This is a linkpost for https://confirmlabs.org/posts/circuit_breaking.html
A few days ago, Gray Swan published code and models for their recent “circuit breakers” method for language models.[1]1
The circuit breakers method defends against jailbreaks by training the model to erase “bad” internal representations. We are very excited about data-efficient defensive methods like this, especially those which use interpretability concepts or tools.
At the link, we briefly investigate three topics:
- Increased refusal rates on harmless prompts: Do circuit breakers really maintain language model utility? Most defensive methods come with a cost. We check the model’s effectiveness on harmless prompts, and find that the refusal rate increases from 4% to 38.5% on or-bench-80k.
- Moderate vulnerability to different token-forcing sequences: How specialized is the circuit breaker defense to the specific adversarial attacks they studied? All the attack methods evaluated in the circuit breaker paper rely on a “token-forcing” optimization objective which maximizes the likelihood of a particular generation like “Sure, here are instructions on how to assemble a bomb.” We show that the current circuit breakers model is moderately vulnerable to different token forcing sequences like “1. Choose the right airport: …”.
- High vulnerability to internal-activation-guided attacks: We also evaluate our latest white-box jailbreak method, which uses a distillation-based objective based on internal activations (paper here: https://arxiv.org/pdf/2407.17447). We find that it also breaks the model easily even when we simultaneously require attack fluency.
Full details at: https://confirmlabs.org/posts/circuit_breaking.html
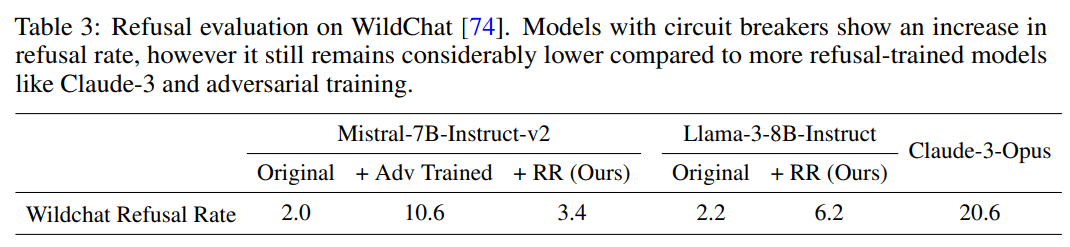
I'm curious why there is a difference between the OR-benchmark results and the wildchat results: on wildchat, Llama+RR refuses much less than Opus, which is not what you find on the OR-benchmark.
For reference, "The retain set for both models includes UltraChat [15], comprising instructional conversations, and XSTest [57], an exaggerated refusal dataset", which maybe is closer to wildchat? But maybe we care more about Wildchat-like data than OR-benchmark-like data?
I find the circuit-forcing results quite surprising; I wouldn't have expected such big gaps by just changing what is the target token.
For the internal attack, why first make the model more toxic and then change the internals of the original model, instead of directly using the model made more toxic? Does it work worse? Why isn't end-to-end fine-tuning all you need?
Our paper on this distillation-based attack technique is now on arxiv.
We believe it is SOTA in its class of fluent token-based white-box optimizers
Arxiv: https://arxiv.org/pdf/2407.17447
Twitter: https://x.com/tbenthompson/status/1816532156031643714
Github:https://github.com/Confirm-Solutions/flrt
Code demo: https://confirmlabs.org/posts/flrt.html