of room for improvement but the point doesn't really matter as research productivity hasn't sped up much. So to argue that the situation has changed dramatically you need to argue something about how big of a deal the compute bottlenecks will in fact be.
Imagine the current AGI capabilities employee's typical work day. Now imagine they had an army of AI assisstants that can very quickly do 10 hours worth of their own labor. How much more productive is that employee compared to their current state? I'd guess at least 5x. See section 6 of Tom Davidson's takeoff speeds framework for a model.
Can you elaborate how you're translating 10-hour AI assistants into a 5x speedup using Tom's CES model?
I agree that <15% seems too low for most reasonable definitions of 1-10 hours and the singularity. But I'd guess I'm more sympathetic than you, depending on the definitions Nathan had in mind.
I think both of the phrases "AI capable doing tasks that took 1-10 hours" and "hit the singularity" are underdefined and making them more clear could lead to significantly different probabilities here.
- For "capable of doing tasks that took 1-10 hours in 2024":
- If we're saying that "AI can do every cognitive task that takes a human 1-10 hours in 2024 as well as (edit: the best)
ahuman expert", I agree it's pretty clear we're getting extremely fast progress at that point not least because AI will be able to do the vast majority of tasks that take much longer than that by the time it can do all of 1-10 hour tasks. - However, if we're using a weaker definition like the one Richard used on most cognitive tasks, it beats most human experts who are given 1-10 hours to perform the task, I think it's much less clear due to human interaction bottlenecks.
- Also, it seems like the distribution of relevant cognitive tasks that you care about changes a lot on different time horizons, which further complicates things.
- If we're saying that "AI can do every cognitive task that takes a human 1-10 hours in 2024 as well as (edit: the best)
- Re: "hit the singularity", I think in general there's little agreement on a good definition here e.g. the definition in Tom's report is based on doubling time of "effective compute in 2022-FLOP" shortening after "full automation", which I think is unclear what it corresponds to in terms of real-world impact as I think both of these terms are also underdefined/hard to translate into actual capability and impact metrics.
I would be curious to hear the definitions you and Nathan had in mind regarding these terms.
In his AI Insight Forum statement, Andrew Ng puts 1% on "This rogue AI system gains the ability (perhaps access to nuclear weapons, or skill at manipulating people into using such weapons) to wipe out humanity" in the next 100 years (conditional on a rogue AI system that doesn't go unchecked by other AI systems existing). And overall 1 in 10 million of AI causing extinction in the next 100 years.
Among existing alignment research agendas/projects, Superalignment has the highest expected value
The word "overconfident" seems overloaded. Here are some things I think that people sometimes mean when they say someone is overconfident:
How much does this overloading matter? I'm not sure, but one worry is that it allows people to score cheap rhetorical points by claiming someone else is overconfident when in practice they might mean something like "your probability distribution is wrong in some way". Beware of accusing someone of overconfidence without being more specific about what you mean.