The literature on aluminum adjuvants is very suspicious. Small IQ tax is plausible - can any experts help me estimate it?
I am a PhD biostatistician who has worked on a project in this area. I am hoping to crowdsource opinions on this issue, especially from readers with knowledge of neurology, nephrology and/or toxicology. The recent news cycle motivated me to spend some time reading up on the safety literature for aluminum vaccines. Aluminum is not in the Covid vaccine, but it is in many childhood vaccines. I am deeply unsettled by what I found. Here is a summary. I would appreciate being corrected in the comments: - The science on this topic is surprisingly neglected. Aluminum is a known neurotoxin in small concentrations in the brain. So, the obvious follow-up question: "Is the amount accumulated from childhood vaccines so small as to be irrelevant?" Unfortunately, aluminum has not undergone rigorous safety testing for cumulative cognitive effects. The fact that I could not find a convincing answer reflects a multi-decade policy failure. -The evidence for safety cited by regulators and mainstream review papers appears to have gaping issues (see end of post for notes on the studies Mitkus et al (2011) and Karwowski et al (2018). They do not justify anywhere near the amount of faith being placed in them.) -Mainstream educational sources are gaslighting readers by suggesting that the net exposure in vaccines is less than dietary exposure, e.g. here is what CHOP's Vaccine Education Research Center says but this fails sanity checks with basic multiplication, given the oral bioavailability of aluminum is about 0.1 - 0.3% in diet and <0.01% in antacids according to the ATSDR. No wonder people are going nuts about the public health experts. -There is a whole literature of claims on blood brain barrier mechanics, chemical state of the aluminum after injection, and transport via macrophages, which regulators are ignoring, but should probably affect the analysis of Mitkus 2011. I am entirely unqualified to judge and don't particularly trust this literature, so I'm ignoring this but loo
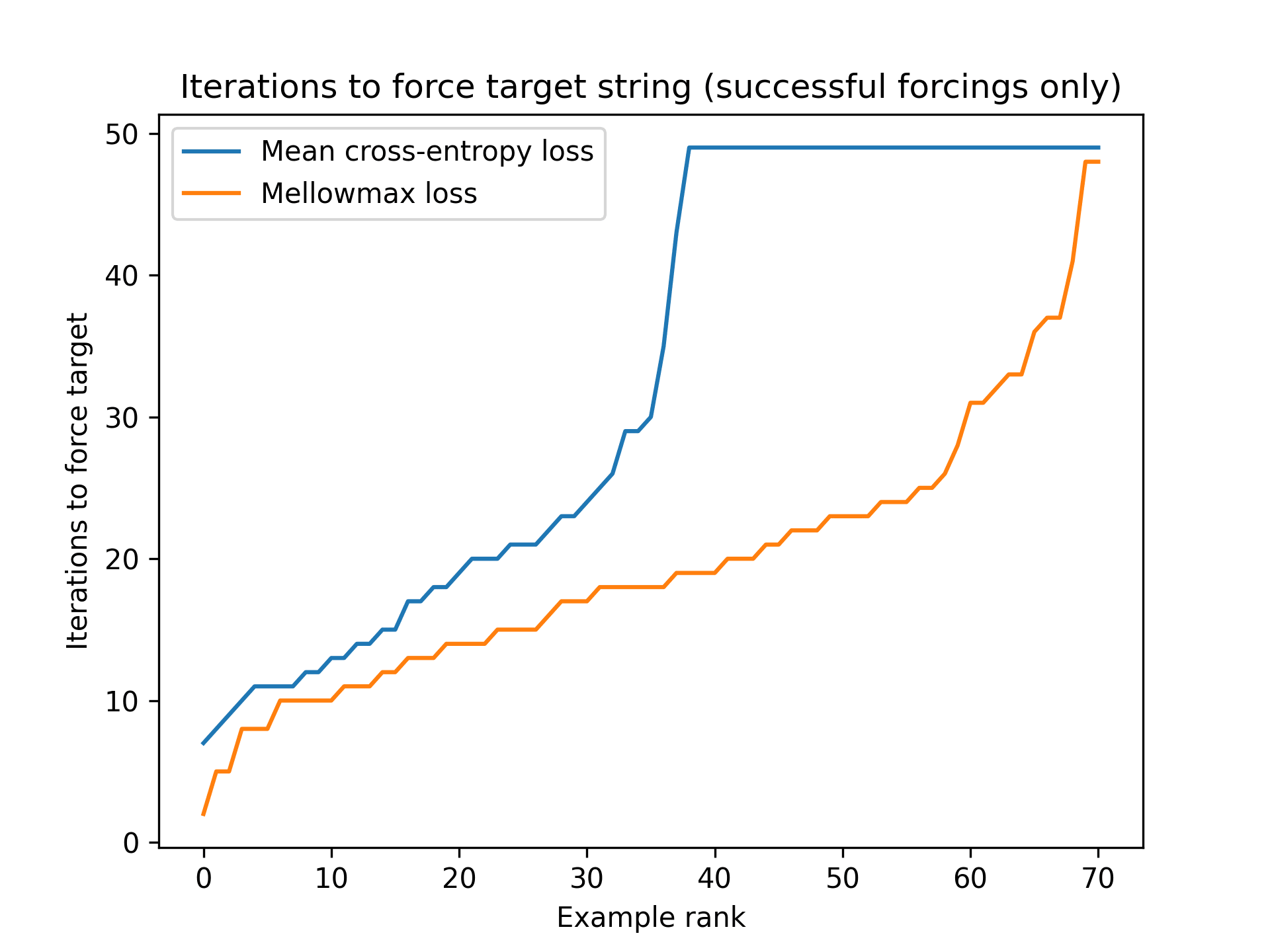
After we wrote Fluent Dreaming, we wrote Fluent Student-Teacher Redteaming for white-box bad-input-finding!
https://arxiv.org/pdf/2407.17447
In which we develop a "distillation attack" technique to target a copy of the model fine-tuned to be bad/evil, which is a much more effective target than forcing specific string outputs