Epistemic Effort: Rough notes from a shallow dive. Looked into this for a few hours. I didn't find a strong takeaway but think this is probably a useful jumping-off-point for further work.
Most likely, whether I like it or not, there will someday be AGI research companies working on models that are dangerous to run. Maybe they'll risk an accidental unfriendly hard takeoff. Maybe they'll cross a threshold accelerate us into a hard-to-control multipolar smooth takeoff.[1]
There's some literature on organizations that operate in extremely complex domains, where failure is catastrophic. They're called High Reliability Organizations (HROs). The original work focused on three case studies: A nuclear power plant, an air traffic control company, and a nuclear aircraft carrier (aka nuclear power plant and air traffic control at the same time while people sometimes shoot at you and you can't use radar because you don't want to give away your position and also it's mostly crewed by 20 year olds without much training)
These were notable for a) being extremely complex systems where it would be really easy to screw up catastrophically, and b) somehow, they manage to persistently not screw up.
How do they do that? And does this offer any useful insights to AGI companies?
I started writing this post before Eliezer posted Six Dimensions of Operational Adequacy in AGI Projects. It's not pointed at the exact same problem, but I had a similar generator of "what needs to be true of AI companies, for them to safely work on dangerous tech?". (I think Eliezer had a higher bar in mind with Six Dimensions, which is like, "what is an AI company a researcher could feel actively good about joining")
I was initially pointed in the HRO direction by some conversations with Andrew Critch. Some of his thoughts are written up in the ARCHES report. (There's been some discussion on LessWrong)
My TL;DR after ~10 hours of looking into it:
The literature has at least some useful takeaways/principles.
Some hospitals (maybe?) successfully implemented HRO principles and drove some classes of accidents down to 0% (!? roll to disbelieve)
The literature (even the hospital "replication") isn't obviously super relevant because it's focused on domains that have much tighter feedback loops than AI research.
The most interesting part of the Air Traffic Control and Aircraft Carrier stuff is not the day-to-day-operations, but the part where new airplanes are getting designed, which consistently seem to mostly work. This part seems more analogous to AI research. Unfortunately I don't currently know where to look into that.
I suspect that dangerous Bio Research might also be more relevant, but also haven't yet found anything to look into there.
I do think the HRO principles make sense and are fairly straightforward to reason about. Some of them seem to straightforwardly seem useful at AI companies, some don't make as much sense.
There's a guy named Admiral Rickover who was a primary driver of the nuclear aircraft carrier safety program (i.e. onboarding teenagers, training them for [I think 6 months?], sending them on a [I think 1-2 year?] rotations on aircraft carriers, with zero (!?) incidents). He seems really interesting, and training programs descended from him may be worth looking into. Here's a dissertation about how he changed the navy (which I have not yet read)\
Principles from "Managing the Unexpected"
The book "Managing the Unexpected", first published in 2001, attempts to answer the question "how can we learn from Highly Reliable Organizations?" in a more general way. I found a summary of the book from researchgate.com which I'm going to quote from liberally. It distills the book down into these points:
You can’t plan for everything. Something unexpected will always happen, from hurricanes to product errors.
Planning can actually get in the way of useful responses, because people see the world through the lens of their plans and interpret events to fit their expectations.
The more volatile your work environment, the more important it is to respond well in the moment.
To make your organization more reliable, anticipate and track failures. Determine what they teach you.
Focus on operations, rather than strategy.
To become more resilient, emphasize learning, fast communication and adaptation.
The person making decisions about how to solve a problem should be the person who knows the most about it – not the person who’s highest in the hierarchy.
To build awareness, audit your organization’s current practices.
To make your organization more mindful, don’t oversimplify.
Real mindfulness may require changing your organizational culture
I'm not sure how well this all translates to AI research, but the list was interesting enough for me to buy the book. One thing that was quite unclear to me was what the epistemic status of the book was – it prescribes a bunch of interventions on organizational culture, but it doesn't say "we tried these interventions and it worked."
Applications in Hospitals
Fortunately(?), it seems like since the book was first published, there has been a massive effort to port HRO principles over into the hospital industry. (In fact when I googled "High Reliability Organizations", the first several google hits were reportsabouthospitals saying "Man, we kill people all the time. Why can't we be reliable like those nuclear aircraft carrier people in the HRO literature?"). Some programs started around 2007, and were evaluated in 2018.
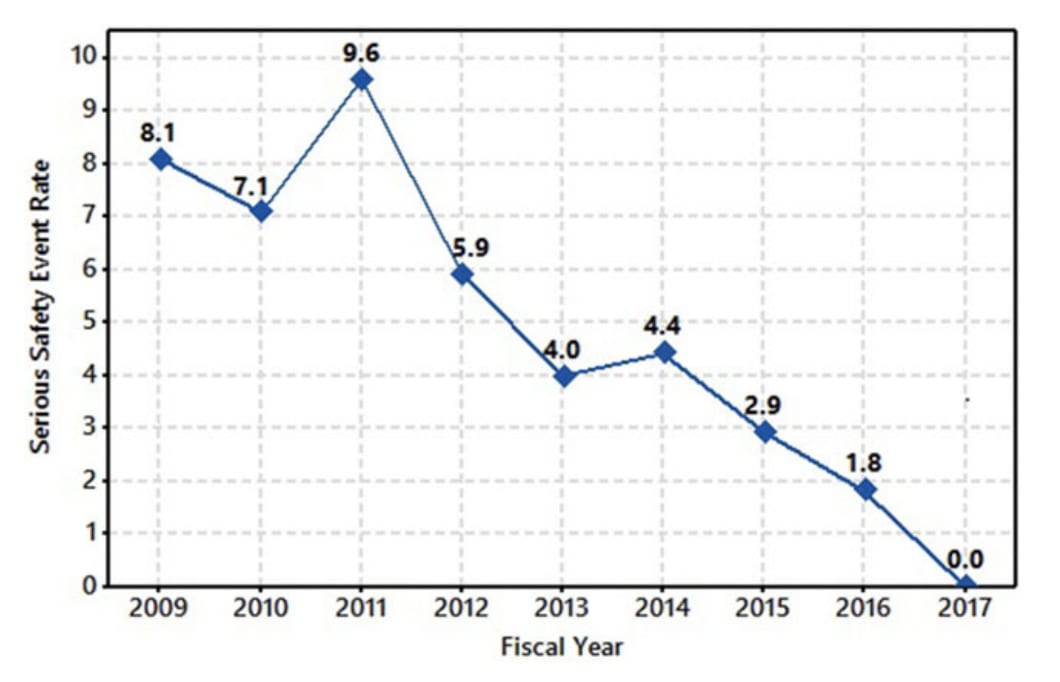
According to this report, a collection of organizational interventions resulted in serious safety events dropping to zero over the course of 9 years. They define "Serious Safety Event" as "a deviation from the standard of care that reaches the patient and leads to more than minor or minimal temporary harm".
Serious Safety Event rate per 100,000 Adjusted Patient Days plus Long-Term Care Days Over the Course of 9 Years (a steady decline is noted that paralleled several safety milestones implementation)
Notes on the methodology here:
The risk department receives notifications of these unusual occurrences, which are handled by dedicated risk specialists, each assigned a specific unusual occurrence. The risk specialist reviews the submission, and if identified as a potential safety hazard or patient harm may have occurred, he/she requests an event investigation (Code E) from the chief medical officer.
Staff receive training on how to report an unusual occurrence through several methods: new hire orientation, departmental training, Nursing Practice Council forum, safety coach discussions with teams, safety huddle message of the week, or a demo site on GenNet that walks staff through the submission process. There is not a formal process to train physicians; most often, physicians inform the nurses or nurse managers of their concerns and unusual occurrences are entered on their behalf.
I do notice "deviation from the standard of care" is a kinda vague concept that depends on whatever the standard of care is. But, assuming they held the standard consistent throughout and didn't solve the problem by massive goodharting... it seems Big If True if they drove things down to literally 0. That's at least encouraging on the general level of "we have working examples of industries becoming safer on purpose."
Does any of this translate into "Research" environments?
Nuclear powerplants, air traffic control, aircraft carriers and hospitals all share a property of having pretty clear feedback loops. And while a lot of the point of being an HRO is responding to surprises, they are in some sense attempting roughly the same thing with the same desired outcome repeatedly. If you mess up, an accident is likely to happen pretty quickly.
Some of the principles ("focus on operations rather than strategy", and "the more volatile your work environment, the more important to respond well in the moment") seem more tailored for tactical jobs rather than research companies. (I can imagine smooth takeoff worlds where an AI company does need to respond quickly in the moment to individual things going wrong... but it feels like something has already gone wrong by that point)
Some of the ideas I'd guess would transfer:
To make your organization more reliable, anticipate and track failures. Determine what they teach you.
To build awareness, audit your organization’s current practices.
To make your organization more mindful, don’t oversimplify.
Real mindfulness may require changing your organizational culture
To become more resilient, emphasize learning, fast communication and adaptation.
I expect this one to be a bit complex...
The person making decisions about how to solve a problem should be the person who knows the most about it – not the person who’s highest in the hierarchy.
...because you might have people who are the most competent at AI design but don't have security/alignment mindset.
An interesting one was...
Planning can actually get in the way of useful responses, because people see the world through the lens of their plans and interpret events to fit their expectations.
...which actually feels like maybe applies to the broader x-risk/EA ecosystem.
Appendix: Cliff Notes on "Managing the Unexpected"
[The following is from a researchgate summary, which I found pretty annoyingly formatted. I've pretty translated it into LW-Post format to be easier to read]
Countless manuals explain how to plan for crises and make it sound like everything will go smoothly if you just plan correctly. Weick and Sutcliffe say otherwise. Planning, they say, may even stand in the way of smooth processes and can be the cause of failure. They base this discussion on their studies of “high reliability organizations” (HROs), like fire fighting units and aircraft carrier crews, organizations where the unexpected is common, small events make a difference, failure is a strong possibility and lives are on the line. From those examples, they deduce principles for planning, preparation and action that will apply to any company facing change.
The book is not perfect – the authors overuse quotations and rely on buzzwords that don’t add much – but it addresses often-neglected aspects of management. getAbstract recommends it to anyone who is trying to make an organization more reliable and resilient amid change.
Abstract
Learning from High Reliability Organizations
Things you don’t expect to occur actually happen to you every day. Most surprises are minor, like a staff conflict, but some aren’t, like a blizzard. Some test your organization to the verge of destruction. You can’t plan for the unexpected, and in many cases, planning actually sets you up to respond incorrectly. You make assumptions about how the world is and what’s likely to happen. Unfortunately, many people try to make their worldview match their expectations, and thus ignore or distort signs that something different is happening. People look for confirmation that they’re correct, not that they’re wrong.
Planning focuses organizational action on specific, anticipated areas, which shuts down improvisation. When people plan, they also tend to “repeat patterns of activity that have worked in the past.” That works well if things stay the same – but when they change and the unexpected erupts, you are left executing solutions that don’t really fit your new situation
Consider organizations such as hospital emergency departments or nuclear power plants, which have to cope with extraordinary situations on a regular basis. These organizations have learned to deal regularly with challenging, disruptive events. They have adapted so that they react appropriately to the unexpected. They recognize that planning can only take an organization so far. After that, the way it responds to crisis determines its success. Your company can learn from the way these “high reliability organizations” (HROs) respond to crises, and, more generally, you can use their organizing principles in your own organization. Five core principles guide these HROs. The fi rst three emphasize anticipating problems; the last two emphasize containing problems after they happen
1. Preoccupation with failure. Attention on close calls and near misses (“being lucky vs. being good”); focus more on failures rather than successes. 2. Reluctance to simplify interpretations. Solid “root cause” analysis practices. 3. Sensitivity to operations. Situational awareness and carefully designed change management processes. 4. Commitment to resilience. Resources are continually devoted to corrective action plans and training. 5. Deference to expertise. Listen to your experts on the front lines (ex. authority follows expertise).
2. HROs are “reluctant to accept simplification” – Simplification is good and necessary. You need it for order and clarity, and for developing routines your organization can follow. However, if you simplify things too much or too quickly you may omit crucial data and obscure essential, information you need for problem solving. Labeling things to put them in conceptual categories can lead to dangerous oversimplification. NASA’s practice of classifying known glitches as “in-family” and new problems as “out-of-family” contributed to the Columbia disaster. By miscategorizing the damage to the shuttle as a maintenance-level “tile problem,” people downplayed its importance. To reduce such labeling danger, use hands-on observation. When things go wrong, don’t count on one observer; make sure people from varied backgrounds have time to discuss it at length. Re-examine the categories your organization uses and “differentiate them into subcategories,” so nothing gets hidden or blurred
3. HROs remain “sensitive to operations” – Stay focused on the actual situation as it is happening. Of course, aircraft carrier crewmembers, for instance, should align their actions with the larger strategic picture – but they can’t focus there. They must keep their focus on the airplanes that are taking off and landing on their deck. They have to pay attention to “the messy reality” of what’s actually happening. To improve your focus, refuse to elevate quantitative knowledge above qualitative and experiential knowledge. Weigh both equally. When you have “close calls,” learn the right lessons from them. Close calls don’t prove that the system is working because you didn’t crash. Close calls show that something’s wrong with the system since you almost crashed.
4. HROs develop and maintain “a commitment to resilience” – When the pressure is off, you might be able to believe that you’ve developed a perfect system that will never have to change. HROs know better. They regularly put their systems under incredible stress and unforeseen circumstances do arise. HROs know they have to adapt continually to changing circumstances. Resilience consists of three core capabilities. Your organization is resilient if it can “absorb strain” and keep working, even when things are hard, if it can “bounce back” from crises and if it can learn from them. HRO leaders celebrate when their organizations handle crises well, because it proves their resilience. Encourage people to share what they know and what they learn from crises. Speed up communication. Emphasize reducing the impact of crises. Practice mindfulness. Keep “uncommitted resources” ready to put into action when a crisis erupts. Structure your organization so that those who know what to do in a specific situation can take the lead, rather than hewing to a set hierarchy.
5. HROs practice “deference to expertise” – Avoid assuming that a direct relationship exists between your organization’s formal hierarchy and which person knows best what to do in a crisis. Often specific individuals possess deep expertise or situational knowledge that should leapfrog the hierarchy, so put them in charge of relevant major decisions. To increase your organization’s deference to expertise, focus on what the system knows and can handle, rather than taking pride in what you or any other individual knows and does. Recognize that expertise is “not simply an issue of content knowledge.” Instead, it consists of knowledge plus “credibility, trust and attentiveness.” Recognize and share what you know, even when people don’t want to hear it – but also know your limits and hand off authority when you reach them.
Auditing Your Organization for Mindfulness
You can’t shut your organization down and redesign it as an HRO, so find ways to redesign it while it is functioning. Start by auditing your current practices from numerous perspectives. These audits themselves will increase mindfulness. Ask questions to get people talking. As you review past crises as learning opportunities, you’ll start developing resilience. Study how much people in your organization agree and where agreement clusters. People at HROs tend to agree across their organizations’ different levels, so you have a problem if managers and front line workers disagree. Heed the areas where people disagree most about what to do or how the organization should function. See which aspects of reliability are strengths for you. Do you anticipate problems better (good planning)? Or are you better at containing them (good responsiveness)? Determine which audit findings are upsetting and “where you could be most mindful.”
Ask:
Where are you now? – Examine how mindful your firm is now. Do you actively pay attention to potential problems? Does everyone agree what is most likely to go wrong? Do you all attend to potential problem areas to make the firm more reliable?
How mindless are you? – Do you pressure people to do things the same way all the time or to work without needed information or training? Do you push people to produce without independent discretion? Such practices lead toward mindlessness.
Where do you need to be most mindful? – Things are likelier to go unexpectedly wrong when your processes are “tightly coupled” and “interactively complex,” as in a nuclear power plant. Look for these qualities to see where you need to be most intensely mindful. If you can work in linear units that you fully understand without feedback from one unit to the next, you need comparatively little mindfulness. But, if your processes demand coordination and cooperation, or if you’re a start-up and don’t yet have all of your systems fully in place, feedback must flow. That’s when you need mindfulness most.
Does your organization obsess over failure? – Encourage people to envision things that might go wrong and head them off. Ask yourself how consciously you seek potential failures. When something happens that you didn’t expect, does your organization figure out why? When you barely avoid a catastrophe, do you investigate why things almost went wrong, and learn from them? Do you change procedures to reflect your new understanding? On a simpler level, can people in your organization talk openly about failure? Do they report things that have gone awry?
Does your organization resist simplification? – Rather than assuming that your organization knows itself and has the correct perspective, challenge the routine. This won’t always make for the most comfortable workplace, but you must pay attention to real complexity. What do you take for granted? (Your goal is to be able to answer “nothing.”) Push people to analyze events below the surface. To deepen their understanding, people must trust and respect each other, even when they disagree.
Does your organization focus on operations? – Thinking about the big strategic picture is a lot of fun – but to be resilient, you need to monitor what is actually happening now, rather than assuming things are running smoothly. Seek feedback. Make sure people meet regularly with co-workers organization-wide, so they get a clearer overall picture.
Are you committed to becoming more resilient? – HROs show their commitment to resilience by funding training so people can develop their capacities. You want people to know as many jobs and processes as possible. Besides formal training, encourage people who meet “stretch” goals, use knowledge and solve problems.
Does your organization defer to expertise? – How much do people want to do their jobs well? Do they respect each other and defer to those who know an issue best?
Building a Mindful Organizational Culture
If you’re the only person in your company dedicated to mindfulness, the dominant “organizational culture” will swamp your good intentions. To make your organization more like an HRO, help it adopt an “informed culture” with these “four subcultures”:
1. A “reporting culture” – People share their accounts of what went wrong.
2. A “just culture” – The organization treats people fairly. Define “acceptable and unacceptable” action and do not punish failures that arise from acceptable behavior. When something goes wrong, seek reasons, not scapegoats.
3. A “flexible culture” – If your work is very variable, like fighting fires, don’t depend on a rigid, slow hierarchy. Foster individual discretion and variation instead of uniformity.
4. A “learning culture” – Increase everyone’s capacity; provide opportunities for people to share information.
Your organization’s culture manifests at several levels. It ascends from the level of physical objects, which can symbolize a corporate personality, to linked processes and then up to the level of abstractions, like shared values and assumptions. “Artifacts are the easiest to change, assumptions the hardest.” Top managers must consistently model and communicate the changes they want. State your desired beliefs and practices, give employees feedback and reward those who succeed.
As you move into implementing new activities, follow a “small wins strategy,” focusing on attainable goals. Start with the “after action review” in which people compare what they did in a crisis to what they intended to do, why it differed and how they’ll act in the future. Encourage people to share details, rather than glossing over specifics. Support those who try to be more mindful, since being mindless is so much easier. Help them by verbally reframing objectives. For example, reword current “goals in the form of mistakes that must not occur.” Define what having a “near miss” means and what constitutes “good news.” If no accident report is filed, is that good – or does it mean things are being brushed under the rug? Train people in interpersonal skills and encourage skepticism. To raise awareness of potential glitches, ask employees what unexpected occurrences they’ve seen. Meet with people face to face to get the nuances they communicate nonverbally.
I think the most important concept here is Normalization of Deviance. I think this is the default and expected outcome if an organization tries to import high-reliability practices that are very expensive, that don't fit the problem domain, or that lack the ability to simulate failures. Reporting culture/just culture seems correct and important, and there are a few other interesting lessons, but most stuff is going to fail to transfer.
Most lessons from aviation and medicine won't transfer, because these are well-understood domains where it's feasible to use checklists, and it's reasonable to expect investing in the checklists to help. AI research is mostly not like that. A big risk I see is that people will try to transfer practices that don't fit, and that this will serve to drive symbolic ineffectual actions plus normalization of deviance.
That said, there are a few interesting small lessons that I picked up from watching aviation accident analysis videos, mostly under the label "crew resource management". Commercial airliners are overstaffed to handle the cases where workload spikes suddenly, or someone is screwing up and needs someone else to notice, or someone becomes incapacitated at a key moment. One recurring failure theme in incidents is excessive power gradients within a flight crew: situations where the captain is f*ing up, but the other crewmembers are too timid to point it out. Ie, deference to expertise is usually presented as a failure mode. (This may be an artifact of there being a high minimum bar for the skill level of people in a cockpit, which software companies fail to uphold.)
(Note that I haven't said anything about nuclear, because I think managing nuclear power plants is actually just an easy problem. That is, I think nearly all the safety strategies surrounding nuclear power are symbolic, unnecessary, and motivated by unfounded paranoia.)
(I also haven't said much about medicine because I think hospitals are, in practice, pretty clearly not high-reliability in the ways that matter. Ie, they may have managed to drive the rates of a few specific legible errors down to near zero, but the overall error rate is still high; it would be a mistake to hold up surgical-infection-rate as a sign that hospitals are high-reliability orgs, and not also observe that they're pretty bad at a lot of other things.)
(Note that I haven't said anything about nuclear, because I think managing nuclear power plants is actually just an easy problem. That is, I think nearly all the safety strategies surrounding nuclear power are symbolic, unnecessary, and motivated by unfounded paranoia.)
I think managing a nuclear power plant is relatively easy... but, like, I'd expect managing a regular ol' power plant (or, many other industries) to be pretty easy, and my impression is that random screwups still manage to happen. So it still seems notable to me if nuclear plants avoid the same degree of incidents that other random utility companies have.
I agree many of the safety strategies surrounding nuclear power are symbolic. But I've recently updated away from "yay nuclear power" because while it seems to me the current generation of stuff is just pretty safe and is being sort of unreasonably strangled by regulation... I dunno that I actually expect civilizational competence to continue having it be safe, given how I've seen the rest of civilizational competence playing otu. (I'm not very informed here though)
Prediction: that list of principles was written by a disciple of John Boyd (the OODA loops guy). This same post could just as easily be organizational cliffnotes from Patterns of Conflict.
I also thought these looked similar, so I dedicated a half-hour or so of searching and I could not turn up any relation between either of the authors of the Research Gate summary and Boyd or the military as far as their Wikipedia pages and partial publication lists go. It appears those two have been writing books together on this set of principles since 2001, based on work going back to the 60's and drawing from the systems management literature.
I also checked for some links between Rickover and Boyd, which I thought might be valid because one of Boyd's other areas of achievement was as a ruthless trainer of fighter pilots, which seemed connected through the Navy's nuclear training program. Alas, a couple of shots found them only together in the same document for one generic media article talking about famous ideas from the military.
It sort of looks like Rickover landed on a similar set of principles to Boyd's, but with a goal more like trying to enforce a maximum loop size organization-wide for responding to circumstances.
I wasn't sure at the time the effort I put into this post would be worth it. I spent around 8 hours I think, and I didn't end up with a clear gearsy model of how High Reliability Tends to work.
I did end up following up on this, in "Carefully Bootstrapped Alignment" is organizationally hard. Most of how this post applied there was me including the graph from the vague "hospital Reliability-ification process" paper, in which I argued:
The report is from Genesis Health System, a healthcare service provider in Iowa that services 5 hospitals. No, I don't know what "Serious Safety Event Rate" actually means, the report is vague on that. But, my point here is that when I optimistically interpret this graph as making a serious claim about Genesis improving, the improvements took a comprehensive management/cultural intervention over the course of 8 years.
If you're working at an org that's planning a Carefully Aligned AGI strategy, and your org does not already seem to hit the Highly Reliable bar, I think you need to begin that transition now. If your org is currently small, take proactive steps to preserve a safety-conscious culture as you scale. If your org is large, you may have more people who will actively resist a cultural change, so it may be more work to reach a sufficient standard of safety.
I don't know whether it's reasonable to use the graph in this way (i.e. I assume the graph is exaggerated and confused, but that it still seems suggestive of an lower bound on how long it might take a culture/organizational-practice to shift towards high reliability.
After writing "Carefully Bootstrapped Alignment" is organizationally hard, I spent a couple months exploring and putting some effort into trying to understand why the AI safety focused members of Deepmind, OpenAI and Anthropic weren't putting more emphasis on High Reliability. My own efforts there petered out and I don't know that they were particularly counterfactually helpful.
But, later on Anthropic did announce their Scaling Policy, which included language that seems informed by biosecurity practices (since writing this post, I later went on to interview someone about High Reliability practices in bio, and they described a schema that seems to roughly map onto the Anthropic security levels). I am currently kind on the fence about whether Anthropic's policy has teeth or is more like elaborate Safetywashing, but I think it's at least plausibly a step in the right direction.
Epistemic Effort: Rough notes from a shallow dive. Looked into this for a few hours. I didn't find a strong takeaway but think this is probably a useful jumping-off-point for further work.
Most likely, whether I like it or not, there will someday be AGI research companies working on models that are dangerous to run. Maybe they'll risk an accidental unfriendly hard takeoff. Maybe they'll cross a threshold accelerate us into a hard-to-control multipolar smooth takeoff.[1]
There's some literature on organizations that operate in extremely complex domains, where failure is catastrophic. They're called High Reliability Organizations (HROs). The original work focused on three case studies: A nuclear power plant, an air traffic control company, and a nuclear aircraft carrier (aka nuclear power plant and air traffic control at the same time while people sometimes shoot at you and you can't use radar because you don't want to give away your position and also it's mostly crewed by 20 year olds without much training)
These were notable for a) being extremely complex systems where it would be really easy to screw up catastrophically, and b) somehow, they manage to persistently not screw up.
How do they do that? And does this offer any useful insights to AGI companies?
I started writing this post before Eliezer posted Six Dimensions of Operational Adequacy in AGI Projects. It's not pointed at the exact same problem, but I had a similar generator of "what needs to be true of AI companies, for them to safely work on dangerous tech?". (I think Eliezer had a higher bar in mind with Six Dimensions, which is like, "what is an AI company a researcher could feel actively good about joining")
I was initially pointed in the HRO direction by some conversations with Andrew Critch. Some of his thoughts are written up in the ARCHES report. (There's been some discussion on LessWrong)
My TL;DR after ~10 hours of looking into it:
Principles from "Managing the Unexpected"
The book "Managing the Unexpected", first published in 2001, attempts to answer the question "how can we learn from Highly Reliable Organizations?" in a more general way. I found a summary of the book from researchgate.com which I'm going to quote from liberally. It distills the book down into these points:
I'm not sure how well this all translates to AI research, but the list was interesting enough for me to buy the book. One thing that was quite unclear to me was what the epistemic status of the book was – it prescribes a bunch of interventions on organizational culture, but it doesn't say "we tried these interventions and it worked."
Applications in Hospitals
Fortunately(?), it seems like since the book was first published, there has been a massive effort to port HRO principles over into the hospital industry. (In fact when I googled "High Reliability Organizations", the first several google hits were reports about hospitals saying "Man, we kill people all the time. Why can't we be reliable like those nuclear aircraft carrier people in the HRO literature?"). Some programs started around 2007, and were evaluated in 2018.
According to this report, a collection of organizational interventions resulted in serious safety events dropping to zero over the course of 9 years. They define "Serious Safety Event" as "a deviation from the standard of care that reaches the patient and leads to more than minor or minimal temporary harm".
Notes on the methodology here:
I do notice "deviation from the standard of care" is a kinda vague concept that depends on whatever the standard of care is. But, assuming they held the standard consistent throughout and didn't solve the problem by massive goodharting... it seems Big If True if they drove things down to literally 0. That's at least encouraging on the general level of "we have working examples of industries becoming safer on purpose."
Does any of this translate into "Research" environments?
Nuclear powerplants, air traffic control, aircraft carriers and hospitals all share a property of having pretty clear feedback loops. And while a lot of the point of being an HRO is responding to surprises, they are in some sense attempting roughly the same thing with the same desired outcome repeatedly. If you mess up, an accident is likely to happen pretty quickly.
Some of the principles ("focus on operations rather than strategy", and "the more volatile your work environment, the more important to respond well in the moment") seem more tailored for tactical jobs rather than research companies. (I can imagine smooth takeoff worlds where an AI company does need to respond quickly in the moment to individual things going wrong... but it feels like something has already gone wrong by that point)
Some of the ideas I'd guess would transfer:
I expect this one to be a bit complex...
...because you might have people who are the most competent at AI design but don't have security/alignment mindset.
An interesting one was...
...which actually feels like maybe applies to the broader x-risk/EA ecosystem.
Appendix: Cliff Notes on "Managing the Unexpected"
[The following is from a researchgate summary, which I found pretty annoyingly formatted. I've pretty translated it into LW-Post format to be easier to read]
For some examples, see this short story short story by gwern for gesture how of an AGI experiment might destroy the world accidentally, or Paul Christiano's What failure looks like, or Andrew Critch's What Multipolar Failure Looks Like, and Robust Agent-Agnostic Processes (RAAPs)