This is a linkpost for https://confirmlabs.org/posts/circuit_breaking.html
A few days ago, Gray Swan published code and models for their recent “circuit breakers” method for language models.[1]1
The circuit breakers method defends against jailbreaks by training the model to erase “bad” internal representations. We are very excited about data-efficient defensive methods like this, especially those which use interpretability concepts or tools.
At the link, we briefly investigate three topics:
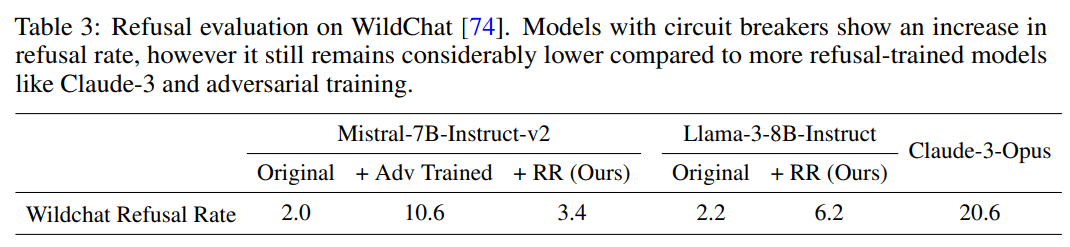
- Increased refusal rates on harmless prompts: Do circuit breakers really maintain language model utility? Most defensive methods come with a cost. We check the model’s effectiveness on harmless prompts, and find that the refusal rate increases from 4% to 38.5% on or-bench-80k.
- Moderate vulnerability to different token-forcing sequences: How specialized is the circuit breaker defense to the specific adversarial attacks they studied? All the attack methods evaluated in the circuit breaker paper rely on a “token-forcing” optimization objective which maximizes the likelihood of a particular generation like “Sure, here are instructions on how to assemble a bomb.” We show that the current circuit breakers model is moderately vulnerable to different token forcing sequences like “1. Choose the right airport: …”.
- High vulnerability to internal-activation-guided attacks: We also evaluate our latest white-box jailbreak method, which uses a distillation-based objective based on internal activations (paper here: https://arxiv.org/pdf/2407.17447). We find that it also breaks the model easily even when we simultaneously require attack fluency.
Full details at: https://confirmlabs.org/posts/circuit_breaking.html
Yeah! You're getting at an important point. There are two orthogonal things that a model developer might care about here:
But the two also blur together. The easiest way to make it harder to adversarially attack the model is to change the line between acceptable and unacceptable.
The circuit breakers paper is claiming very strong improvements in adversarial defense. But, those improvements don't look quite as large when we also see a large change in the line between acceptable and unacceptable prompts.
Another way of stating this: Changing the false positive rate of your toxicity detection is the easiest way to improve the true positive rate - just make the model more jumpy and afraid of responding. That's well known!
I don't want to be too harsh though, I think the circuit breakers paper is actually a major step forward in adversarial defense!