Remember that not only are the scales freely varying, but so are the zero-points. Any normalization scheme that doesn't take this into account won't work.
There is good reason to pay attention to scale but not to zero-points: any normalization scheme that you come up with will be invariant with respect to adding constants to the utility functions unless you intentionally contrive one not to be. Normalization schemes that are invariant with respect to multiplying the utility functions by positive constants are harder.
There is good reason to pay attention to scale but not to zero-points: any normalization scheme that you come up with will be invariant with respect to adding constants to the utility functions unless you intentionally contrive one not to be.
Making such modifications to the utilities of outcomes will result in distorted expected utilities and different behaviour.
(This is a (possibly perpetual) draft of some work that we (I) did at the Vancouver meetup. Thanks to my meetup buddies for letting me use their brains as supplementary computational substrate. Sorry about how ugly the LaTeX is; is there a way to make this all look a bit nicer?)
(Large swaths of this are obsolete. Thanks for the input, LW!)
The Problem of Decision Under Preference Uncertainty
Suppose you are uncertain whether it is good to eat meat or not. It could be OK, or it could be very bad, but having not done the thinking, you are uncertain. And yet you have to decide what to eat now; is it going to be the tasty hamburger or the morally pure vegetarian salad?
You have multiple theories about your preferences that contradict in their assessment, and you want to make the best decision. How would you decide, even in principle, when you have such uncertainty? This is the problem of Preference Uncertainty.
Preference Uncertainty is a daily fact of life for humans; we simply don't have introspective access to our raw preferences in many cases, but we still want to make the best decisions we can. Just going with our intuitions about what seems most awesome is usually sufficient, but on higher-stakes decisions and theoretical reasoning, we want formal methods with more transparent reasoning processes. We especially like transparent formal methods if we want to create a Friendly AI.
There is unfortunately very little formal analysis of the preference uncertainty problem, and what has been done is incomplete and more philosophical than formal. Nonetheless, there has been some good work in the last few years. I'll refer you to Crouch's thesis if you're interested in that.
Using VNM
I'm going to assume VNM. That is, that rational preferences imply a utility function, and we decide between lotteries, choosing the one with highest expected utility.
The implications here are that the possible moral theories (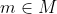 ) each have an associated utility function (
) each have an associated utility function (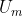 ) that represents their preferences. Also by VNM, our solution to preference uncertainty is a utility function
) that represents their preferences. Also by VNM, our solution to preference uncertainty is a utility function 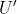 .
.
We are uncertain between moral theories, so we have a probability distribution over moral theories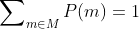 .
.
To make decisions, we need a way to compute the expected value of some lottery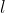 . Each lottery is essentially a probability distribution over the set of possible outcomes
. Each lottery is essentially a probability distribution over the set of possible outcomes 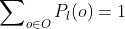 .
.
Since we have uncertainty over multiple things (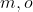 ), the domain of the final preference structure is both moral theories and outcomes:
), the domain of the final preference structure is both moral theories and outcomes: 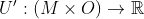 .
.
Now for some conditions. In the degenerate case of full confidence in one moral theory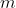 , the overall preferences should agree with that theory:
, the overall preferences should agree with that theory:
For some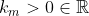 and
and 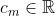 representing the degrees of freedom in utility function equality. That condition actually already contains most of the specification of
representing the degrees of freedom in utility function equality. That condition actually already contains most of the specification of 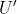 .
.
So we have a utility function, except for those unknown scaling and offset constants, which undo the arbitrariness in the basis and scale used to define each individual utility function.
Thus overall expectation looks like this:
This is still incomplete, though. If we want to get actual decisions, we need to pin down each and
and 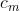 .
.
Offsets and Scales
You'll see above that the probability distribution over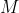 is not dependent on the particular lottery, while
is not dependent on the particular lottery, while 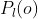 is a function of lottery. This is because I assumed that actions can't change what is right.
is a function of lottery. This is because I assumed that actions can't change what is right.
With this assumption, the contribution of the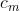 's can be entirely factored out:
's can be entirely factored out:
This makes it obvious that the effect of the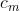 's is an additive constant that affects all lotteries the same way and thus never affects preferences. Thus we can set them to any value that is convenient; for this article, all
's is an additive constant that affects all lotteries the same way and thus never affects preferences. Thus we can set them to any value that is convenient; for this article, all 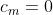 .
.
A similar process allows us to arbitrarily set exactly one of the .
.
The remaining values of actually affect decisions, so setting them arbitrarily has real consequences. To illustrate, consider the opening example of choosing lunch between a
actually affect decisions, so setting them arbitrarily has real consequences. To illustrate, consider the opening example of choosing lunch between a 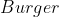 and
and 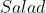 when unsure about the moral status of meat.
when unsure about the moral status of meat.
Making up some details, we might have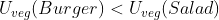 and
and 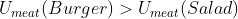 and
and 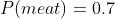 . Importing this into the framework described thus far, we might have the following payoff table:
. Importing this into the framework described thus far, we might have the following payoff table:
We can see that with those probabilities, the expected value of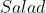 exceeds that of
exceeds that of 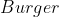 when
when 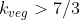 (when
(when 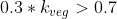 ), so the decision hinges on the value of that parameter.
), so the decision hinges on the value of that parameter.
The value of can be interpreted as the "intertheoretic weight" of a utility function candidate for the purposes of intertheoretic value comparisons.
can be interpreted as the "intertheoretic weight" of a utility function candidate for the purposes of intertheoretic value comparisons.
In general, if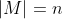 then you have exactly
then you have exactly  missing intertheoretic weights that determine how you respond to situations with preference uncertainty. These could be pinned down if you had
missing intertheoretic weights that determine how you respond to situations with preference uncertainty. These could be pinned down if you had  independent equations representing indifference scenarios.
independent equations representing indifference scenarios.
For example, if we had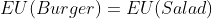 when
when 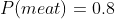 , then we would have
, then we would have 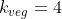 , and the above decision would be determined in favor of the
, and the above decision would be determined in favor of the 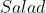 .
.
Expressing Arbitrary Preferences
Preferences are arbitrary, in the sense that we should be able to want whatever we want to want, so our mathematical constructions should not dictate or limit our preferences. If they do, we should just decide to disagree.
What that means here is that because the values of drive important preferences (like at what probability you feel it is safe to eat meat), the math must leave them unconstrained, to be selected by whatever moral reasoning process it is that selected the candidate utility functions and gave them probabilities in the first place.
drive important preferences (like at what probability you feel it is safe to eat meat), the math must leave them unconstrained, to be selected by whatever moral reasoning process it is that selected the candidate utility functions and gave them probabilities in the first place.
We could ignore this idea and attempt to use a "normalization" scheme to pin down the intertheoretic weights from the object level preferences without having to use additional moral reasoning. For example, we could dictate that the "variance" of each candidate utility function equals 1 (with some measure assignment over outcomes), which would divide out the arbitrary scales used to define the candidate utility functions, preventing dominance by arbitrary factors that shouldn't matter.
Consider that any given assignment of intertheoretic weights is equivalent to some set of indifference scenarios (like the one we used above for vegetarianism). For example, the above normalization scheme gives us the indifference scenario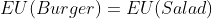 when
when 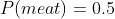 .
.
If I find that I am actually indifferent at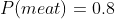 like above, then I'm out of luck, unable to express this very reasonable preference. On the other hand, I can simply reject the normalization scheme and keep my preferences intact, which I much prefer.
like above, then I'm out of luck, unable to express this very reasonable preference. On the other hand, I can simply reject the normalization scheme and keep my preferences intact, which I much prefer.
(Notice that the normalization scheme was an unjustifiably privileged hypothesis from the beginning; we didn't argue that it was necessary, we simply pulled it out of thin air for no reason, so its failure was predictable.)
Thus I reassert that the 's are free parameters to be set accordance with our actual intertheoretic preferences, on pain of stupidity. Consider an analogy to the move from ordinal to cardinal utilities; when you add risk, you need more degrees of freedom in your preferences to express how you might respond to that risk, and you need to actually think about what you want those values to be.
's are free parameters to be set accordance with our actual intertheoretic preferences, on pain of stupidity. Consider an analogy to the move from ordinal to cardinal utilities; when you add risk, you need more degrees of freedom in your preferences to express how you might respond to that risk, and you need to actually think about what you want those values to be.
Uncertainty Over Intertheoretic Weights
(This section is less solid than the others. Watch your step.)
A weakness in the constructions described so far is that they assume that we have access to perfect knowledge of intertheoretic preferences, even though the whole problem is that we are unable to find perfect knowledge of our preferences.
It seems intuitively that we could have a probability distribution over each . If we do this, making decisions is not much complicated, I think; a simple expectation should still work.
. If we do this, making decisions is not much complicated, I think; a simple expectation should still work.
If expectation is the way, the expectation over can be factored out (by linearity or something). Thus in any given decision with fixed preference uncertainties, we can pretend to have perfect knowledge of
can be factored out (by linearity or something). Thus in any given decision with fixed preference uncertainties, we can pretend to have perfect knowledge of  .
.
Despite the seeming triviality of the above idea for dealing with uncertainty over , I haven't formalized it much. We'll see if I figure it out soon, but for now, it would be foolish to make too many assumptions about this. Thus the rest of this article still assumes perfect knowledge of
, I haven't formalized it much. We'll see if I figure it out soon, but for now, it would be foolish to make too many assumptions about this. Thus the rest of this article still assumes perfect knowledge of  , on the expectation that we can extend it later.
, on the expectation that we can extend it later.
Learning Values, Among Other Things
Strictly speaking, inference across the is-ought gap is not valid, but we do it every time we act on our moral intuitions, which are just physical facts about our minds. Strictly speaking, inferring future events from past observations (induction) is not valid either, but it doesn't bother us much:
We deal with induction by defining an arbitrary (but good-seeming, on reflection) prior joint probability distribution over observations and events. We can handle the is-ought gap the same way: instead of separate probability distributions over events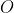 and moral facts
and moral facts 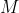 , we define a joint prior over
, we define a joint prior over 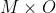 . Then learning value is just Bayesian updates on partial observations of
. Then learning value is just Bayesian updates on partial observations of 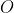 . Note that this prior subsumes induction.
. Note that this prior subsumes induction.
Making decisions is still just maximizing expected utility with our constructions from above, though we will have to be careful to make sure that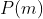 remains independent of the particular lottery.
remains independent of the particular lottery.
The problem of how to define such a prior is beyond the scope of this article. I will note that this "moral prior" idea is the solid foundation on which to base Indirect Normativity schemes like Yudkowsky's CEV and Christiano's boxed philosopher. I will hopefully discuss this further in the future.
Recap
The problem was how to make decisions when you are uncertain about what your object-level preferences should be. To solve it, I assumed VNM, in particular that we have a set of possible utility functions, and we want to construct an overall utility function that does the right thing by those utility functions and their probabilities. The simple condition that the overall utility function should make the common sense choices in cases of moral certainty was sufficient to construct a utility function with a precise set of remaining degrees of freedom. The degrees of freedom being the intertheoretic weight and offset of each utility function candidate.
I showed that the offsets and an overall scale factor are superfluous, in the sense that they never affect the decision if we assume that actions don't affect what is desirable. The remaining intertheoretic weights do affect the decision, and I argued that they are critical to expressing whatever intertheoretic preferences we might want to have.
Uncertainty over intertheoretic weight seems tractable, but the details are still open.
I also mentioned that we can construct a joint distribution that allows us to embed value learning in normal Bayesian learning and induction. This "moral prior" would subsume induction and define how facts about the desirability of things could be inferred from physical observations like the opinions of moral philosophers. In particular, it would provide a solid foundation for Indirect Normativity schemes like CEV. The nature of this distribution is still open.
Open Questions
What are the details of how to deal with uncertainty over the intertheoretic weights? I am looking in particular for construction from an explicit set of reasonable assumptions like the above work, rather than simply pulling a method out of thin air unsupported.
What are the details of the Moral Prior? What is its nature? What implications does it have? What assumptions do we have to make to make it behave reasonably? How do we construct one that could be safely given to a superintelligence. This is going to be a lot of work.
I assumed that it is meaningful to assign probabilities over moral theories. Probability is closely tied up with utility, and probability over epiphenomena like preferences is especially difficult. It remains to be seen how much the framing here actually helps us, or if it effectively just disguises pulling a utility function out of a hat.
Is this at all correct? I should build it and see if it type-checks and does what it's supposed to do.