I'm going to commit a social faux pas and respond to my own comment, because multiple subthreads are all saying essentially the same thing: this is just math, the theory is known, humans can already do it (often with some help from computers to get through the math).
As I've read it, one of the major takeaways of lesswrong is that AI is not magical. If humans cannot possibly figure out the theory, neither can an AI. If humans cannot possibly do the math (possibly with some help from a computer), neither can an AI. Anything an AI can do, a human can also do in principle. They differ only in the degree: AIs will eventually be able to do much more complicated math, solve much more complicated problems, and self-improve much faster and more reliably.
So if you look at my original suggestion and think "that's nothing special, a human can do that in theory" then you're completely correct. Things humans can do IN THEORY are EXACTLY the things with which an AI can help.
Recently Luke Muelhauser posed the question, “Can noise have power?”, which basically asks whether randomization can ever be useful, or whether for every randomized algorithm there is a better deterministic algorithm. This question was posed in response to a debate between Eliezer Yudkowsky and Scott Aaronson, in which Eliezer contends that randomness (or, as he calls it, noise) can't ever be helpful, and Scott takes the opposing view. My goal in this essay is to present my own views on this question, as I feel many of them have not yet been brought up in discussion.
I'll spare the reader some suspense and say that I basically agree with Scott. I also don't think – as some others have suggested – that this debate can be chalked up to a dispute about the meaning of words. I really do think that Scott is getting at something important in the points he makes, which may be underappreciated by those without a background in a field such as learning theory or game theory.
Before I start, I'd like to point out that this is really a debate about Bayesianism in disguise. Suppose that you're a Bayesian, and you have a posterior distribution over the world, and a utility function, and you are contemplating two actions A and B, with expected utilities U(A) and U(B). Then randomly picking between A and B will have expected utility+U(B)}{2}) , and so in particular at least one of A and B must have higher expected utility than randomizing between them. One can extend this argument to show that, for a Bayesian, the best strategy is always deterministic. Scott in fact acknowledges this point, although in slightly different language:
, and so in particular at least one of A and B must have higher expected utility than randomizing between them. One can extend this argument to show that, for a Bayesian, the best strategy is always deterministic. Scott in fact acknowledges this point, although in slightly different language:
“Randomness provably never helps in average-case complexity (i.e., where you fix the probability distribution over inputs) -- since given any ensemble of strategies, by convexity there must be at least one deterministic strategy in the ensemble that does at least as well as the average.” -Scott Aaronson
I think this point is pretty iron-clad and I certainly don't wish to argue against it. Instead, I'd like to present several examples of scenarios where I will argue that randomness clearly is useful and necessary, and use this to argue that, at least in these scenarios, one should abandon a fully Bayesian stance. At the meta level, this essay is therefore an argument in favor of maintaining multiple paradigms (in the Kuhnian sense) with which to solve problems.
I will make four separate arguments, paralleling the four main ways in which one might argue for the adoption or dismissal of a paradigm:
Randomization is an appropriate tool in many concrete decision-making problems (game theory and Nash equilibria, indivisible goods, randomized controlled trials).
Worst case analyses (which typically lead to randomization) are often important from an engineering design perspective (modularity of software).
Random algorithms have important theoretical properties not shared by deterministic algorithms (P vs. BPP).
Thinking in terms of randomized constructions has solved many problems that would have been difficult or impossible without this perspective (probabilistic method, sampling algorithms).
1. Concrete usefulness
Two people are playing rock-paper-scissors. After a while one of them starts to lose on average. What should they do? Clearly randomizing will make them stop losing so they should probably do that. I want to contrast this with one of Eliezer's points, which, roughly, is, “clearly you should randomize if you're up against some adversarial superintelligence, but in this case we should label it as 'adversarial superintelligence' rather than worst case”. Many have taken this as evidence that Scott and Eliezer are really just arguing about the definition of words. I find it difficult to support this conclusion in light of the above rock-paper-scissors example: you don't need to be playing an adversarial superintelligence, you just need to be playing anyone who is better than you at rock-paper-scissors, which is a reasonably common occurrence.
A related situation shows up in many trade- and bargaining-related situations. For instances, suppose that I have a good that I value at $800, you value the same good at $1,000, but you only have $500 available to spend. We can still make a trade by agreeing that I will give you the good with probability 50%, in exchange for you paying me $450, leading us both to profit by $50 in expectation. This illustrates how randomness can be used to improve market liquidity. You might argue that we could have made the same trade without randomization by finding an event that we both agree has 50% subjective probability mass. But even if you are willing to do that, it is easy to see why another agent may not wish to --- they may not wish to divulge information about their beliefs, they may not trust you to accurately divulge your own beliefs, they may not even represent their beliefs as probabilities in the first place, etc. Since agents with these properties are fairly natural, it seems necessary to randomize unless one is willing to give up on profitable trading opportunities.
As yet another example of concrete usefulness, let us consider randomized controlled trials --- in other words, using randomness in an experimental design to ensure that we have a representative subset of a population in order to infer a particular causal mechanism. When it is possible to do so, randomization is an incredibly useful aspect of experimental design, freeing us to make strong inferences about the data that would be much more difficult or impossible to make with the same level of confidence without using randomization. For example, say that we want to know whether a job training program improves participants' earnings. If we separate our sample into a treatment and control group using randomization, and we find a real difference in earnings between the two, there is a strong case that the job training program is the reason for the difference in earnings. If we use any other method to separate the two groups, we run the risk that our method for separating treatment from control was correlated with some other factor that can explain a difference in earnings.
If we follow the “randomness never helps” mantra here, then presumably we should carefully model all of the possible confounding effects in order to make inferences about the main effect --- but often the purpose of experimentation is to better understand phenomena about which we currently know little, so that it is unreasonable to think that we can actually accurately model every possible confound in this way. In this situation, “randomness never helps” requires us to pretend to know the answer even in situations where we clearly do not, which seems to me to be problematic. This is despite the fact that there doesn't seem to be any "superintelligence" - or even intelligent adversary - involved in such situations.
2. Design properties
As noted in the introduction, if we know the probability distribution of the environment, then the optimal strategy is always deterministic (for now, I ignore the issue of whether finding this optimal strategy is feasible, since we are talking about whether randomness helps "in principle"). On the other hand, if we do not know the distribution of the environment, there can be good reasons to randomize, since this can help to "smooth out" potential unexpected structure (examples include randomized quicksort as well as certain load-balancing algorithms). In other words, if we want to argue that randomness shouldn't help, the most obvious alternative to using randomization would be to reason about the probability distribution of the environment, which seems to match what Eliezer has in mind, as far as I can tell. For instance, Eliezer says:
Note that reasoning about the probability distribution of the environment requires assuming a particular distribution in the first place. I want to argue that this is often bad from a software design perspective. First, software is supposed to be modular. By this, I mean that software should be broken into components that:
1. Have a clearly specified and verifiable input-output contract.
2. Are re-usable in a wide variety of situations (for the most part, if the input-output contract can only be satisfied in one instance ever then it isn't a very useful contract).
Pretty much everyone who works on software agrees with this. However, requiring that the inputs to a piece of software follow some probability distribution is the opposite of being modular. Why is this? First, it is impossible to verify from a single input whether the input contract is satisfied, since the contract is now over the distribution of inputs, rather than a single input. Second, requiring a certain distribution over inputs limits the software to the cases where the inputs actually follow that distribution (or a sufficiently similar distribution), thus greatly limiting the scope of applicability. Even worse, such a distributional requirement propagates backward through the entire system: if A calls B, which calls C, and C requires its inputs to follow a certain probability distribution, then B's contract will probably also have to call for a certain probability distribution over inputs (unless all inputs to C from B are generated without reference to B's inputs). On the other hand, software operating under worst-case analyses will (by definition) work regardless of input, and will not generate assumptions that propagate back to the rest of the system. Therefore it is important to be willing to adopt a worst-case perspective (or at the very least, something weaker than assuming a full distribution over inputs), at least in this instance. If one wants to argue that the randomness in this scenario is only useful practically but that something deterministic would "in principle" be better, then they would have to also argue that modularity of software is useful practically but something non-modular would "in principle" be better.
3. Theoretical Properties
The P vs. BPP question is the question of whether, whenever there is a polynomial-time randomized algorithm that behaves correctly on every individual input with probability 99.9999999999%, there is also a polynomial-time deterministic algorithm that behaves correctly on every input. If randomness was never useful, we would expect the answer to this question to be straightforwardly yes --- after all, whatever the random algorithm was doing, we should be able to improve upon it, and since a deterministic algorithm is either right or wrong, the only way to improve upon 99.9999999999% is to go all the way up to 100%. In reality, however, this is a long-standing open problem in complexity theory that is generally believed to be true, but which is far from proven.
This point was already raised by Scott in his original thread, but did not seem to gain much traction. Several people were suspicious of the fact that the randomized algorithm only had to work almost all of the time on each input, while the deterministic algorithm had to work all of the time on each input. I have several responses to this. The first, somewhat flippant, response, is that we could of course only require that the deterministic algorithm work almost all of the time for each input, as well; but a deterministic algorithm can only get the answer right or wrong, so “almost always” and “always” amount to the same thing for a determistic algorithm.
Secondly, let us consider what it should mean for an algorithm to work “for all practical purposes”. If I have a randomized algorithm, and its probability of failure is so small as to be negligible compared to, say, cosmic rays hitting the computer and corrupting the output, then this seems to meet the bar of “for all practical purposes” (thus motivating the definition of BPP). On the other hand, what should “all practical purposes” mean for a deterministic algorithm? Some might argue that if, on average across inputs to the algorithm, the output is very likely to be correct, then that should satisfy the requirement --- but this raises the question, what average should we use? An addition algorithm that thinks that 1+1=3 but is otherwise correct should surely not meet the “all practical purposes” bar, so the uniform distribution over inputs certainly shouldn't be used. So, perhaps I should be figuring out what I expect my input distribution to look like, and measure according to that? But now, you see, we have added baggage that wasn't in the original problem definition. All I said is that I had some abstract algorithmic problem that I wanted to solve for (some suitable definition of) all practical purposes. You've now told me that in order to do this, I need to figure out what the input distribution to the algorithm is going to be. But this is pretty unreasonable! Can you imagine an undergraduate computer science textbook full of algorithms that would work, but only if its inputs followed such-and-such a distribution? (I'm not claiming that such a guarantee is never useful, only disputing the notion that it should be raised up as the gold standard of algorithms on the same level as P and BPP.) I don't think anyone would learn much from such a textbook, and computer science would be in a pretty woeful state if this was all we could offer. I therefore contend that the only really reasonable notion of deterministically solving a problem for all practical purposes is that it should always work correctly on all possible inputs, thus leading to the complexity class P. This is all a long-winded way of saying that the P vs. BPP question really is the right way to formally ask whether randomness can help from an algorithmic standpoint.
I'd also like to specially examine what happens if we use a Solomonoff prior (assigning probability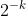 to programs of length k). If there is any program of length L that solves the problem correctly, then any deterministic algorithm of length M that is incorrect with probability much less than
to programs of length k). If there is any program of length L that solves the problem correctly, then any deterministic algorithm of length M that is incorrect with probability much less than 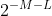 with respect to the Solomonoff prior must always work (since we can take the program that runs the two algorithms against each other until it finds a discrepancy, then uses that as the input). Therefore, “almost always” with respect to Solomonoff is more or less the same as “always”, so we haven't really done anything different than redefine P in a very roundabout way. Crucially, this means that even if we are fully Bayesian, under a Solomonoff prior the question of whether every randomized polynomial-time algorithm has a deterministic counterpart still boils down to the unresolved and deep P vs. BPP question.
with respect to the Solomonoff prior must always work (since we can take the program that runs the two algorithms against each other until it finds a discrepancy, then uses that as the input). Therefore, “almost always” with respect to Solomonoff is more or less the same as “always”, so we haven't really done anything different than redefine P in a very roundabout way. Crucially, this means that even if we are fully Bayesian, under a Solomonoff prior the question of whether every randomized polynomial-time algorithm has a deterministic counterpart still boils down to the unresolved and deep P vs. BPP question.
[Addendum: it looks like Peter de Blanc and Wei Dai have made this last point already, see here and here.)
4. Usefulness in problem-solving
There are important combinatorial properties, such as expansion properties of graphs, which are satisfied by random graphs but which we don't have any deterministic constructions for at all (or in some cases, we do, but they came much later and were harder to come by). Many important problems in graph theory, Ramsey theory, etc. were solved by considering random combinatorial objects (this was one of the great triumphs of Paul Erdos) and thinking in purely deterministic terms seems very unlikely to have solved these problems. Taking a random/pseudorandom perspective has even led to some of the modern triumphs of mathematics such as the Green-Tao theorem (there are arbitrarily long arithmetic progressions) and is fundamental to theoretical cryptography, game theory, convex analysis, and combinatorial approximation algorithms. If we abandon the use of random constructions, then we also abandon some of the most important work in modern computer science, economics, and applied mathematics, which seems unacceptable to me.
On the algorithmic side, even if you are Bayesian, you want to somehow represent your posterior distribution, and one of the simplest ways to do so is by random samples. An alternative way is by a probability density function, but under extremely widely held complexity-theoretic assumptions there are many probability distributions that can be efficiently represented by samples but whose probability density function cannot be efficiently written down. More practically, the view of representing distributions by random samples has led to many important algorithms such as sequential Monte Carlo (SMC) and Markov Chain Monte Carlo (MCMC), which form some of the cornerstones of modern statistical inference (MCMC in particular has been called one of the 10 greatest algorithms of the 20th century). Again, abandoning this work on philosophical grounds seems unacceptable.
Of course, it is theoretically possible that all of the above gains will eventually be reproduced without using randomness. However, it seems important to note that many of these are among the most beautiful and elegant results in their respective fields. I would object to any characterization of them as "hacks" that come down to a poorly-understood, lucky, but useful result.
The obstacles to "derandomizing" such things appear to be quite deep, as extremely intelligent people have been working on them for decades without success. If one wants to say that a randomization-free, Bayesian approach is "correct even if not practical," this becomes true for a very expansive definition of "practical," and one must concede that being a Bayesian is often completely impractical even when a great deal of time and resources are available for reasoning.
Thinking in terms of randomness is extremely useful in arriving at these deep and important results, and one of the main purposes of a paradigm is to provide modes of thought that lead to such results. I would therefore argue that randomization should be a fundamental lens (among many) with which to approach problems.
Conclusion
I have given several examples of how randomness is useful in both commonplace and fundamental ways. A possible objection is that yes, randomness might be useful from a pragmatic perspective, but it is still the case that in theory we can always do better without randomness. I don't think that such an objection answers the above arguments, except perhaps in some very weak sense. We saw how, in rock-paper-scissors, randomness is always going to be useful for one of the two players (unless both players are equally strong); we saw how using randomness is necessary to make certain profitable trades; and we saw how, even if we adopt a Solomonoff prior, the question of whether or not deterministic algorithms can compete with randomized algorithms is still open (and the likely resolution will rely upon constructing sufficiently pseudorandom numbers, rather than reasoning carefully about the distribution of inputs). Even if we discard all pragmatic concerns whatsoever, the above examples at the very least show that randomization is useful in a very deep and fundamental way. And importantly, at least from my perspective, we have also seen how randomization has been essential in resolving important problems across a variety of fields. This, if nothing else, is a compelling case that it should be adopted as a feature in one's worldview, rather than discarded on philosophical grounds.
Acknowledgements
Thanks to Holden Karnofsky for reading an early version of this essay and suggesting the randomized controlled trials example. Thanks also to Sindy Li for suggesting the idea of using randomness to improve market liquidity.