I'm not sure that scientific talent is the relevant variable here. More talented folk are more likely to achieve both positive and negative outcomes.
Let's assume that all the other variables are already optimized for to minimize the risk of creating an UFAI. It seems to me that the the relationship between the ability level of the FAI team and probabilities of the possible outcomes must then look something like this:
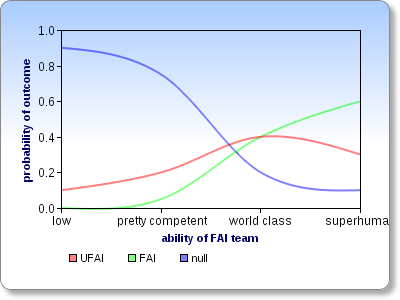
This chart isn't meant to communicate my actual estimates of the probabilities and crossover points, but just the overall shapes of the curves. Do you disagree with them? (If you want to draw your own version, click here and then click on "Modify This Chart".)
Folk do try to estimate and reduce the risks you mentioned, and to investigate alternative non-FAI interventions.
Has anyone posted SIAI's estimates of those risks?
I would also worry that signalling issues with a diverse external audience can hinder accurate discussion of important topics
That seems reasonable, and given that I'm more interested in the "strategic" as opposed to "tactical" reasoning within SIAI, I'd be happy for it to be communicated through some other means.
I like this chart.
Today I was appointed the new Executive Director of Singularity Institute.
Because I care about transparency, one of my first projects as an intern was to begin work on the organization's first Strategic Plan. I researched how to write a strategic plan, tracked down the strategic plans of similar organizations, and met with each staff member, progressively iterating the document until it was something everyone could get behind.
I quickly learned why there isn't more of this kind of thing: transparency is a lot of work! 100+ hours of work later, plus dozens of hours from others, and the strategic plan was finally finished and ratified by the board. It doesn't accomplish much by itself, but it's one important stepping stone in building an organization that is more productive, more trusted, and more likely to help solve the world's biggest problems.
I spent two months as a researcher, and was then appointed Executive Director.
In further pursuit of transparency, I'd like to answer (on video) submitted questions from the Less Wrong community just as Eliezer did two years ago.
The Rules
1) One question per comment (to allow voting to carry more information about people's preferences).
2) Try to be as clear and concise as possible. If your question can't be condensed into one paragraph, you should probably ask in a separate post. Make sure you have an actual question somewhere in there (you can bold it to make it easier to scan).
3) I will generally answer the top-voted questions, but will skip some of them. I will tend to select questions about Singularity Institute as an organization, not about the technical details of some bit of research. You can read some of the details of the Friendly AI research program in my interview with Michael Anissimov.
4) If you reference certain things that are online in your question, provide a link.
5) This thread will be open to questions and votes for 7 days, at which time I will decide which questions to begin recording video responses for.
I might respond to certain questions within the comments thread and not on video; for example, when there is a one-word answer.