...some cherry-picked examples...
If you know these are cherry-picked examples, why not make them not-cherry-picked? Why post something you know is strongly misleading?
the rest of the field has come to regard Eliezer as largely correct
It seems possible to me that you're witnessing a selection bias where the part of the field who disagree with Eliezer don't generally bother to engage with him, or with communities around him.
It's possible to agree on ideas like "it is possible to create agent AGI" and "given the right preconditions, AGI could destroy a sizeable fraction of the human race", while at the same time disagreeing with nearly all of Eliezer's beliefs or claims on that same topic.
That in turn would lead to different beliefs for what types of approach will work, which could go a long way towards explaining why so many AI research labs are not pursuing ideas like pivotal acts or other Eliezer-endorsed solutions.
For example, the linked post didn't use this quote when discussing Eliezer's belief that intelligence doesn't require much compute power, but as recently as 2021 (?) he said
Well, if you're a superintelligence, you can probably do human-equivalent human-speed general intelligence on a 286, though it might possibly have less fine motor control, or maybe not, I don't know. [source]
"or maybe not, I don't know" is doing a lot of work in covering that statement.
Heh, I removed that line inbetween when you starting and finishing your comment.
"For example, the linked post didn't use this quote when discussing Eliezer's belief that intelligence doesn't require much compute power, but as recently as 2021 (?) he said"
I don't think it's very clear to me what a super-intelligence could do on a 286, and don't think you should be confident in assuming he's wrong. "Or maybe not, I don't know" seems very appropriate
Only if we pretend that it's an unknowable question and that there's no way to look at the limitations of a 286 by asking about how much data it can reasonably process over a timescale that is relevant to some hypothetical human-capable task.
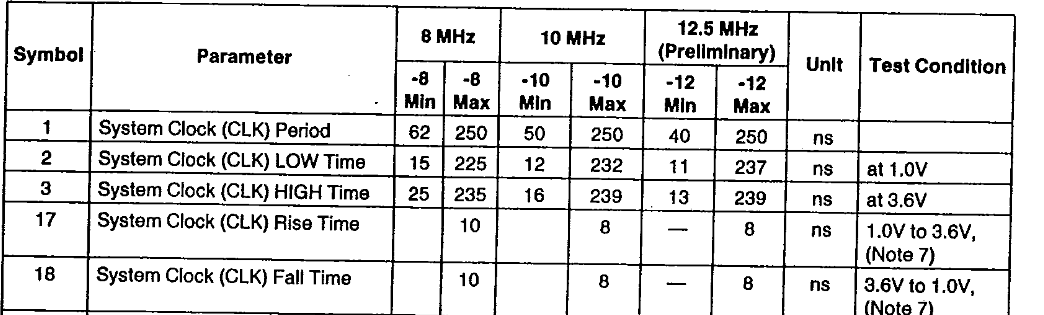
http://datasheets.chipdb.org/Intel/x86/286/datashts/intel-80286.pdf
The relevant question here is about data transfers (bus speed) and arithmetic operations (instruction sets). Let's assume the fastest 286 listed in this datasheet -- 12.5 MHz.
Let's consider a very basic task -- say, catching a ball thrown from 10-15 feet away.
To simplify this analysis, we are going to pretend that if we can analyze 3 image frames, in close proximity, then we can do a curve fit and calculate the ball's trajectory, so that we don't need need to look at any other images.
Let's also assume that a 320x240 image is sufficient, and that it's sufficient for the image to be in 1-byte-per-pixel grayscale. For reference, that looks like this:

With the 12.5 MHz system clock, we're looking at 80 nanoseconds per clock cycle.
We've got 76800 bytes per image and that's the same as 38400 processor words (it is 16-bit).
Because data transfers are one word per two processor clock cycles, and a processor clock cycle is two system clock cycles, we've got one word for every 4 system clock cycles. That's 220 nanoseconds per word. Multiply that through and we've got ~8.5 ms to transfer each image into memory, or 25 milliseconds total for the 3 images we need.
We can fit all 3 images into the 1 megabyte of address space allowed in real addressing mode, so we don't need to consider virtual addresses. This is good because virtual addresses would be slower.
In order to calculate the ball's trajectory, we'll need to find it in each image, and then do a curve fit. Let's start with just the first image, because maybe we can do something clever on subsequent images.
We'll also assume that we can do depth perception on each image because we know the size of the ball we are trying to catch. If we didn't have that assumption, we'd want 2 cameras and 2 images per frame.
Most image processing algorithms are O(N) with respect to the size of the image. The constant factor is normally the number of multiplications and additions per pixel. We can simplify here and assume it's like a convolution with a 3x3 kernel, so each pixel is just multiplied 9 times and added 9 times. This is a comical simplification because any image processing for "finding a ball" requires significantly more compute than that.
Let's also assume we can do this using only integer math. If it was floating point, we'd need to use the 80287[1], and we'd pay for additional bus transfers to shuffle the memory to that processor. Also, math operations on the 80287 seem to be about 100-200 clock cycles, whereas our integer add and integer multiply are only 7 and 13 clock cycles respectively.

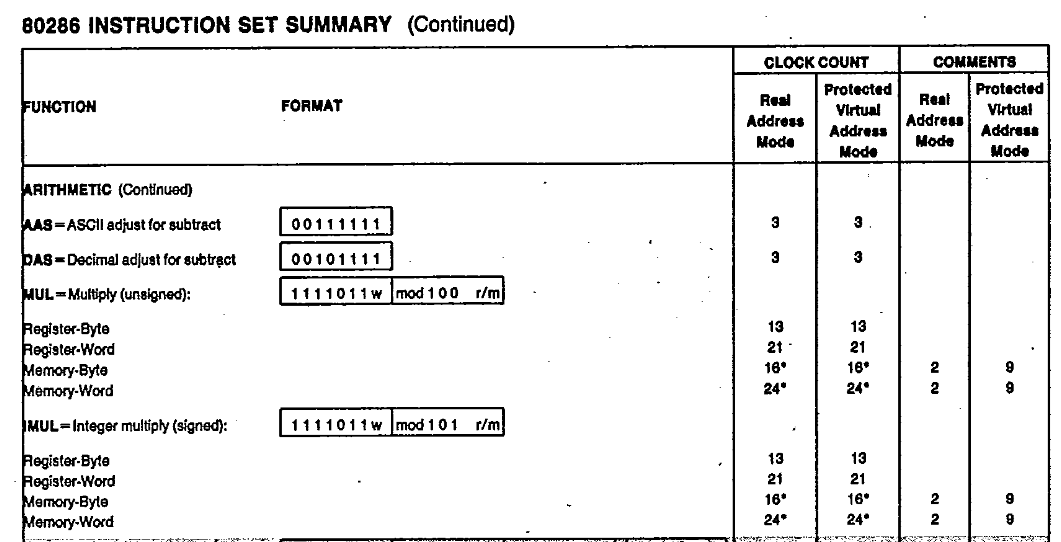
So each pixel is 9 multiplies and 9 additions, which at 12.5 MHz system clock gives us 14.4 microseconds per pixel, or 1.1 seconds per image.
Note that this is incredibly charitable, because I'm ignoring the fact that we only have 8 registers on this processor, so we'll actually be spending a large amount of time on clock cycles just moving data into and out of the registers.
Since we have 3 images, and if we can't do some type of clever reduction after the first image, then we'll have to spend 1.1 seconds on each of them as well. 1.1 seconds is a long enough period of time that I'm not sure you can make any reasonable estimate about where the ball might be in subsequent frames after a single sample, so we are probably stuck.
That means we're looking at 3.3 seconds before we can do that curve fit to avoid the expensive image processing work. Unless the ball is being thrown from very far away (and if it was, it wouldn't be resolvable with this low image resolution), this system is not going to be able to react quickly enough to catch a ball thrown from 10-15 feet away.
Conclusion
Now is the point in this conversation where someone starts suggesting that a superhuman intelligence won't need to look at pixels, or transfer data into memory, and they'll somehow use algorithms that side-step basic facts about how computers work like how many clock cycles a multiplication takes. Or someone suggests that intelligence, as an algorithm, is not like looking at pixels, and reasoning about facts & logic & inferences requires far fewer math operations, so it's not at all comparable, despite the next obvious question being, "what is the time-complexity of general intelligence?"
As a human engineer who has done applied classical (IE:non-AI, you write the algorithms yourself) computer vision. That's not a good lower bound.
Image processing was a thing before computers were fast. Here's a 1985 paper talking about tomato sorting. Anything involving a kernel applied over the entire image is way too slow. All the algorithms are pixel level.
Note that this is a fairly easy problem if only because once you know what you're looking for, it's pretty easy to find it thanks to the court being not too noisy.
An O(N) algorithm is iffy at these speeds. Applying a 3x3 kernel to the image won't work.
So let's cut down on the amount of work to do. Look at only 1 out of every 16 pixels to start with. Here's an (80*60) pixel image formed by sampling one pixel in every 4x4 square of the original.

The closer player is easy to identify. Remember that we still have all the original image pixels. If there's a potentially interesting feature (like the player further away), we can look at some of the pixels we're ignoring to double check.
Since we have 3 images, and if we can't do some type of clever reduction after the first image, then we'll have to spend 1.1 seconds on each of them as well.
Cropping is very simple, once you find the player that's serving, focus on that rectangle in later images. I've done exactly this to get CV code that was 8FPS@100%CPU down to 30FPS@5%. Once you know where a thing is, tracking it from frame to frame is much easier.
Concretely, the computer needs to:
- locate the player serving and their hands/ball (requires looking at whole image)
- track the player's arm/hand movements pre-serve
- track the ball and racket during toss into the air
- track the ball after impact with the racket
- continue ball tracking
Only step 1 requires looking at the whole image. And there, only to get an idea of what's around you. Once the player is identified, crop to them and maintain focus. If the camera/robot is mobile, also glance at fixed landmarks (court lines, net posts/net/fences) to do position tracking.
If we assume the 286 is interfacing with a modern high resolution image sensor which can do downscaling (IE:you can ask it to average 2*2 4*4 8*8 etc. blocks of pixels) and windowing (You can ask for a rectangular chunk of the image to be read out. This gets you closer to what the brain is working with (small high resolution patch in the center of visual field + low res peripheral vision on moveable eyeball)
Conditional computation is still common in low end computer vision systems. Face detection is a good example. OpenCV Face Detection: Visualized. You can imagine that once you know where the face is in one frame tracking it to the next frame will be much easier.
Now maybe you're thinking: "That's on me I, set the bar too low"
Well human vision is pretty terrible. Resolution of the fovea is good but that's about a 1 degree circle in your field of vision. move past 5° and that's peripheral vision, which is crap. Humans don't really see their full environment.
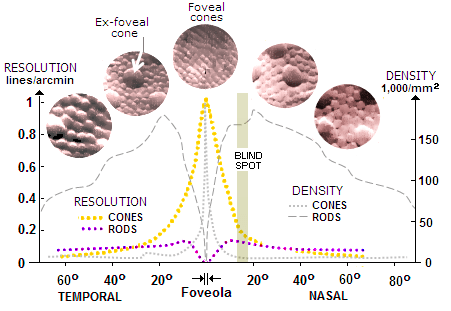

Current practical applications of this is to cut down on graphics quality in VR headsets using eye tracking. More accurate and faster tracking allows more aggressive cuts to total pixels rendered.

This is why where's waldo is hard for humans.
This caught my eye:
There is a large gap between the accomplishments of humans and chimpanzees, which Yudkowsky attributes this to a small architectural improvement
Based on my recent thinking, the big amplifier may have been improvements in communication capacity, making human groups more flexible and effective learning networks than had previously existed. The capacity of individual brains may not have mattered as much as is usually thought.
This is a link-post to a piece I just posted to the EA Forum, discussing negative aspects of Eliezer Yudkowsky's forecasting track record. In case it also receives significant discussion here, you may also want to look at the comments on the Forum (e.g. Gwern just posted a useful critical comment there).