Tl;dr, Neural networks are deterministic and sometimes even reversible, which causes Shannon information measures to degenerate. But information theory seems useful. How can we square this (if it's possible at all)? The attempts so far in the literature are unsatisfying.
Here is a conceptual question: what is the Right Way to think about information theoretic quantities in neural network contexts?
Example: I've been recently thinking about information bottleneck methods: given some data distribution , it tries to find features specified by that have nice properties like minimality (small ) and sufficiency (big ).
But as pointed out in the literature several times, the fact that neural networks implement a deterministic map makes these information theoretic quantities degenerate:
- if Z is a deterministic map of X and they’re both continuous, then I(X;Z) is infinite.
- Binning / Quantizing them does turn Z into a stochastic function of X but (1) this feels very adhoc, (2) this makes the estimate depend heavily on the quantization method, and (3) this conflates information theoretic stuff with geometric stuff, like clustering of features making them get quantized into the same bin thus artificially reducing MI.
- we could deal with quantized neural networks and that might get rid of the conceptual issues with infinite I(X;Z), but …
- Reversible networks are a thing. The fact that I(X;Z) stays the same throughout a constant-width bijective-activation network for most parameters - even randomly initialized ones that intuitively “throws information around blindly” - just doesn’t seem like it’s capturing the intuitive notion of shared information between X and Z (inspired by this comment).
There are attempts at solving these problems in the literature, but the solutions so far are unsatisfying: they're either very adhoc, rely on questionable assumptions, lack clear operational interpretation, introduce new problems, or seem theoretically intractable.
- (there’s the non-solution of only dealing with stochastic variants of neural networks, which is unsatisfactory since it ignores the fact that neural networks exist and work fine without stochasticity)
Treat the weight as stochastic:
This paper (also relevant) defines several notions of information measure relative to an arbitrary choice of and (not a Bayesian posterior):
- measure 1: “information in weight”
- specifically, given , choose to minimize a term that trades off expected loss under and weighted by some , and say the KL term is the information in the weights at level for .
- interpretation: additional amount of information needed to encode (relative to encoding based on prior) the weight distribution which optimally trades off accuracy and complexity (in the sense of distance from prior).
- measure 2: “effective information ” is , where is a deterministic function of parameterized by , is a stochastic function of where is perturbed by some the that minimizes the aforementioned trade off term.
- interpretation: amount of "robust information” shared between the input and feature that resists perturbation in the weights - not just any perturbation, but perturbations that (assuming is e.g., already optimized) lets the model retain a good loss / complexity tradeoff.
I like their idea of using shannon information measures to try to capture a notion of “robustly” shared information. but the attempts above so far seem pretty ad hoc and reliant on shaky assumptions. i suspect SLT would be helpful here (just read the paper and see things like casually inverting the fisher information matrix).
Use something other than shannon information measures:
There’s V-information which is a natural extension of shannon information measures when you restrict the function class to consider (due to e.g., computational constraints). But now the difficult question is the choice of natural function class. Maybe linear probes are a natural choice, but this still feels ad hoc.
There’s K-complexity, but there's the usual uncomputability and the vibes of intractability in mixing algorithmic information theory notions with neural networks when the latter has more of a statistical vibe than algorithmic. idk, this is just really vibes, but I am wary of jumping to the conclusion of thinking AIT is necessary in information theoretically analyzing neural networks based on the "there's determinism and AIT is the natural playing field for deterministic information processing systems"-type argument.
Ideally, I could keep using the vanilla shannon information measures somehow because they’re nice and simple and computable and seems potentially tractable both empirically and theoretically.
And so far, I haven't been able to find a satisfying answer to the problem. I am curious if anyone has takes on this issue.
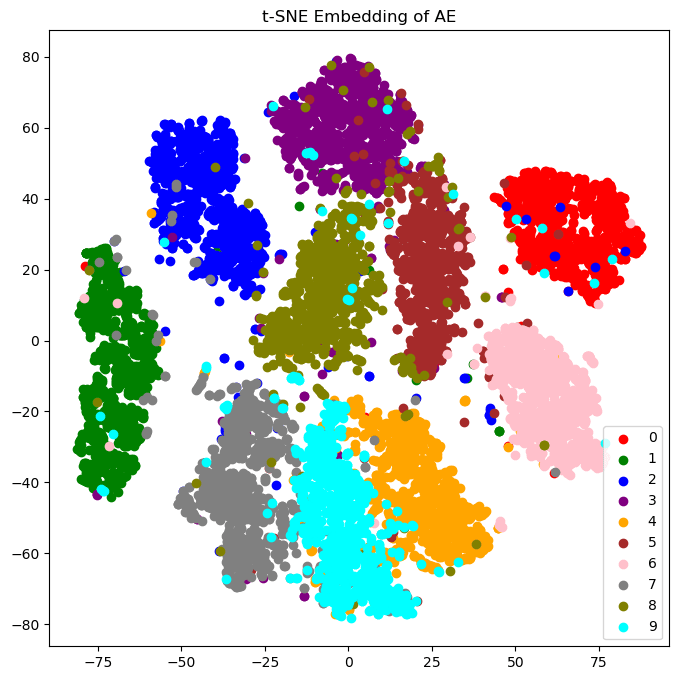
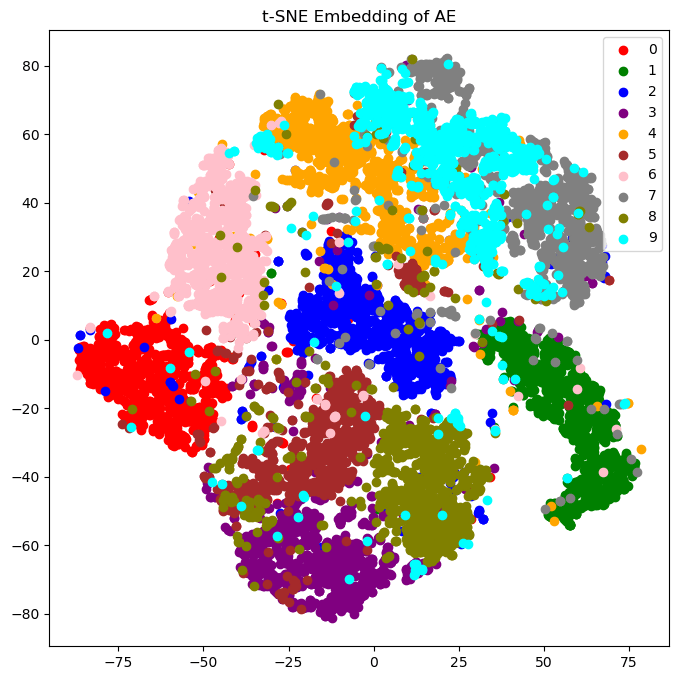
Another perspective would be too look at the activations of an autoregressive deep learning model, e.g. a transformer, during inference as a stochastic process: the collection of activation (Xt) at some layer as random variables indexed by time t, where t is token position.
One could for example look at mutual information between the history X−t=(Xt,Xt−1,...) and the future of the activations Xt+1, or look at (conditional) mutual information between the past and future of subprocesses of Xt (note: transfer entropy can be a useful tool to quantify directed information flow between different stochastic processes). There are many information-theoretic quantities one could be looking at.
If you want to formally define a probability distribution over activations, you could maybe push forward the discrete probability distribution over tokens (in particular the predictive distribution) via the embedding map.
In the context of computational mechanics this seems like a useful perspective, for example to find belief states by optimizing mutual information between some coarse graining of the past states and future states to find belief states in a data-driven way (this is too vague stated like that, and i am working on a draft that get into more details about that perspective).