Suppose further that you can quantify each item on that list with a function from world-histories to real numbers, and you want to optimize for each function, all other things being equal.
If fairness is one of my values, it can't necessary be represented by such a function. (I.e., it may need to be a function from lotteries over world-histories to real numbers.)
What the theorem says is that if you really care about the values on that list, then there are linear aggregations that you should start optimizing for.
I think before you make this conclusion, you have to say something about how one is supposed to pick the weights. The theorem itself seems to suggest that I can pick the weights by choosing a Pareto-optimal policy/outcome that's mutually acceptable to all of my values, and then work backwards to a set of weights that would generate a utility function (or more generally, a way to pick such weights based on a coin-flip) that would then end up optimizing for the same outcome. But in this case, it seems to me that all of the real "optimizing" was already done prior to the time you form the linear aggregation.
(ETA: I guess the key question here is whether the weights ought to logically depend on the actual shape of the Pareto frontier. If yes, then you have to compute the Pareto frontier before you choose the weights, in which case you've already "optimized" prior to choosing the weights, since computing the Pareto frontier involves optimizing against the individual values as separate utility functions.)
Also, even if my values can theoretically be represented by functions from world-histories to real numbers, I can't obtain encodings of such functions since I don't have introspective access to my values, and therefore I can't compute linear aggregations of them. So I don't know how I can start optimizing for a linear aggregation of my values, even if I did have a reasonable way to derive the weights.
If you're capable of making precommitments and we don't worry about computational difficulties [...]
I'm glad you made these assumptions explicit, but shouldn't there be a similar caveat when you make the final conclusions? The way I see it, I have a choice between (A) a solution known to be optimal along some dimensions not including considerations of logical uncertainty and dynamical consistency, or (B) a very imperfectly optimized solution that nevertheless probably does take them into account to some degree (i.e., the native decision making machinery that evolution gave me). Sticking with B for now doesn't seem unreasonable to me (especially given the other difficulties I mentioned with trying to implement A).
(I've skipped some of the supporting arguments in this comment since I already wrote about them under the recent Harsanyi post. Let me know if you want me clarify anything.)
I guess the key question here is whether the weights ought to logically depend on the actual shape of the Pareto frontier.
Yes, whether a set of weights leads to Pareto-dominance depends logically on the shape of the Pareto frontier. So the theorem does not help with the computational part of figuring out what one's values are.
...I have a choice between (A) a solution known to be optimal along some dimensions not including considerations of logical uncertainty and dynamical consistency, or (B) a very imperfectly optimized solution that nevertheless probab
Restatement of: If you don't know the name of the game, just tell me what I mean to you. Alternative to: Why you must maximize expected utility. Related to: Harsanyi's Social Aggregation Theorem.
Summary: This article describes a theorem, previously described by Stuart Armstrong, that tells you to maximize the expectation of a linear aggregation of your values. Unlike the von Neumann-Morgenstern theorem, this theorem gives you a reason to behave rationally.1
The von Neumann-Morgenstern theorem is great, but it is descriptive rather than prescriptive. It tells you that if you obey four axioms, then you are an optimizer. (Let us call an "optimizer" any agent that always chooses an action that maximizes the expected value of some function of outcomes.) But you are a human and you don't obey the axioms; the VNM theorem doesn't say anything about you.
There are Dutch-book theorems that give us reason to want to obey the four VNM axioms: E.g., if we violate the axiom of transitivity, then we can be money-pumped, and we don't want that; therefore we shouldn't want to violate the axiom of transitivity. The VNM theorem is somewhat helpful here: It tells us that the only way to obey the four axioms is to be an optimizer.2
So now you have a reason to become an optimizer. But there are an infinitude of decision-theoretic utility functions3 to adopt — which, if any, ought you adopt? And there is an even bigger problem: If you are not already an optimizer, than any utility function that you're considering will recommend actions that run counter to your preferences!
To give a silly example, suppose you'd rather be an astronaut when you grow up than a mermaid, and you'd rather be a dinosaur than an astronaut, and you'd rather be a mermaid than a dinosaur. You have circular preferences. There's a decision-theoretic utility function that says
$\mbox{mermaid} \prec \mbox{astronaut} \prec \mbox{dinosaur}$which preserves some of your preferences, but if you have to choose between being a mermaid and being a dinosaur, it will tell you to become a dinosaur, even though you really really want to choose the mermaid. There's another decision-theoretic utility function that will tell you to pass up being a dinosaur in favor of being an astronaut even though you really really don't want to. Not being an optimizer means that any rational decision theory will tell you to do things you don't want to do.
So why would you ever want to be an optimizer? What theorem could possibly convince you to become one?
Stuart Armstrong's theorem
Suppose there is a set (for "policies") and some functions
(for "policies") and some functions 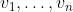 ("values") from
("values") from  to
to 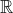 . We want these functions to satisfy the following convexity property:
. We want these functions to satisfy the following convexity property:
For any policies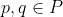 and any
and any 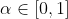 , there is a policy
, there is a policy 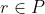 such that for all
such that for all 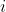 , we have
, we have  = \alpha v_i(p) + (1 - \alpha) v_i(q)) .
.
For policies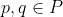 , say that
, say that 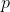 is a Pareto improvement over
is a Pareto improvement over 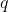 if for all
if for all 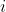 , we have
, we have  \geq v_i(q)) . Say that it is a strong Pareto improvement if in addition there is some
. Say that it is a strong Pareto improvement if in addition there is some 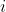 for which
for which  > v_i(q)) . Call
. Call 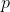 a Pareto optimum if no policy is a strong Pareto improvement over it.
a Pareto optimum if no policy is a strong Pareto improvement over it.
Theorem. Suppose and
and 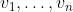 satisfy the convexity property. If a policy in
satisfy the convexity property. If a policy in  is a Pareto optimum, then it is a maximum of the function
is a Pareto optimum, then it is a maximum of the function 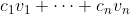 for some nonnegative constants
for some nonnegative constants 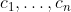 .
.
This theorem previously appeared in If you don't know the name of the game, just tell me what I mean to you. I don't know whether there is a source prior to that post that uses the hyperplane separation theorem to justify being an optimizer. The proof is basically the same as the proof for the complete class theorem and the hyperplane separation theorem and the second fundamental theorem of welfare economics. Harsanyi's utilitarian theorem has a similar conclusion, but it assumes that you already have a decision-theoretic utility function. The second fundamental theorem of welfare economics is virtually the same theorem, but it's interpreted in a different way.
What does the theorem mean?
Suppose you are a consequentialist who subscribes to Bayesian epistemology. And in violation of the VNM axioms, you are torn between multiple incompatible decision-theoretic utility functions. Suppose you can list all the things you care about, and the list looks like this:
Suppose further that you can quantify each item on that list with a function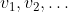 from world-histories to real numbers, and you want to optimize for each function, all other things being equal. E.g.,
from world-histories to real numbers, and you want to optimize for each function, all other things being equal. E.g., ) is large if
is large if  is a world-history where your welfare is great; and
is a world-history where your welfare is great; and ) somehow counts up the welfare of all mammals in world-history
somehow counts up the welfare of all mammals in world-history  . If the expected value of
. If the expected value of 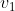 is at stake (but none of the other values are at stake), then you want to act so as to maximize the expected value of
is at stake (but none of the other values are at stake), then you want to act so as to maximize the expected value of 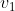 .4 And if only
.4 And if only 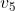 is at stake, you want to act so as to maximize the expected value of
is at stake, you want to act so as to maximize the expected value of 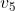 . What I've said so far doesn't specify what you do when you're forced to trade off value 1 against value 5.
. What I've said so far doesn't specify what you do when you're forced to trade off value 1 against value 5.
If you're VNM-rational, then you are an optimizer whose decision-theoretic utility function is a linear aggregation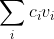 of your values and you just optimize for that function. (The
of your values and you just optimize for that function. (The 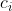 are nonnegative constants.) But suppose you make decisions in a way that does not optimize for any such aggregation.
are nonnegative constants.) But suppose you make decisions in a way that does not optimize for any such aggregation.
You will make many decisions throughout your life, depending on the observations you make and on random chance. If you're capable of making precommitments and we don't worry about computational difficulties, it is as if today you get to choose a policy for the rest of your life that specifies a distribution of actions for each sequence of observations you can make.5 Let be the set of all possible policies. If
be the set of all possible policies. If 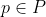 , and for any
, and for any 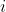 , let us say that
, let us say that ) is the expected value of
is the expected value of 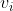 given that we adopt policy
given that we adopt policy 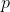 . Let's assume that these expected values are all finite. Note that if
. Let's assume that these expected values are all finite. Note that if 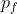 is a policy where you make every decision by maximizing a decision-theoretic utility function
is a policy where you make every decision by maximizing a decision-theoretic utility function 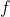 , then the policy
, then the policy 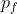 itself maximizes the expected value of
itself maximizes the expected value of 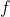 , compared to other policies.
, compared to other policies.
In order to apply the theorem, we must check that the convexity property holds. That's easy: If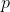 and
and 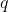 are two policies and
are two policies and 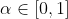 , the mixed policy where today you randomly choose policy
, the mixed policy where today you randomly choose policy 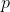 with probability
with probability  and policy
and policy 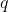 with probability
with probability 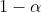 , is also a policy.
, is also a policy.
What the theorem says is that if you really care about the values on that list (and the other assumptions in this post hold), then there are linear aggregations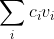 that you have reason to start optimizing for. That is, there are a set of linear aggregations and if you choose one of them and start optimizing for it, you will get more expected welfare for yourself, more expected welfare for others, less risk of the fall of civilization, ....
that you have reason to start optimizing for. That is, there are a set of linear aggregations and if you choose one of them and start optimizing for it, you will get more expected welfare for yourself, more expected welfare for others, less risk of the fall of civilization, ....
Adopting one of these decision-theoretic utility functions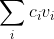 in the sense that doing so will get you more of the things you value without sacrificing any of them.
in the sense that doing so will get you more of the things you value without sacrificing any of them.
What's more, once you've chosen a linear aggregation, optimizing for it is easy. The ratio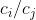 is a price at which you should be willing to trade off value
is a price at which you should be willing to trade off value 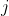 against value
against value 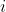 . E.g., a particular hour of your time should be worth some number of marginal dollars to you.
. E.g., a particular hour of your time should be worth some number of marginal dollars to you.
Addendum: Wei_Dai and other commenters point out that the set of decision-theoretic utility functions that will Pareto dominate your current policy very much depends on your beliefs. So a policy that seems Pareto dominant today will not have seemed Pareto dominant yesterday. It's not clear if you should use your current (posterior) beliefs for this purpose or your past (prior) beliefs.
More applications
There's a lot more that could be said about the applications of this theorem. Each of the following bullet points could be expanded into a post of its own:
1This post evolved out of discussions with Andrew Critch and Julia Galef. They are not responsible for any deficiencies in the content of this post. The theorem appeared previously in Stuart Armstrong's post If you don't know the name of the game, just tell me what I mean to you.
2That is, the VNM theorem says that being an optimizer is necessary for obeying the axioms. The easier-to-prove converse of the VNM theorem says that being an optimizer is sufficient.
3Decision-theoretic utility functions are completely unrelated to hedonistic utilitarianism.
4More specifically, if you have to choose between a bunch of actions and for all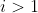 the expected value of
the expected value of 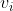 is independent of which actions you take, then you'll choose an action that maximizes the expected value of
is independent of which actions you take, then you'll choose an action that maximizes the expected value of 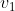 .
.
5We could formalize this by saying that for each sequence of observations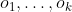 , the policy determines a distribution over the possible actions at time
, the policy determines a distribution over the possible actions at time 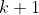 .
.