Jaynes references Polya's books on the role of plausible reasoning in mathematical investigations. The three volumes are How to Solve it, and two volumes of Mathematics and Plausible Reasoning. They are all really fun and interesting books which kind of give a glimpse of the cognitive processes of a successful mathematician.
Particularly relevant to Jaynes' discussion of weak syllogisms and plausibility is a section of Vol. 2 of Mathematics and Plausible Reasoning which gives many other kinds of weak syllogisms. Things like: "A is analogous to B, B ...
EDIT: The original post now has updated times and links, so refer to that instead.
Here are links to the times suggested, for convenience:
I'd suggest posting meeting times using timeanddate.com, to help avoid confusion about time zones and daylight savings.
From the preface:
We fail to present as many practical worked-out numerical examples as we should. Fortunately, three recent books largely make up this deficiency, and should be considered as adjuncts to the present work: Bayesian Spectrum Analysis and Parameter Estimation (Bretthorst, 1988), Maximum Entropy in Action (Buck and Macaulay, 1991), and Data Analysis – A Bayesian Tutorial (Sivia, 1996)
Which of these (or some other, more current, text) would you recommend?
This might be of interest to people here; it's an example of a genuine confusion over probability that came up in a friends medical research today. It's not particularly complicated, but I guess it's nice to link these things to reality.
My friend is a medical doctor and, as part of a PhD, he is testing peoples sense of smell. He asked if I would take part in a preliminary experiment to help him get to grips with the experimental details.
At the start of the experiment, he places 20 compounds in front of you, 10 of which are type A and 10 of which are type B...
I wish Lesswrong had an online book discussion section. How come we only analyze HPMoR in depth?
In the spreadsheet, Finland has GMT +2. Does Finland not observe daylight savings time? I thought Finland wasn't in the CET zone? If I'm correct, Finland should be GMT +3
The meeting times should maybe be in UTC, the current ones are a bit confusing, since the city choice is a bit arbitrary. I don't even think the Paris and Melbourne times match, since Melbourne is currently on daylight saving time and Paris is not.
Questions for the first part of Chapter 1:
(If you can think of other/better questions, please ask away!)
Book Club Update
As promised, this is a "minor" update, i.e. I'm not making a new top-level post to prompt new reading for this week, but sticking to a comment. We have new information on meeting times, and new chunks to read. Next week we will start on Chapter 2, this time with a top-level update. We'll see how this works.
New live meeting schedule
The spreadsheet has proven effective as a way to coordinate meeting times for widely scattered participants starting from suboptimal initial values. The most voted-on time is UTC+18 which is around 1pm i...
I was on the LessWrong IRC just after 1pm PST (PDT? Whatever time my clock is set for, which should be the same as in San Francisco) and stayed there for about an hour, but no one was there discussing the book.
Does this time not work for people in the area? Or did people not expect to start the live discussions until next week? Did people in different areas have similar or different experiences to this?
In the section on 'Common Language vs Formal Logic', he mentions the two propositions
and says the former is epistemological while the latter is ontological. Can anyone explain why this how this is the case? I can't make out the distinction at all, and infact parse the former as the latter.
Thanks for point out the Pattern paper. I used to be a member of the group pictured on page 11 (NYC design patterns study group), recognize some of the faces ;)
Can someone a little more fluent in boolean algebra post the transformation that gets you from (1-8) to (1-9) (pg 107-108 in the pdf)? I haven't been able to work it out.
This post summarizes response to the Less Wrong Book Club and Study Group proposal, floats a tentative virtual meetup schedule, and offers some mechanisms for keeping up to date with the group's work. We end with summaries of Chapter 1.
Statistics
The proposal for a LW book club and study group, initially focusing on E.T. Jaynes' Probability Theory: The Logic of Science (a.k.a. PT:TLOS), drew an impressive response with 57 declarations of intent to participate. (I may have missed some or misinterpreted as intending to participate some who were merely interested. This spreadsheet contains participant data and can be edited by anyone (under revision control). Please feel free to add, remove or change your information.) The group has people from no less than 11 different countries, in time zones ranging from GMT-7 to GMT+10.
Live discussion schedule and venues
Many participants have expressed an interest in having informal or chatty discussions over a less permanent medium than LW itself, which should probably be reserved for more careful observations. The schedule below is offered as a basis for further negotiation. You can edit the spreadsheet linked above with your preferred times, and by the next iteration if a different clustering emerges I will report on that.
The unofficial Less Wrong IRC channel is the preferred venue. An experimental Google Wave has also been started which may be a useful adjunct, in particular as we come to need mathematical notations in our discussions.
I recommend reading the suggested material before attending live discussion sessions.
Objectives, math prerequisites
The intent of the group is to engage in "earnest study of the great literature in our area of interest" (to paraphrase from the Knowledge Hydrant pattern language, a useful resource for study groups).
Earnest study aims at understanding a work deeply. Probably (particularly so in the case of PT:TLOS) the most useful way to do so is sequentially, in the order the author presented their ideas. Therefore, we aim for a pace that allows participants to extract as much insight as possible from each piece of the work, before moving on to the next, which is assumed to build on it.
Exercises are useful stopping-points to check for understanding. When the text contains equations or proofs, reproducing the derivations or checking the calculations can also be a good way to ensure deep understanding.
PT:TLOS is (from personal experience) relatively accessible on rusty high school math (in particular requires little calculus) until at least partway through Chapter 6 (which is where I am at the moment). Just these few chapters contain many key insights about the Bayesian view of probability and are well worth the effort.
Format
My proposal for the format is as follows. I will post one new top-level post per chapter, so as to give people following through RSS a chance to catch updates. Each chapter, however, may require splitting up into more than one chunk to be manageable. I intend to aim for a weekly rhythm: the monday after the first chunk of a new chapter is posted, I will post the next chunk, and so on. If you're worried about missing an update, check the top-level post for the current chapter weekly on mondays.
Each update will identify the current chunk, and will link to a comment containing one or more "opening questions" to jump-start discussion.
Updates also briefly summarize the previous chunk and highlights of the discussion arising from it. (Participants in the live chat sessions are encouraged to designate one person to summarize the discussion and post the summary as a comment.) By the time a new chapter is to be opened, the previous post will contain a digest form of the group's collective take on the chapter just worked through. The cumulative effect will be a "Less Wrong's notes on PT:TLOS", useful in itself for newcomers.
Chapter 1: Plausible Reasoning
In this chapter Jaynes fleshes out a theme introduced in the preface: "Probability theory as extended logic".
Sections: Deductive and Plausible Reasoning - Analogies with Physical Theories - The Thinking Computer - Introducing the Robot (week of 14/06)
Classical (Aristotelian) logic - modus ponens, modus tollens - allows deduction (teasing apart the concepts of deduction, induction, abduction isn't trivial). But what if we're interested not just in "definitely true or false" but "is this plausible", as we are in the kind of everyday thinking Jaynes provides examples of? Plausible reasoning is a weaker form of inference than deduction, but one Jaynes argues plays an important role even in (say) mathematics.
Jaynes' aim is to construct a working model of our faculty of "common sense", in the same sense that the Wright brothers could form a working model of the faculty of flight, not by vague resort to analogy as in the Icarus myth, but by producing a machine embodying a precise understanding. (Jaynes, however, speaks favorably of analogical thinking: "Good mathematicians see analogies between theorems; great mathematicians seen analogies between analogies". He acknowledges that this line of argument itself stems from analogy with physics.)
Accordingly, Jaynes frames what is to follow as building an "inference robot". Jaynes notes, "the question of the reasoning process used by actual human brains is charged with emotion and grotesque misunderstandings", and so this frame will be helpful in keeping us focused on useful questions with observable consequences. It is tempting to also read a practical intent - just as robots can carry out specialized mechanical tasks on behalf of humans, so could an inference robot keep track of more details than our unaided common senses - we must however be careful not to project onto Jaynes some conception of a "Bayesian AI".
Sections: Boolean Algebra - Adequate Sets of Operations - The Basic Desiderata - Comments - Common Language vs Formal Logic - Nitpicking (week of 21/06)
Jaynes next introduces the familiar formal notation of Boolean algebra to represent truth-values of propositions, their conjunction and disjunction, and denial. (Equality denotes equality of truth-values, rather than equality of propositions.) Some care is required to distinguish common usage of terms such as "or", "implies", "if", etc. from their denotation in the Boolean algebra of truth-values. From the axioms of idempotence, commutativity, associativity, distributivity and duality, we can build up any number of more sophisticated consequences.
One such consequence, sketched out next, is that any function of n boolean variables can be expressed as a sum (logical OR) involving only conjunctions (logical AND) of each variable or its negation. Each of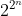 different logic functions can thus be expressed in terms of only
different logic functions can thus be expressed in terms of only 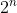 building blocks and only three operations (conjunction, disjunction, negation). In fact an even smaller set of operations is adequate to construct all Boolean functions: it is possible to express all three in terms of the NAND (negation of AND) operation, for instance. (A key argument in Chapter 2 hinges on this reduction of logic functions to an "adequate set".)
building blocks and only three operations (conjunction, disjunction, negation). In fact an even smaller set of operations is adequate to construct all Boolean functions: it is possible to express all three in terms of the NAND (negation of AND) operation, for instance. (A key argument in Chapter 2 hinges on this reduction of logic functions to an "adequate set".)
The "inference robot", then, is to reason in terms of degrees of plausibility assigned to propositions: plausibility is a generalization of truth-value. We are generally concerned with "conditional probability"; how plausible something is given what else we know. This is represented in the familiar notation A|B (" the plausibility of A given that B is true", or "A given B"). The robot is assumed to be provided sensible, non-contradictory input.
Jaynes next considers the "basic desiderata" for such an extension. First, they should be real numbers. (This is motivated by an appeal to convenience of implementation; the Comments defend this in greater detail, and a more formal justification can be found in the Appendices.) By convention, greater plausibility will be represented with a greater number, and the robot's "sense of direction", that is, the consequences it draws from increases or decreases in the plausibility of the "givens", must conform to common sense. (This will play a key role in Chapter 2.) Finally, the robot is to be consistent and non-ideological: it must always draw the same conclusions from identical premises, it must not arbitrarily ignore information available to it, and it must represent equivalent states of knowledge by equivalent values of plausibility.
(The Comments section is well worth reading, as it introduces the Mind Projection Fallacy which LW readers who have gone through the Sequences should be familiar with.)