I'm going to lay out a specific scenario in which WBE arrives very soon, so that other things are not much changed. I'm assuming here that the scanning route starts with legal death and vitrification. I'm also assuming no hardware overhang - that initially, vast amounts of compute hardware are required, and WBEs are no faster than we are or perhaps slower. This and other assumptions I haven't noticed well enough to state add up to a large conjunction and so a correspondingly small spot in probability space, treat with appropriate caution.
The literal first people would be test subjects; people dying of something that doesn't affect the brain, who aren't signed up for cryonics but who are sympathetic enough to take a shot at immortality. I'm not sure what sort of fate to expect for these first volunteers, given that there are things we would like to know that it will be hard to learn from animal testing and it's difficult to get those things right first time.
Once the procedure has been demonstrated to work well in humans and preserve memory and personality, then the interesting questions start. Lots of people who aren't signed up for cryonics would sign up, even though WBE is far outside their budget, because they have good reason to hope that it will one day be affordable. In its initial stages, WBE will primarily be seen as a way of escaping terminal illness for the very rich. In places where euthanasia is legal, some who would otherwise have waited longer will opt for euthanasia followed by WBE. There may be cryonics patients today whose fortunes would cover WBE, they might also be brought back.
It's currently illegal to assist suicide in a healthy person even if you plan to cryopreserve them, and I don't expect that to change right away. The first healthy and rich person to arrange their own "suicide" in order to be uploaded will presumably generate lots of publicity and controversy.
In this scenario, three things then start to happen which make it much harder to see where things go next!
This is part of a weekly reading group on Nick Bostrom's book, Superintelligence. For more information about the group, and an index of posts so far see the announcement post. For the schedule of future topics, see MIRI's reading guide.
Welcome. This week we discuss the third section in the reading guide, AI & Whole Brain Emulation. This is about two possible routes to the development of superintelligence: the route of developing intelligent algorithms by hand, and the route of replicating a human brain in great detail.
This post summarizes the section, and offers a few relevant notes, and ideas for further investigation. My own thoughts and questions for discussion are in the comments.
There is no need to proceed in order through this post. Feel free to jump straight to the discussion. Where applicable, page numbers indicate the rough part of the chapter that is most related (not necessarily that the chapter is being cited for the specific claim).
Reading: “Artificial intelligence” and “Whole brain emulation” from Chapter 2 (p22-36)
Summary
Intro
Whole brain emulation
Notes
Bostrom and Müller's survey asked participants to compare various methods for producing synthetic and biologically inspired AI. They asked, 'in your opinion, what are the research approaches that might contribute the most to the development of such HLMI?” Selection was from a list, more than one selection possible. They report that the responses were very similar for the different groups surveyed, except that whole brain emulation got 0% in the TOP100 group (100 most cited authors in AI) but 46% in the AGI group (participants at Artificial General Intelligence conferences). Note that they are only asking about synthetic AI and brain emulations, not the other paths to superintelligence we will discuss next week.
Omohundro suggests advanced AIs will tend to have important instrumental goals in common, such as the desire to accumulate resources and the desire to not be killed.
Anthropic reasoning
‘We must avoid the error of inferring, from the fact that intelligent life evolved on Earth, that the evolutionary processes involved had a reasonably high prior probability of producing intelligence’ (p27)
Whether such inferences are valid is a topic of contention. For a book-length overview of the question, see Bostrom’s Anthropic Bias. I’ve written shorter (Ch 2) and even shorter summaries, which links to other relevant material. The Doomsday Argument and Sleeping Beauty Problem are closely related.
Whole Brain Emulation: A Roadmap is an extensive source on this, written in 2008. If that's a bit too much detail, Anders Sandberg (an author of the Roadmap) summarises in an entertaining (and much shorter) talk. More recently, Anders tried to predict when whole brain emulation would be feasible with a statistical model. Randal Koene and Ken Hayworth both recently spoke to Luke Muehlhauser about the Roadmap and what research projects would help with brain emulation now.
Levels of detail
As you may predict, the feasibility of brain emulation is not universally agreed upon. One contentious point is the degree of detail needed to emulate a human brain. For instance, you might just need the connections between neurons and some basic neuron models, or you might need to model the states of different membranes, or the concentrations of neurotransmitters. The Whole Brain Emulation Roadmap lists some possible levels of detail in figure 2 (the yellow ones were considered most plausible). Physicist Richard Jones argues that simulation of the molecular level would be needed, and that the project is infeasible.
Other problems with whole brain emulation
Sandberg considers many potential impediments here.
Order matters for brain emulation technologies (scanning, hardware, and modeling)
Bostrom points out that this order matters for how much warning we receive that brain emulations are about to arrive (p35). Order might also matter a lot to the social implications of brain emulations. Robin Hanson discusses this briefly here, and in this talk (starting at 30:50) and this paper discusses the issue.
What would happen after brain emulations were developed?
We will look more at this in Chapter 11 (weeks 17-19) as well as perhaps earlier, including what a brain emulation society might look like, how brain emulations might lead to superintelligence, and whether any of this is good.
Scanning (p30-36)

‘With a scanning tunneling microscope it is possible to ‘see’ individual atoms, which is a far higher resolution than needed...microscopy technology would need not just sufficient resolution but also sufficient throughput.’
Here are some atoms, neurons, and neuronal activity in a living larval zebrafish, and videos of various neural events.
Array tomography of mouse somatosensory cortex from Smithlab.
A molecule made from eight cesium and eight
iodine atoms (from here).
Efforts to map connections between neurons
Here is a 5m video about recent efforts, with many nice pictures. If you enjoy coloring in, you can take part in a gamified project to help map the brain's neural connections! Or you can just look at the pictures they made.
The C. elegans connectome (p34-35)
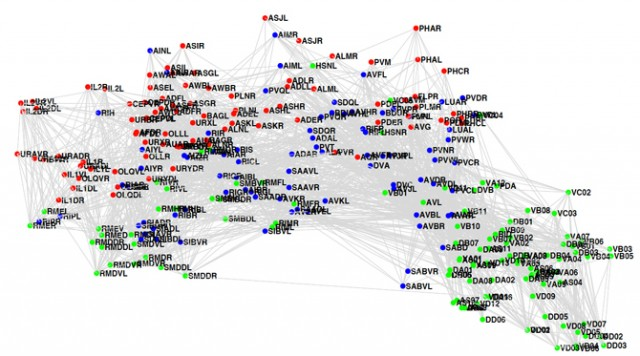
As Bostrom mentions, we already know how all of C. elegans’ neurons are connected. Here's a picture of it (via Sebastian Seung):
In-depth investigations
If you are particularly interested in these topics, and want to do further research, these are a few plausible directions, some taken from Luke Muehlhauser's list:
How to proceed
This has been a collection of notes on the chapter. The most important part of the reading group though is discussion, which is in the comments section. I pose some questions for you there, and I invite you to add your own. Please remember that this group contains a variety of levels of expertise: if a line of discussion seems too basic or too incomprehensible, look around for one that suits you better!
Next week, we will talk about other paths to the development of superintelligence: biological cognition, brain-computer interfaces, and organizations. To prepare, read Biological Cognition and the rest of Chapter 2. The discussion will go live at 6pm Pacific time next Monday 6 October. Sign up to be notified here.