In my small fourth grade class of 20 students, we are learning how to write essays, and get to pick our own thesis statements. One kid, who had a younger sibling, picked the thesis statement: "Being an older sibling is hard." Another kid did "Being the youngest child is hard." Yet another did "Being the middle child is hard", and someone else did "Being an only child is hard." I find this as a rather humorous example of how people often make it look like they're being oppressed.
Does anyone know why people do this?
Be charitable; don't assume they're trying to present themselves as martyrs. Instead they could be outlining the peculiar challenges and difficulties of their particular positions.
Life is hard for everyone at times.
Anybody should be able to write an essay "why my life is hard." They should also be able to write an essay "why my life is easy." It might be a great exercise to have every student write a second essay on a thesis which is essentially the opposite of the thesis of their first essay.
One kid, who had a younger sibling, picked the thesis statement: "Being an older sibling is hard." Another kid did "Being the youngest child is hard." Yet another did "Being the middle child is hard", and someone else did "Being an only child is hard." I find this as a rather humorous example of how people often make it look like they're being oppressed.
Taken at face value, the four statements aren't incompatible. Saying that being X is hard in an absolute sense isn't the same as saying that being X is harder than being Y in a relative sense, or that X people are being oppressed.
I would like to point out that this is the only comment in the thread that doesn't assume that this behavior is culturally invariant, and suggest that the rest of LW think about that for a while.
Since Eliezer has forsaken us in favor of posting on Facebook, can somebody with an account please link to his posts? His page cannot be read by someone who is not logged in, but individual posts can be read if the url is provided. As someone who abandoned his Facebook account years ago, I find this frustrarting.
Here's a month's worth:
https://www.facebook.com/yudkowsky/posts/10153041257924228
https://www.facebook.com/yudkowsky/posts/10153033570824228
https://www.facebook.com/yudkowsky/posts/10153030238814228
https://www.facebook.com/yudkowsky/posts/10153021749629228
https://www.facebook.com/yudkowsky/posts/10152977126839228
https://www.facebook.com/yudkowsky/posts/10152972605814228
https://www.facebook.com/yudkowsky/posts/10152972301299228
https://www.facebook.com/yudkowsky/posts/10152964087234228
https://www.facebook.com/yudkowsky/posts/10152957903859228
https://www.facebook.com/yudkowsky/posts/10152947952344228
https://www.facebook.com/yudkowsky/posts/10152946520029228
https://www.facebook.com/yudkowsky/posts/10152945423789228
https://www.facebook.com/yudkowsky/posts/10152941108249228
https://www.facebook.com/yudkowsky/posts/10152940624254228
https://www.facebook.com/yudkowsky/posts/10152938634304228
https://www.facebook.com/yudkowsky/posts/10152937953959228
https://www.facebook.com/yudkowsky/posts/10152933586294228
https://www.facebook.com/yudkowsky/posts/10152929868929228
https://www.facebook.com/yudkowsky/posts/10152919146569228
There seem to be some parents (and their children) here. I myself am the father of 3yo and 1yo daughters. Is there any suggestions you have for raising young rationalists, and getting them to enjoy critical, skeptical thinking without it backfiring from being forced on them?
Julia Galef, President and Co-founder of the Center for Applied Rationality, has video blogged on this twice. The first was How to Raise a Rationalist Kid, and the second is Wisdom from Our Mother, which might be a bit more relevant to you because, in that video, her brother Jesse specifically discusses what his mother did in situations where he wasn't enthusiastic about learning something. I should say that it has more to do with when your kids think that they're bad at things than with when they reject something out of hand. To that I would say, and I think many others would say: Kids are smart and curious, rationalism makes sense, and if they don't reject everything else kids have learned throughout history out of hand, then they probably won't reject rationalism out of hand.
I also am the father of 3yo and 1yo daughters. One of the things I try to do is let their critical thinking or rationality actually have a payoff in the real world. I think a lot of times critical thinking skills can be squashed by overly strict authority figures who do not take the child's reasoning into account when they make decisions. I try to give my daughters a chance to reason with me when we disagree on something, and will change my mind if they make a good point.
Another thing I try to do, is intentionally inject errors into what I say sometime, to make sure they are listening and paying attention. (e.g. This apple is purple, right? ) I think this helps to avoid them just automatically agreeing with parents/teachers and critically thinking through on their own what makes sense. Now my oldest is quick to call me out on any errors I may make when reading her stories, or talking in general, even when I didn't intentionally inject them.
Lastly, to help them learn in general, make their learning applicable to the real world. As an example, both of my daughters, when learning to count, got stuck at around 4. To help get them over that hurdle, I started asking them questions like, "How many fruit snacks do you want?" and then giving them that number. That quickly inspired them to learn bigger numbers.
[This isn't a direct response to Mark, but a reply to encourage more responses]
To add another helpful framing, if you don't have children, but think as an adult part of your attraction to LessWrong was based on how your parents raised you with an appreciation with rationality, how did that go? Obvious caveats about how memories of childhood are unreliable and fuzzy, and personal perspectives on how your parents raised you will be biased.
I was raised by secular parents, who didn't in particular put a special emphasis on rationality when raising me, compared to other parents. However, for example, Julia and Jesse Galef have written on their blog of how their father raised them with rationality in mind.
Something I frequently see from people defending free speech is some variant of the idea "in the marketplace of ideas, the good ones will win out". Is anyone familiar with any deeper examination of this idea? For instance, whether an idea market actually exists, how much it resembles a marketplace for goods, how it might reliably go wrong, etc.
I think you're better off looking into theories of memetics; that is, a marketplace doesn't seem to be as good an analogy as an ecology. That makes the somewhat less cheery argument that 'good' doesn't mean 'true' so much as 'effective at spreading,' and in particular memes can win by poisoning their competitors through allelopathy, just like an oak tree.
Recently, there has been talk of outlawing or greatly limiting encryption in Britain. Many people hypothesize that this is a deliberate attempt at shifting the overton window, in order to get a more reasonable sounding but still quite extreme law passed.
For anyone who would want to shift the overton window in the other direction, is there a position that is more extreme than "we should encrypt everything all the time" ?
Assuming you just want people throwing ideas at you:
Make it illegal to communicate in cleartext? Add mandatory cryptography classes to schools? Requiring everyone to register a public key and having a government key server? Not compensating identity theft victims and the like if they didn't use good security?
Frame attempts to limit the use of encryption as unilateral disarmament, and name specific threats.
As in, if the government "has your password", how sure are you that your password isn't eventually going to be stolen by Chinese government hackers? Putin? Estonian scammers? Terrorists? Your ex-partner? And you know that your allies over in (Germany, United States, Israel, France) are going to get their hands on it too, right? And have you thought about when (hated political party) gets voted into power 5 years from now?
A second good framing is used by the ACLU representative in the Guardian article: You won't be able to use technologies X Y and Z, and you'll fall behind other countries technologically and economically.
Just thought of something. If you want to talk about variation and selection but you can't say 'evolution' without someone flipping a table, then talk about animal husbandry instead.
EDIT: Heh, turns out Darwin actually did this.
At one point there was a significant amount of discussion regarding Modafinil - this seems to have died down in the past year or so. I'm curious whether any significant updating has occurred since then (based either on research or experiences.)
(This is a repost from last week's open thread due to many upvotes and few replies. However, see here for Gwern's response.)
I meant to post something about my experience with armodafinil about a year ago, but I never got around to it. My overall experience was strongly negative. Looks like I did write a long post in a text file a day or so after taking armodafinil, so here's what I had to say back then:
Some background:
I'm a white male in my mid-20s. I have excessive daytime sleepiness, and I believe this is because I'm a long sleeper who has difficulty getting an adequate duration of sleep. There are several long sleepers in my family. My mother and I tend to not like how stimulants make us feel, e.g., pseudoephedrine makes us fairly nervous, though it will help our nasal congestion from allergies and help wake us up. I was interested in trying modafinil because I hear it has proportionally less of the negative effects compared against its wake-promoting effects.
My neurologist gave me a few samples of armodafinil, which is basically a variant of modafinil. I was busy in the month after I met my neurologist last and didn't think about taking it at all, but come mid-February I remembered to try it.
Saturday, Feb. 15, 2014:
I woke up at 8:30 am, as I usually did, and started eating a chocolate chip muffin fo...
I just started using the Less Wrong Study Hall. It's been great! I find myself to be more productive, and there's something fun about being amongst the company of other friendly people.
I don't have anything insightful to say. I'd just like to reiterate that:
1) It exists and you should consider using it (it seems that not too many people know about it).
2) I (and others) think that there should be a link to it in the sidebar.
Tell us about your feed reader of choice.
I've been using Feedly since Google Reader went away, and has enough faults (buggy interface, terrible bookmarking, awkward phone app that needs to be online all the time) to motivate me towards a new one. Any recommendations?
We're looking for beta testers for the 16th "annual" Microsoft puzzle hunt. Interested folks should PM me, especially if you're in the Seattle area.
Uhm. this is an rather weird way to describe how I think.. but, I feel like I've come full-circle. I'm automatically thinking of ways to optimize, automatically try to better understand the world about me. I'm reading LW articles and I sometimes think "yeah, I know about this".. I no longer feel the "Aha! How did I not realize this seemingly obvious thing I should have thought of already that hurts me nerd always-be-right ego!" but rather, I read mid-post and just feel like I know this stuff already.
Naturally, I still am not 100% perfect, but I still think I'm on the right path. I've been mostly a lurker and registered not long ago. Has anyone else gotten the same feel? This feeling isn't really backed up by anything other than having a "I know this already" thought.
I have (what I presume to be) massive social anxiety. I live near lots of communities of interest that probably contain lots of people I would like to meet and spend time with, but the psychological "activation energy" required to go to social events and not leave halfway though is huge, and so I usually end up just staying at home. I would prefer to be out meeting people and doing things, but when I actually try to do this, I get overcome by anxiety (or something resembling it), and I need to leave. Has anyone else had this problem, and if so, w...
Hello! I'm working on a couple of papers that may be published soon. Before this happens, I'd be extremely curious to know what people think about them -- in particular, what people think about my critique of Bostrom's definition of "existential risks." A very short write-up of the ideas can be found at the link below. (If posting links is in any way discouraged here, I'll take it down right away. Still trying to figure out what the norms of conversation are in this forum!)
A few key ideas are: Bostrom's definition is problematic for two reasons: ...
How long do the effects of caffeine tolerance, where when you're not on caffeine you're below baseline and caffeine just brings you back to normal, last? If I took tolerance breaks inbetween stretches of caffeine use, could I be better off on average than if I simply avoided it entirely?
I think you are thinking about this the wrong way. People become caffeine tolerant quickly, but tolerance goes away pretty quickly too. You would get more benefit out of the opposite approach - spending most of your time without caffeine, but drinking a cup of coffee rarely, when you really need it. You would effectively be caffeine naive most of the time, with brief breaks for caffeine use, and this never develop much of a tolerance. If it's been a long time since that first cup of coffee that you don't remember it, trust me, the effects of caffeine on a caffeine-naive brain are incredible.
I know I once read a study that says you can get back to caffeine naive in two weeks if you go cold turkey, but I can't find anything on it again for the life of me. I do remember distinctly that going cold turkey is a bad plan, as the withdrawal effects are pretty unpleasant - slowly lowering your dose is better.
On a more practical level, it is certainly possible to have relatively little caffeine, such that you aren't noticeably impaired on zero caffeine, while still having some caffeine. The average coffee drinker is far beyond this point. I would try to lower your daily dose over the ...
Precommitting to a secret prediction which I'll reveal on April 15. MD5 hash for the prediction is 38bd807a6872f6a5622aa2b011fd8f03 .
Copy of JoshuaZ's SHA-1 hash as of 2015-01-20 18:06 GMT: f886dee5be3192819b3cd596cd73919f5c1e0a2c .
What makes teams more effective
It isn't the total IQ of the team, and whether they're working face to face doesn't matter.
The factors discovered were that the members make fairly equal contributions to discussions, level of emotional perceptiveness, and number of women, though part of the effect of number of women is partially explained by women tending to be emotionally perceptive.
On the one hand, I've learned to be skeptical of social science research-- and I add some extra skepticism for experiments that are simulations of the real world. In this case, ...
Didn't get a response in the last thread, so I'm asking again, a bit more generally.
I've recently been diagnosed with ADHD-PI. I'm wondering how to best use that information to my advantage, and am looking for resources that might help manage this. Does anyone have anything to recommend?
In the short-term I'm trying to lower barriers for things like actually eating by preparing snacks in snaplock bags, printing out and laminating checklists to remind me of basic tasks, and finding more ways to get instant feedback on progress in as many areas as I can (for coding, this means test-driven development).
I've never studied any branch of ethics, maybe stumbling across something on Wikipedia now and then. Would I be out of my depth reading a metaethics textbook without having read books about the other branches of ethics? It also looks like logic must play a significant role in metaethics given its purpose, so in that regard I should say that I'm going through Lepore's Meaning and Argument right now.
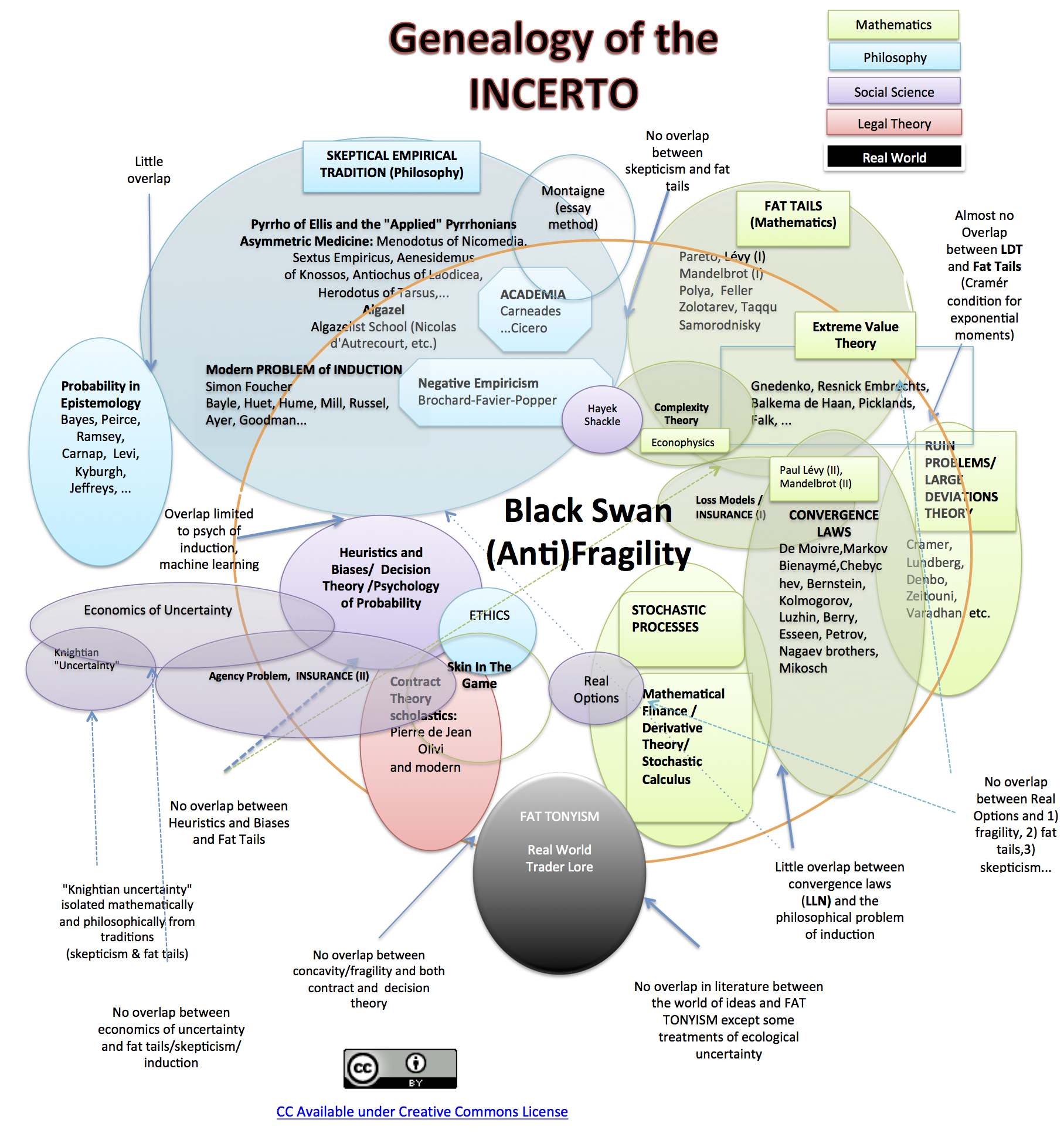
(http://www.fooledbyrandomness.com/genealogy.jpg
Genealogy of the ideas contained in Taleb's work. Pretty useful. I had it embedded but it took up the entire page for me.
People are perennially interested in the reliability of hard drives. Here is useful hard data. Summary:
At Backblaze, as of December 31, 2014, we had 41,213 disk drives spinning in our data center, storing all of the data for our unlimited backup service. That is up from 27,134 at the end of 2013. ... The table below shows the annual failure rate through the year 2014.
tl;dr Avoid 3Tb Seagate Barracuda drives.
I'm looking at setting up my own website, both for the experience and to allow hosting of some files for a game I'm making. What I'd like is to register a domain, probably (myrealname).com and/or .ca, both of which are available, set up a wiki on it, and host a few(reasonably large) files. Thing is, I have a computer that stays on 24/7, and I'm generally competent with computers, so I suspect I can probably get by without paying for hosting, which appeals to me.
Can anyone link me to guides on how to do this? My Googling is turning up shockingly little, just "Pay someone for hosting!". I've registered domains before, but never done any hosting.
I've got a problem. My sleep schedule is FUCKED UP.
Yesterday, I went to bed at around 8:00 AM and got up at 10:00 PM. I don't normally sleep 14 hours, but I've somehow become nocturnal; sleeping from 7 AM until up at 5 PM isn't particularly unusual for me. I'm not actually sleep deprived, but always sleeping through "normal business hours" tends to cause me problems - I can't get to the bank even when it's important - and isn't very convenient for my girlfriend either. My father jokes that I must be turning into a vampire because I'm never awake ...
Anyone have a source for a summary of full life extension testing/supplementation regime?
Thiel?Kurzweil?
I've let things slide for a while, and want to get back on track with a full regime, including hormones and pharmaceuticals. I'm thinking cardiovascular, blood sugar, hormone, and neuroprotection.
I would not recommend hormones. Beware of Algernon's law - if a simple biochemical tweak were always helpful, it'd probably already be that way. In particular a lot of things that try to work against 'aging' as opposed to specific dysfunctions will probably cause cancer. Thiel is a particular offender there, he recently started taking HGH with the justification "we'll probably have cancer licked in a decade or two". I read that statement to some people in my lab, where it provoked universal laughter.
Remember the 80/20 rule. Don't over-optimize; it could be expensive and dangerous.
At least get your diet in line before you worry too much about pharmaceuticals.
Start with medical tests for cholesterol, blood pressure, vitamin D, magnesium, diabetes and anything else your doctor recommends based on your age, family and disease history.
an actual medical doctor,
Well...
Dr. Grossman is licensed as an M.D., and an M.D.(H), a homeopathic medical doctor.
(Warning: politics)
Posting a few links to relevant followups to the "Comment 171" situation and the related sexual harassment scandal and MIT's reaction which prompted that discussion. I'm posting these because the issue has come up in the last few weeks of open threads.
This piece seems like an excellent example of reading others as charitably as possible and essentially steelmanning every argument involved. It also gives a pretty good summary of the entire situation with relevant links.
Also, one of the women involved in the original sexual ha...
I am taking a graduate course called "Vision Systems". This course "presents an introduction to the physiology, psychophysics, and computational aspects of vision". The professor teaching the course recommended that those of us that have not taken at least an undergraduate course in perception get an introductory book on the subject. The one he recommends, which is also the one he uses for his undergraduate course, is this: http://www.amazon.com/Sensation-Perception-Looseleaf-Third-Edition/dp/0878938761 Unfortunately, this book goes for...
Scott Alexander, alias Yvain, conducted a companion survey for the readership of his blog, Slate Star Codex, to parallel and contrast with the survey of the LessWrong community. The issue I ponder below will likely come to light when the results from that survey are published. However, I'm too curious thinking about this to wait, even if present speculation is later rendered futile.
Slate Star Codex is among my favorite websites, let alone blogs. I spend more time reading it than I do on LessWrong, and it may only be second to Wikipedia or Facebook for webs...
More on Slate Star Codex than on LessWrong, there is discussion of memes as a useful concept for explaining or thinking about cultural evolution. The term 'memetics' is thrown around to correspond to the theory of memes as a field of inquiry. I want to know more about memetics, lest I would consider it not worth my time to think about it more deeply. More broadly, if not definitely a pseudoscience, it skirts that border more frequently. I expect the discourse on memes might be at least a bit less speculative if us amateur memeticists here knew more about i...
I've been thinking about (and writing out my thoughts on) the real meaning of entropy in physics and how it relates to physical models. It should be obvious that entropy(physical system) isn't well-defined; only entropy(physical model, physical system) is defined. Here, 'physical model' might refer to something like the kinetic theory of gases, and 'physical system' would refer to, say, some volume of gas or a cup of tea. It's interesting to think about entropy from this perspective because it becomes related to the subjectivist interpretation of probability. I want to know if anyone knows of any links to similar ideas and thoughts.
Not Quite the Prisoner's Dilemma
Evolving strategies through the Noisy Iterated Prisoner's Dilemma has revealed all sorts of valuable insights into game theory and decision theory. Does anyone know of any similar tournaments where the payouts weren't constant, so that any particular round might or might not qualify as a classic Prisoner's Dilemma?
Any worthwhile reading post that isn't found on the Sequences? (http://wiki.lesswrong.com/wiki/Sequences)
I recommend this one http://lesswrong.com/lw/iri/how_to_become_a_1000_year_old_vampire/ although I've read it a long time ago - I may have a different opinion on it currently. Re-reading it now.
Is there an eReader version of the Highly Advanced Epistemology 101 for Beginners sequence anywhere?
Public voting and public scoring
I am sure this has been debated here before but I keep dreaming of it anyway. Let's say everyone's upvotes and downvotes were public and you could independently score posts using this data with your own algorithm. If the algorithms to score posts were also public then you could use another users scoring algorithm instead of writing your own (think lesswrong power-user).
As a simple example, lets say my algorithm is to average the score of user_Rational and user_Insightful and user_Rational algorithm is just lesswrong regular...
General question: I've read somewhere that there's a Bayesian approach to at least partially justifying simplicity arguments / Occam's Razor. Where can I find a good accessible explanation of this?
Specifically: Say you're presented with a body of evidence and you come up with two sets of explanations for that evidence. Explanation Set A consists of one or two elegant principles that explain the entire body of evidence nicely. Explanation Set B consists of hundreds of separate explanations, each one of which only explains a small part of the evidence. Assum...
The B approach to Occam's razor is just a way to think carefully about your possible preference for simplicity. If you prefer simpler explanations, you can bias your prior appropriately, and then the B machinery will handle how you should change your mind with more evidence (which might possibly favor more complex explanations, since Nature isn't obligated to follow your preferences).
I don't think it's a good idea to use B in settings other than statistical inference, or probability puzzles. Arguing with people is an exercise in xenoanthropology, not an exercise in B.
I have a slate of questions that I often ask people to try and better understand them. Recently I realized that one of these questions may not be as open-ended as I'd thought, in the sense that it may actually have a proper answer according to Bayesian rationality. Though, I remain uncertain about this. The question is actually quite simple and so I offer it to the Less Wrong community to see what kind of answers people can come up with, as well as what the majority of Less Wrongers think. If you'd rather you can private message me your answer.
The question is:
Truth or Happiness? If you had to choose between one or the other, which would you pick?
What app does less wrong recommend for to-do lists? I just started using Workflowy (recommended from a LW friend), but was wondering if anyone had strong opinions in favor of something else.
P.S. If you sign up for workflowy here, you get double space.
EDIT: The above link is my personal invite link, and I get told when someone signs up using it, and I get to see their email address. I am not going to do anything with them, but I feel obligated to give this disclaimer anyway.
Could use an editor or feedback of some kind for a planned series of articles on scarcity, optimization, and economics. Have first article written and know what the last article is supposed to say, and will be filling in the gaps for a while. Would like to start posting said articles when there is enough to keep up a steady schedule.
No knowledge of economics required, but would be helpful if you were pretty experienced with how the community likes information to be presented. Reply to this comment or send me a message, and let me know how I can send you the text of the article (only one at present).
One one hand, gorillas are crucially important for the seed dispersion that maintains forests, so we need to save them from ebola, even if only for the human benefit that can be gained from those forests. On the other hand, ebola is killing humans, too. There's disagreement on how to allocate research funding.
I think you'll get somewhere by searching for the phrase "complexity penalty." The idea is that we have a prior probability for any explanation that depends on how many terms / free parameters are in the explanation. For your particular example, I think you need to argue that their prior probability should be different than it is.
I think it's easier to give a 'frequentist' explanation of why this makes sense, though, by looking at overfitting. If you look at the uncertainty in the parameter estimates, they roughly depend on the number of sample points per parameter. Thus the fewer parameters in a model, the more we think each of those parameters will generalize. One way to think about this is the more free parameters you have in a model, the more explanatory power you get "for free," and so we need to penalize the model to account for that. Consider the Akaike information criterion and Bayesian information criterion.
{kind=link}
If it's worth saying, but not worth its own post (even in Discussion), then it goes here.
Previous Open Thread
Next Open Thread
Notes for future OT posters:
1. Please add the 'open_thread' tag.
2. Check if there is an active Open Thread before posting a new one. (Immediately before; refresh the list-of-threads page before posting.)
3. Open Threads should be posted in Discussion, and not Main.
4. Open Threads should start on Monday, and end on Sunday.