Hi KnaveOfAllTrades, thx for commenting!
Your proton beam problem is not decision-determined in the sense of Yudkowsky 2010. That is, it depends directly on the decision algorithm rather than depending only on the decisions it makes. Indeed it is impossible to come up with a decision theory that is optimal for all problems, but it might be possible to come up with a decision theory that is optimal for some reasonable class of problems (like decision-determined problems).
Now, there is a decision-determined version of your construction. Consider the following "diagonal" problem. The agent makes a decision out of some finite set. Omega runs a simulation of XDT and penalizes the agent iff its decision is equal to XDT's decision.
This is indeed a concern for deterministic agents. However, if we allow the decision algorithm access to an independent source of random bits, the problem is avoided. XDT produces all answers distributed uniformly and gets optimal payoff.
This is indeed a concern for deterministic agents. However, if we allow the decision algorithm access to an independent source of random bits, the problem is avoided. XDT produces all answers distributed uniformly and gets optimal payoff.
Omega can predict the probability distribution on the agent answers, and it is possible to construct a Newcomb-like problem that penalizes any specific distribution.
Outline: I describe a flaw in UDT that has to do with the way the agent defines itself (locates itself in the universe). This flaw manifests in failure to solve a certain class of decision problems. I suggest several related decision theories that solve the problem, some of which avoid quining thus being suitable for agents that cannot access their own source code.
EDIT: The decision problem I call here the "anti-Newcomb problem" already appeared here. Some previous solution proposals are here. A different but related problem appeared here.
Updateless decision theory, the way it is usually defined, postulates that the agent has to use quining in order to formalize its identity, i.e. determine which portions of the universe are considered to be affected by its decisions. This leaves the question of which decision theory should agents that don't have access to their source code use (as humans intuitively appear to be). I am pretty sure this question has already been posed somewhere on LessWrong but I can't find the reference: help? It also turns out that there is a class of decision problems for which this formalization of identity fails to produce the winning answer.
When one is programming an AI, it doesn't seem optimal for the AI to locate itself in the universe based solely on its own source code. After all, you build the AI, you know where it is (e.g. running inside a robot), why should you allow the AI to consider itself to be something else, just because this something else happens to have the same source code (more realistically, happens to have a source code correlated in the sense of logical uncertainty)?
Consider the following decision problem which I call the "UDT anti-Newcomb problem". Omega is putting money into boxes by the usual algorithm, with one exception. It isn't simulating the player at all. Instead, it simulates what would a UDT agent do in the player's place. Thus, a UDT agent would consider the problem to be identical to the usual Newcomb problem and one-box, receiving $1,000,000. On the other hand, a CDT agent (say) would two-box and receive $1,000,1000 (!) Moreover, this problem reveals UDT is not reflectively consistent. A UDT agent facing this problem would choose to self-modify given the choice. This is not an argument in favor of CDT. But it is a sign something is wrong with UDT, the way it's usually done.
The essence of the problem is that a UDT agent is using too little information to define its identity: its source code. Instead, it should use information about its origin. Indeed, if the origin is an AI programmer or a version of the agent before the latest self-modification, it appears rational for the precursor agent to code the origin into the successor agent. In fact, if we consider the anti-Newcomb problem with Omega's simulation using the correct decision theory XDT (whatever it is), we expect an XDT agent to two-box and leave with $1000. This might seem surprising, but consider the problem from the precursor's point of view. The precursor knows Omega is filling the boxes based on XDT, whatever the decision theory of the successor is going to be. If the precursor knows XDT two-boxes, there is no reason to construct a successor that one-boxes. So constructing an XDT successor might be perfectly rational! Moreover, a UDT agent playing the XDT anti-Newcomb problem will also two-box (correctly).
To formalize the idea, consider a program called the precursor which outputs a new program
called the precursor which outputs a new program 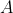 called the successor. In addition, we have a program
called the successor. In addition, we have a program 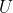 called the universe which outputs a number
called the universe which outputs a number ) called utility.
called utility.
Usual UDT suggests for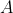 the following algorithm:
the following algorithm:
(1):=(\underset{f:I \rightarrow O}{\arg\max} \: E[U()|\forall j \in I: A(j)=f(j)])(i))
Here,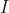 is the input space,
is the input space, 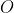 is the output space and the expectation value is over logical uncertainty.
is the output space and the expectation value is over logical uncertainty. 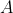 appears inside its own definition via quining.
appears inside its own definition via quining.
The simplest way to tweak equation (1) in order to take the precursor into account is
(2):=(\underset{f:I \rightarrow O}{\arg\max} \: E[U()|\forall j \in I: P()(j)=f(j)])(i))
This seems nice since quining is avoided altogether. However, this is unsatisfactory. Consider the anti-Newcomb problem with Omega's simulation involving equation (2). Suppose the successor uses equation (2) as well. On the surface, if Omega's simulation doesn't involve 1, the agent will two-box and get $1000 as it should. However, the computing power allocated for evaluation the logical expectation value in (2) might be sufficient to suspect
1, the agent will two-box and get $1000 as it should. However, the computing power allocated for evaluation the logical expectation value in (2) might be sufficient to suspect  's output might be an agent reasoning based on (2). This creates a logical correlation between the successor's choice and the result of Omega's simulation. For certain choices of parameters, this logical correlation leads to one-boxing.
's output might be an agent reasoning based on (2). This creates a logical correlation between the successor's choice and the result of Omega's simulation. For certain choices of parameters, this logical correlation leads to one-boxing.
The simplest way to solve the problem is letting the successor imagine that produces a lookup table. Consider the following equation:
produces a lookup table. Consider the following equation:
(3):=(\underset{f:I \rightarrow O}{\arg\max} \: E[U()|P()=LUT(f))(i))
Here,) is a program which computes
is a program which computes 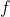 using a lookup table: all of the values are hardcoded.
using a lookup table: all of the values are hardcoded.
For large input spaces, lookup tables are of astronomical size and either maximizing over them or imagining them to run on the agent's hardware doesn't make sense. This is a problem with the original equation (1) as well. One way out is replacing the arbitrary functions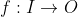 with programs computing such functions. Thus, (3) is replaced by
with programs computing such functions. Thus, (3) is replaced by
(4):=(\underset{\pi}{\arg\max} \: E[U()|P()=\pi)(i))
Where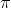 is understood to range over programs receiving input in
is understood to range over programs receiving input in 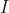 and producing output in
and producing output in 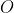 . However, (4) looks like it can go into an infinite loop since what if the optimal
. However, (4) looks like it can go into an infinite loop since what if the optimal 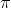 is described by equation (4) itself? To avoid this, we can introduce an explicit time limit
is described by equation (4) itself? To avoid this, we can introduce an explicit time limit 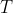 on the computation. The successor will then spend some portion
on the computation. The successor will then spend some portion 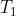 of
of 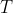 performing the following maximization:
performing the following maximization:
(4'):=(\underset{\pi}{\arg\max} \: E[U()|P()=S_{T_1}(\pi))(i))
Here,) is a program that does nothing for time
is a program that does nothing for time 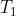 and runs
and runs 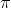 for the remaining time
for the remaining time 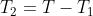 . Thus, the successor invests
. Thus, the successor invests 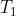 time in maximization and
time in maximization and 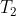 in evaluating the resulting policy
in evaluating the resulting policy 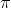 on the input it received.
on the input it received.
In practical terms, (4') seems inefficient since it completely ignores the actual input for a period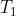 of the computation. This problem exists in original UDT as well. A naive way to avoid it is giving up on optimizing the entire input-output mapping and focus on the input which was actually received. This allows the following non-quining decision theory:
of the computation. This problem exists in original UDT as well. A naive way to avoid it is giving up on optimizing the entire input-output mapping and focus on the input which was actually received. This allows the following non-quining decision theory:
(5):=\underset{o \in O}{\arg\max} \: E[U()|P() \in F_{i,o}])
Here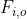 is the set of programs which begin with a conditional statement that produces output
is the set of programs which begin with a conditional statement that produces output  and terminate execution if received input was
and terminate execution if received input was 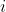 . Of course, ignoring counterfactual inputs means failing a large class of decision problems. A possible win-win solution is reintroducing quining2:
. Of course, ignoring counterfactual inputs means failing a large class of decision problems. A possible win-win solution is reintroducing quining2:
(6):=\underset{o \in O}{\arg\max} \: E[U()|P()=\hat{F}_{i,o}(A)])
Here,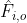 is an operator which appends a conditional as above to the beginning of a program. Superficially, we still only consider a single input-output pair. However, instances of the successor receiving different inputs now take each other into account (as existing in "counterfactual" universes). It is often claimed that the use of logical uncertainty in UDT allows for agents in different universes to reach a Pareto optimal outcome using acausal trade. If this is the case, then agents which have the same utility function should cooperate acausally with ease. Of course, this argument should also make the use of full input-output mappings redundant in usual UDT.
is an operator which appends a conditional as above to the beginning of a program. Superficially, we still only consider a single input-output pair. However, instances of the successor receiving different inputs now take each other into account (as existing in "counterfactual" universes). It is often claimed that the use of logical uncertainty in UDT allows for agents in different universes to reach a Pareto optimal outcome using acausal trade. If this is the case, then agents which have the same utility function should cooperate acausally with ease. Of course, this argument should also make the use of full input-output mappings redundant in usual UDT.
In case the precursor is an actual AI programmer (rather than another AI), it is unrealistic for her to code a formal model of herself into the AI. In a followup post, I'm planning to explain how to do without it (namely, how to define a generic precursor using a combination of Solomonoff induction and a formal specification of the AI's hardware).
1 If Omega's simulation involves , this becomes the usual Newcomb problem and one-boxing is the correct strategy.
, this becomes the usual Newcomb problem and one-boxing is the correct strategy.
2 Sorry agents which can't access their own source code. You will have to make do with one of (3), (4') or (5).