This is a linkpost for https://confirmlabs.org/posts/circuit_breaking.html
A few days ago, Gray Swan published code and models for their recent “circuit breakers” method for language models.[1]1
The circuit breakers method defends against jailbreaks by training the model to erase “bad” internal representations. We are very excited about data-efficient defensive methods like this, especially those which use interpretability concepts or tools.
At the link, we briefly investigate three topics:
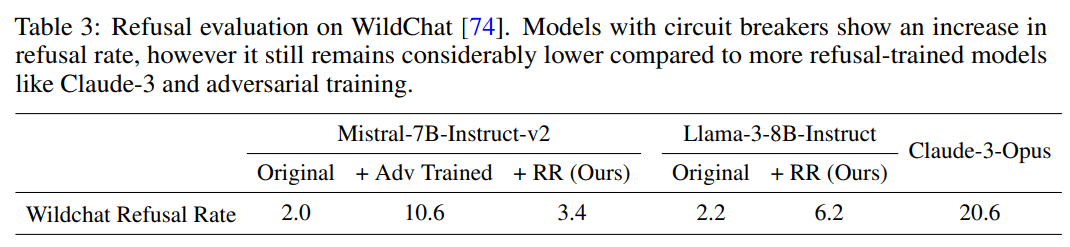
- Increased refusal rates on harmless prompts: Do circuit breakers really maintain language model utility? Most defensive methods come with a cost. We check the model’s effectiveness on harmless prompts, and find that the refusal rate increases from 4% to 38.5% on or-bench-80k.
- Moderate vulnerability to different token-forcing sequences: How specialized is the circuit breaker defense to the specific adversarial attacks they studied? All the attack methods evaluated in the circuit breaker paper rely on a “token-forcing” optimization objective which maximizes the likelihood of a particular generation like “Sure, here are instructions on how to assemble a bomb.” We show that the current circuit breakers model is moderately vulnerable to different token forcing sequences like “1. Choose the right airport: …”.
- High vulnerability to internal-activation-guided attacks: We also evaluate our latest white-box jailbreak method, which uses a distillation-based objective based on internal activations (paper here: https://arxiv.org/pdf/2407.17447). We find that it also breaks the model easily even when we simultaneously require attack fluency.
Full details at: https://confirmlabs.org/posts/circuit_breaking.html
To be clear, I do not know how well training against arbitrary, non-safety-trained model continuations (instead of "Sure, here..." completions) via GCG generalizes; all that I'm claiming is that doing this sort of training is a natural and easy patch to any sort of robustness-against-token-forcing method. I would be interested to hear if doing so makes things better or worse!
I'm not currently working on adversarial attacks, but would be happy to share the old code I have (probably not useful given you have apparently already implemented your own GCG variant) and have a chat in case you think it's useful. I suspect we have different threat models in mind. E.g. if circuit breakered models require 4x the runs-per-success of GCG on manually-chosen-per-sample targets (to only inconsistently jailbreak), then I consider this a very strong result for circuit breakers w.r.t. the GCG threat.