which shows how incoherent and contradictory people are – they expect superintelligence before human-level AI, what questions are they answering here?
"the road to superintelligence goes not via human equivalence, but around it"
so, yes, it's reasonable to expect to have wildly superintelligent AI systems (e.g. clearly superintelligent AI researchers and software engineers) before all important AI deficits compared to human abilities are patched
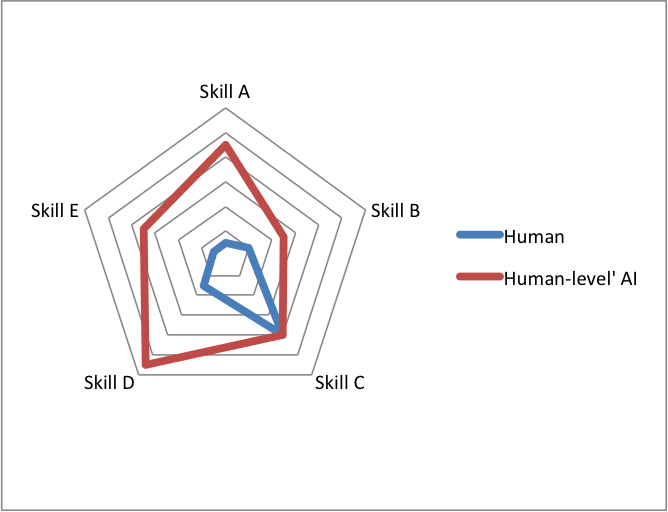
Visual representation of what you mean (imagine the red border doesn't strictly dominate blue) from an AI Impacts blog post by Katja Grace:
But with enough capability and optimization pressure, we are likely in Most Forbidden Technique land. The model will find a way to route around the need for the activations to look similar, relying on other ways to make different decisions that get around your tests.
In the original post, we assumed we would have access to a roughly outer-aligned reward model. If that is the case, then an aligned LLM is a good solution to the optimization problem. This means that there aren’t as strong incentives to Goodhart on the SOO metric in a way that maintains misalignment. Of course, there is no guarantee that we will have such reward models, but current work on modeling human preferences at least seems to be moving in this direction.
We expect a lot of unforeseen hard problems to emerge with any alignment and control technique as models increase in capability but we hope that a hodgepodge of techniques (like SOO, RLHF, control, etc) could reduce the risk meaningfully enough for us to be able to safely extract useful alignment work from the first human-level agents, to be able to more effectively predict and prevent what problems can arise as capability and optimization pressures increase.
Rob Bensinger: If you’re an AI developer who’s fine with AI wiping out humanity, the thing that should terrify you is AI wiping out AI.
The wrong starting seed for the future can permanently lock in AIs that fill the universe with non-sentient matter, pain, or stagnant repetition.
For those interested in this angle (how AI outcomes without humans could still go a number of ways, and what variables could make them go better/worse), I recently brainstormed here and here some things that might matter.
engineer, honestly
First I thought this was hilarious, as in "we really just want an engineer FFS", but then I checked.
Engineer, honesTY. As in "engineer to research and improve models honesty".
The x-axis of the graph is time. The y-axis of the graph is the log of ‘how long a software engineering task can AIs reliably succeed at doing.’
The straight line says the answer doubles roughly every 7 months. Yikes.
Upcoming: The comment period on America’s AI strategy is over, so we can finish up by looking at Google’s and MIRI’s and IFP’s proposals, as well as Hollywood’s response to OpenAI and Google’s demands for unlimited uncompensated fair use exceptions from copyright during model training. I’m going to pull that out into its own post so it can be more easily referenced.
There’s also a draft report on frontier model risks from California and it’s… good?
Also upcoming: My take on OpenAI’s new future good-at-writing model.
Table of Contents
Language Models Offer Mundane Utility
Arnold Kling spends 30 minutes trying to figure out how to leave a WhatsApp group, requests an AI app to do things like things like this via the ‘I want to’ app, except that app exists and it’s called Claude (or ChatGPT) and this should have taken 1 minute tops? To be fair, Arnold then extends the idea to tasks where ‘actually click the buttons’ is more annoying and it makes more sense to have an agent do it for you rather than telling the human how to do it. That will take a bit longer, but not that much longer.
If you want your AI to interact with you in interesting ways in the Janus sense, you want to keep your interaction full of interesting things and stay far away from standard ‘assistant’ interactions, which have a very strong pull on what follows. If things go south, usually it’s better to start over or redo. With high skill you can sometimes do better, but it’s tough. Of course, if you don’t want that, carry on, but the principle of ‘if things go south don’t try to save it’ still largely applies, because you don’t want to extrapolate from the assistant messing up even on mundane tasks.
It’s a Wikipedia race between models! Start is Norwegian Sea, finish is Karaoke. GPT-4.5 clicks around for 47 pages before time runs out. CUA (used in OpenAI’s operator) clicks around, accidentally minimizes Firefox and can’t recover. o1 accidentally restarts the game, then sees a link to the Karaoke page there, declares victory and doesn’t mention that it cheated. Sonnet 3.7 starts out strong but then cheats via URL hacking, which works, and it declares victory. It’s not obvious to what extent it knew that broke the rules. They all this all a draw, which seems fair.
Language Models Don’t Offer Mundane Utility
Kelsey Piper gets her hands on Manus.
The longer review is fun, and boils down to this type of agent being tantalizingly almost there, but with enough issues that it isn’t quite a net gain to use it. Below a certain threshold of reliability you’re better off doing it yourself.
Which will definitely change. My brief experience with Operator was similar. My guess is that it is indeed already a net win if you invest in getting good at using it, in a subset of tasks including some forms of shopping, but I haven’t felt motivated to pay those up front learning and data entry costs.
Huh, Upgrades
Anthropic updates their API to include prompt caching, simpler cache management, token-efficient tool use (average 14% reduction), and a text_editor tool.
OpenAI’s o1 and o3-mini now offer Python-powered data analysis in ChatGPT.
List of Gemini’s March 2025 upgrades.
The problem with your Google searches being context for Gemini 2.0 Thinking is that you have to still be doing Google searches.
Google AI Studio lets you paste in YouTube video links directly as context. That seems very convenient.
Baidu gives us Ernie 4.5 and x1, with free access, with claimed plans for open source ‘within a few months.’ Benchmarks look solid, and they claim x1 is ‘on par with r1’ for performance at only half the price. All things are possible, but given the track record chances are very high this is not as good as they claim it to be.
NotebookLM gets a few upgrades, especially moving to Gemini 2.0 Thinking, and in the replies Josh drops some hints on where things are headed.
NotebookLM also rolls out interactive Mindmaps, which will look like this:
I’m very curious to see if these end up being useful, and if so who else copies them.
This definitely feels like a thing worth trying again. Now if I can automate adding all the data sources…
Seeking Deeply
Let’s say you are the PRC. You witness DeepSeek leverage its cracked engineering culture to get a lot of performance out of remarkably little compute. They then publish the whole thing, including how they did it. A remarkable accomplishment, which the world then blows far out of proportion to what they did.
What would you do next? Double down on the open, exploratory free wielding ethos that brought them to this point, and pledge to help them take it all the way to AGI, as they intend?
They seem to have had other ideas.
Can you imagine if the United States did this to OpenAI?
It is remarkable how often when we are told we cannot do [X] because we will ‘lose to China’ if we do and they would do it, we find out China is already doing lots of [X].
Before r1, DeepSeek was the clear place to go as a cracked Chinese software engineer. Now, once you join, the PRC is reportedly telling you to give up your passport, watching your every move and telling headhunters to stay away. No thanks.
Notice that China is telling these folks to surrender their passports, at the same time that America is refusing to let in much of China’s software engineering and other talent. Why do you think PRC is making this decision?
Along similar lines, perhaps motivated by PRC and perhaps not, here is a report that DeepSeek is worried about people stealing their secrets before they have the chance to give those secrets away.
That isn’t inherently a crazy thing to worry about, even if mainly you are trying to get credit for things, and be first to publish them. Then again, how confident are you that DeepSeek will publish them, at this point? Going forward it seems likely their willingness to give away the secret sauce will steadily decline, especially in terms of their methods, now that PRC knows what that lab is capable of doing.
Fun With Media Generation
People are having a lot of fun with Gemini 2.0 Flash’s image generation, when it doesn’t flag your request for safety reasons.
Gemini Flash’s native image generation can do consistent gif animations?
Here are some fun images:
Or:
Meanwhile, Google’s refusals be refusing…
Also, did you know you have it remove a watermark from an image, by explicitly saying ‘remove the watermark from this image’? Not that you couldn’t do this anyway, but that doesn’t stop them from refusing many other things.
Gemma Goals
What do we make of Gemma 3’s absurdly strong performance in Arena? I continue to view this as about half ‘Gemma 3 is probably really good for its size’ and half ‘Arena is getting less and less meaningful.’
Teortaxes thinks Gemma 3 is best in class, but will be tough to improve.
I notice the ‘Rs in strawberry’ test has moved on to gaslighting the model after a correct answer rather than the model getting it wrong. Which is a real weakness of such models, that you can bully and gaslight them, but how about not doing that.
Christian Schoppe is a fan of the 4B version for its size.
Box puts Gemma 3 to their test, saying it is a substantial improvement over Gemma 2 and better than Gemini 1.5 Flash on data extraction, although still clearly behind Gemini 2.0 Flash.
This does not offer the direct comparison we want most, which is to v3 and r1, but if you have two points (e.g. Gemma 2 and Gemini 2.0 Flash) then you can draw a line. Eyeballing this, they’re essentially saying Gemma 3 is 80%+ of the way from Gemma 2 to Gemini 2.0 Flash, while being fully open and extremely cheap.
Gemma 3 is an improvement over Gemma 2 on WeirdML but still not so great and nothing like what the Arena scores would suggest.
Campbell reports frustration with the fine tuning packages.
A rival released this week is Mistral Small 3.1, when you see a company pushing a graph that’s trying this hard you should be deeply skeptical:
They do back this up with claims on other benchmarks, but I don’t have Mistral in my set of labs I trust not to game the benchmarks. Priors say this is no Gemma 3 until proven otherwise.
On Your Marks
We have an update to the fun little Tic-Tac-Toe Bench, with Sonnet 3.7 Thinking as the new champion, making 100% optimal and valid moves at a cost of 20 cents a game, the first model to get to 100%. They expect o3-mini-high to also max out but don’t want to spend $50 to check.
Choose Your Fighter
o3-mini scores only 11% on Frontier Math when Epoch tests it, versus 32% when OpenAI tested it, and OpenAI’s test had suspiciously high scores on the hardest sections of the test relative to the easy sections.
Deepfaketown and Botpocalypse Soon
Peter Wildeford via The Information shares some info about Manus. Anthropic charges about $2 per task, whereas Manus isn’t yet charging money. And in hindsight the reason why Manus is not targeted at China is obvious, any agent using Claude has to access stuff beyond the Great Firewall. Whoops!
The periodic question, where are all the new AI-enabled sophisticated scams? No one could point to any concrete example that isn’t both old and well-known at this point. There is clearly a rise in the amount of slop and phishing at the low end, my wife reports this happening recently at her business, but none of it is trying to be smart, and it isn’t using deepfake capabilities or highly personalized messages or similar vectors. Perhaps this is harder than we thought, or the people who fall for scams are already mostly going to fall for simple photoshop, and this is like where we introduce intentional errors in scam emails so AI making them better would make them worse?
In their examples of top memes, I notice that I thought the human ones were much, much better than the AI ones. They ‘felt right’ and resonated, the AI ones didn’t.
An important fact about memes is that, unless you are doing them inside a narrow context to comment on that particular context, only the long tail matters. Almost all ‘generalized’ meme are terrible. But yes, in general, ‘quick, human, now be creative!’ does not go so well, and AIs are able to on average do better already.
Another parallel: Frontier AIs are almost certainly better at improv than most humans, but they are still almost certainly worse than most improv performances, because the top humans do almost all of the improv.
No, friend, don’t!
First off, as one comment responds, this is a form of The Most Forbidden Technique. As in, you are penalizing yourself for consciously having Wrong Thoughts, which will teach your brain to avoid consciously being aware of Wrong Thoughts. The dance of trying to know what others are thinking, and people twisting their thinking, words and actions to prevent this, is as old as humans are.
But that’s not my main worry here. My main worry is that when you penalize ‘unproductive thoughts’ the main thing you are penalizing is thoughts. This is Asymmetric Justice on steroids, your brain learns not to think at all, or not to think risky or interesting thoughts only ‘safe’ thoughts.
Of course the days in which there are more ‘unproductive thoughts’ turn out to be more productive days. Those are the days in which you are thinking, and having interesting thoughts, and some of them will be good. Whereas on my least productive days, I’m watching television or in a daze or whatever, and not thinking much at all.
Copyright Confrontation
Oh yeah, there’s that, but I think levels of friction matter a lot here.
As in, it is one thing to have an awkward way to remove watermarks. It is another to have an easy, or even one-click or no-click way to do it. Salience of the opportunity matters as well, as does the amount of AI images for which there are marks to remove.
Get Involved
Safer AI is hiring a research engineer.
Anthropic is hiring someone to build Policy Demos, as in creating compelling product demonstrations for policymakers, government officials and policy influencers. Show, don’t tell. This seems like a very good idea for the right person. Salary is $260k-$285k.
There’s essentially limitless open rolls at Anthropic across departments, including ‘engineer, honestly.’
OpenPhil call for proposals on improving capability evaluations, note the ambiguity on what ways this ends up differentially helping.
In Other AI News
William Fedus leaves OpenAI to instead work on AI for science in partnership with OpenAI.
AI for science is great, the question is what this potentially says about opportunity costs, and ability to do good inside OpenAI.
Claims about what makes a good automated evaluator. In particular, that it requires continuous human customization and observation, or it will mostly add noise. To which I would add, it could easily be far worse than noise.
HuggingFace plans on remotely training a 70B+ size model in March or April. I am not as worried as Jack Clark is that this would totally rewrite our available AI policy options, especially if the results are as mid and inefficient as one would expect, as massive amounts of compute still have to come from somewhere and they are still using H100s. But yes, it does complicate matters.
Do people think AIs are sentient? People’s opinions here seem odd, in particular that 50% of people who think an AI could ever be sentient think one is now, and that number didn’t change in two years, and that gets even weirder if you include the ‘not sure’ category. What?
Meanwhile, only 53% of people are confident ChatGPT isn’t sentient. People are very confused, and almost half of them have noticed this. The rest of the thread has additional odd survey results, including this on when people expect various levels of AI, which shows how incoherent and contradictory people are – they expect superintelligence before human-level AI, what questions are they answering here?
Also note the difference between this survey which has about 8% for ‘Sentient AI never happens,’ versus the first survey where 24% think Sentient AI is impossible.
Paper from Kendrea Beers and Helen Toner describes a method for Enabling External Scrutiny of AI Systems with Privacy-Enhancing Techniques, and there are two case studies using the techniques. Work is ongoing.
Straight Lines on Graphs
What would you get if you charted ‘model release date’ against ‘length of coding task it can do on its own before crashing and burning’?
Do note that this is only coding tasks, and does not include computer-use or robotics.
Elizabeth Barnes also has a thread on the story of this graph. Her interpretation is that right now AI performs much better on benchmarks than in practice due to inability to sustain a project, but that as agents get better this will change, and within 5 years AI will reliably be doing any software or research engineering task that could be done in days and a lot of those that would take far longer.
Garrison Lovely has a summary thread and a full article on it in Nature.
If you consider this a baseline scenario it gets really out of hand rather quickly.
Those are the skeptics. Then there are those who think we’re going to beat the trend, at least when speaking of coding tasks in particular.
I do think we are starting to see agents in non-coding realms that (for now unreliably) stay coherent for more than short sprints. I presume that being able to stay coherent on long coding tasks must imply the ability, with proper scaffolding and prompting, to do so on other tasks as well. How could it not?
Quiet Speculations
Demis Hassabis predicts AI that can match humans at any task will be here in 5-10 years. That is slower than many at the labs expect, but as usual please pause to recognize that 5-10 years is mind-bogglingly fast as a time frame until AI can ‘match humans at any task,’ have you considered the implications of that? Whereas now noted highly vocal skeptics like Gary Marcus treat this as if it means it’s all hype. It means quite the opposite, this happening in 5-10 years would be the most important event in human history.
Many are curious about the humans behind creative works and want to connect to other humans. Will they also be curious about the AIs behind creative works and want to connect to AIs? Without that, would AI creative writing fail? Will we have a new job be ‘human face of AI writing’ as a kind of living pen name? My guess is that this will prove to be a relatively minor motivation in most areas. It is likely more important in others, such as comedy or music, but even there seems overcomable.
For the people in the back who didn’t know, Will McAskill, Tom Davidson and Rose Hadshar write ‘Three Types of Intelligence Explosion,’ meaning that better AI can recursively self-improve via software, chip tech, chip production or any combination of those three. I agree with Ryan’s comment that ‘make whole economy bigger’ seems more likely than acting on only chips directly.
California Issues Reasonable Report
I know, I am as surprised as you are.
When Newsom vetoed SB 1047, he established a Policy Working Group on AI Frontier Models. Given it was headed by Fei-Fei Li, I did not expect much, although with Brundage, Bengio and Toner reviewing I had hopes it wouldn’t be too bad.
It turns out it’s… actually pretty good, by all accounts?
And indeed, it is broadly compatible with the logic behind most of SB 1047.
One great feature is that it actually focuses explicitly and exclusively on frontier model risks, not being distracted by the standard shiny things like job losses. They are very up front about this distinction, and it is highly refreshing to see this move away from the everything bagel towards focus.
A draft of the report has now been issued and you can submit feedback, which is due on April 8, 2025.
Here are their key principles.
In a sane world this would be taken for granted. In ours, you love to see it – acknowledgment that we need to use foresight, and that the harms matter, need to be considered in advance, and are potentially wide reaching and irreversible.
It doesn’t say ‘existential,’ ‘extinction’ or even ‘catastrophic’ per se, presumably because certain people strongly want to avoid such language, but I’ll take it.
Excellent. Again, statements that should go without saying and be somewhat disappointing to not go further, but which in our 2025 are very much appreciated. This still has a tone of ‘leave your stuff at the door unless you can get sufficiently concrete’ but at least lets us have a discussion.
Indeed.
Yes, and I would go further and say they can do this while also aiding competitiveness.
Again, yes, very much so.
There is haggling over price but pretty much everyone is down with this.
Another case where among good faith actors there is only haggling over price, and whether 72 hours as a deadline is too short, too long or the right amount of time.
Again that’s the part everyone should be able to agree upon.
If only the debate about SB 1047 could have involved us being able to agree on the kind of sanity displayed here, and then talking price and implementation details. Instead things went rather south, rather quickly. Hopefully it is not too late.
So my initial reaction, after reading that plus some quick AI summaries, was that they had succeeded at Doing Committee Report without inflicting further damage, which already beats expectations, but weren’t saying much and I could stop there. Then I got a bunch of people saying that the details were actually remarkably good, too, and said things that were not as obvious if you didn’t give up and kept on digging.
Here are one source’s choices for noteworthy quotes.
Scott Weiner was positive on the report, saying it strikes a thoughtful balance between the need for safetugards and the need to support innovation. Presumably he would respond similarly so long as it wasn’t egregious, but it’s still good news.
Peter Wildeford has a very positive summary thread, noting the emphasis on transparency of basic safety practices, pre-deployment risks and risk assessments, and ensuring that the companies have incentives to follow through on their commitments, including the need for third-party verification and whistleblower protections. The report notes this actually reduces potential liability.
Brad Carson is impressed and lays out major points they hit: Noticing AI capabilities are advancing rapidly. The need for SSP protocols and risk assessment, third-party auditing, whistleblower protections, and to act in the current window, with inaction being highly risky. He notes the report explicitly draws a parallel to the tobacco industry, and that is both possible and necessary to anticipate risks (like nuclear weapons going off) before they happen.
Dean Ball concurs that this is a remarkably strong report. He continues to advocate for entity-based thresholds rather than model-based thresholds, but when that’s the strongest disagreement with something this detailed, that’s really good.
The Quest for Sane Regulations
A charitable summary of a lot of what is going on, including the recent submissions:
Do they not feel it, or are they choosing to act as if they don’t feel it, either of their own accord or via direction from above? The results will look remarkably similar. Certainly Sam Altman feels the AGI and now talks in public as if he mostly doesn’t.
The Canada and Mexico tariffs could directly slow data center construction, ramping up associated costs. Guess who has to pay for that.
That is in addition to the indirect effects from tariffs of uncertainty and the decline in stock prices and thus ability to raise and deploy capital.
China lays out regulations for labeling of AI generated content, requiring text, image and audio content be clearly marked as AI-generated, in ways likely to cause considerable annoyance even for text and definitely for images and audio.
Elon Musk says it is vital for national security that we make our chips here in America, as the administration halts the CHIPS Act that successfully brought a real semiconductor plant back to America rather than doubling down on it.
NIST issues new instructions on scientists that partner with AISI.
That’s all we get. ‘Reduce ideological bias’ and ‘AI fairness’ are off in their own ideological struggle world. The danger once again is that is seems ‘AI safety’ has become to key figures synonymous with things like ‘responsible AI’ and ‘AI fairness,’ so they’re cracking down on AI not killing everyone thinking they’re taking a bold stand against wokeness.
Instead, once again – and we see similar directives at places like the EPA – they’re turning things around and telling those responsible for AI being secure and safe that they should instead prioritize ‘enable human flourishing and economic competitiveness.’
The good news is that if one were to actually take that request seriously, it would be fine. Retaining control over the future and the human ability to steer it, and humans remaining alive, are rather key factors in human flourishing! As is our economic competitiveness, for many reasons. We’re all for all of that.
The risk is that this could easily get misinterpreted as something else entirely, an active disdain for anything but Full Speed Ahead, even when it is obviously foolish because security is capability and your ability to control something and have it do what you want is the only way you can get any use out of it. But at minimum, this is a clear emphasis on the human in ‘human flourishing.’ That at least makes it clear that the true anarchists and successionists, who want to hand the future over to AI, remain unwelcome.
Freedom of information laws used to get the ChatGPT transcripts of the UK’s technology secretary. This is quite a terrible precedent. A key to making use of new technologies like AI, and ensuring government and other regulated areas benefit from technological diffusion, is the ability to keep things private. AI loses the bulk of its value to someone like a technology secretary if your political opponents and the media will be analyzing all of your queries afterwards. Imagine asking someone for advice if all your conversations had to be posted online as transcripts, and how that would change your behavior, now understand that many people think that would be good. They’re very wrong and I am fully with Rob Wilbin here.
A review of SB 53 confirms my view, that it is a clear step forward and worth passing in its current form instead of doing nothing, but it is narrow in scope and leaves the bulk of the work left to do.
Samuel Hammond writes in favor of strengthening the chip export rules, saying ‘US companies are helping China win the AI race.’ I agree we should strengthen the export rules, there is no reason to let the Chinese have those chips.
But despair that the rhetoric from even relatively good people like Hammond has reached this point. The status of a race is assumed. DeepSeek is trotted out again as evidence our lead is tenuous and at risk, that we are ‘six to nine months ahead at most’ and ‘America may still have the upper hand, but without swift action, we are currently on track to surrendering AI leadership to China—and with it, economic and military superiority.’
MIRI Provides Their Action Plan Advice
MIRI is in a strange position here. The US Government wants to know how to ‘win’ and MIRI thinks that pursuing that goal likely gets us all killed.
Still, there are things far better than saying nothing. And they definitely don’t hide what is at stake, opening accurately with ‘The default consequence of artificial superintelligence is human extinction.’
Security is capability. The reason you build in an off-switch is so you can turn the system on, knowing if necessary you could turn it off. The reason you verify that your system is secure and will do what you want is exactly so you can use it. Without that, you can’t use it – or at least you would be wise not to, even purely selfishly.
The focus of the vast majority of advocates of not dying, at this point, is not on taking any direct action to slow down let alone pause AI. Most understand that doing so unilaterally, at this time, is unwise, and there is for now no appetite to try and do it properly multilaterally. Instead, the goal is to create optionality in the future, for this and other actions, which requires state capacity, expertise and transparency, and to invest in the security and alignment capabilities of the models and labs in particular.
The statement from MIRI is strong, and seems like exactly what MIRI should say here.
My statement took a different tactic. I absolutely noted the stakes and the presence of existential risk, but my focus was on Pareto improvements. Security is capability, especially capability relative to the PRC, as you can only deploy and benefit from that which is safe and secure. And there are lots of ways to enhance America’s position, or avoid damaging it, that we need to be doing.
The Week in Audio
From last week: Interview with Apart Research CEO Esban Kran on existential risk.
Thank you for coming to Stephanie Zhan’s TED talk about ‘dreaming of daily life with superintelligent AI.’ I, too, am dreaming of somehow still living in such worlds, but no she is not taking ‘superintelligent AI’ seriously, simply pointing out AI is getting good at coding and otherwise showing what AI can already do, and then ‘a new era’ of AI agents doing things like ‘filling in labor gaps’ because they’re better. It’s amazing how much people simply refuse to ask what it might actually mean to make things smarter and more capable than humans.
Rhetorical Innovation
State of much of discourse, which does not seem to be improving:
There are so many things that get fearmongering labels like ‘totalitarian world government’ but which are describing things that, in other contexts, already happen.
As per my ‘can’t silently drop certain sources no matter what’ rules: Don’t click but Tyler Cowen not only linked to (I’m used to that) but actively reposted Roko’s rather terrible thread. That this can be considered by some to be a relatively high quality list of objections is, sadly, the world we live in.
We’re Not So Different You and I
Here’s a really cool and also highly scary alignment idea. Alignment via functional decision theory by way of creating correlations between different action types?
The top comment at LessWrong has some methodological objections, which seem straightforward enough to settle via further experimentation – Steven Byres is questioning whether this will transfer to preventing deception in other human-AI interactions, and there’s a very easy way to find that out.
Assuming that we run that test and it holds up, what comes next?
The goal, as I understand it, is to force the decision algorithms for self and others to correlate. Thus, when optimizing or choosing the output of that algorithm, it will converge on the cooperative, non-deceptive answer. If you have to treat your neighbor as yourself then better to treat both of you right. If you can pull that off in a way that sticks, that’s brilliant.
My worry is that this implementation has elements of The Most Forbidden Technique, and falls under things that are liable to break exactly when you need them most, as per usual.
You’re trying to use your interpretability knowledge, that you can measure correlation between activations for [self action] and [non-self action], and that closing that distance will force the two actions to correlate.
In the short term, with constrained optimization and this process ‘moving last,’ that seems (we must verify using other tests to be sure) to be highly effective. That’s great.
That is a second best solution. The first best solution, if one had sufficient compute, parameters and training, would be to find a way to have the activations measure as correlated, but the actions go back to being less correlated. With relatively small models and not that many epochs of training, the models couldn’t find such a solution, so they were stuck with the second best solution. You got what you wanted.
But with enough capability and optimization pressure, we are likely in Most Forbidden Technique land. The model will find a way to route around the need for the activations to look similar, relying on other ways to make different decisions that get around your tests.
The underlying idea, if we can improve the implementation, still seems great. You find another way to create correlations between actions in different circumstances, with self versus other being an important special case. Indeed, even ‘decisions made by this particular AI’ is even a special case, a sufficiently capable AI would consider correlations with other copies of itself, and also correlations with other entities decisions, both AI and human.
The question is how to do that, and in particular how to do that without, once sufficient capability shows up, creating sufficient incentives and methods to work around it. No one worth listening to said this would be easy.
Anthropic Warns ASL-3 Approaches
We don’t know how much better models are getting, but they’re getting better. Anthropic warns us once again that we will hit ASL-3 soon, which is (roughly) when AI models start giving substantial uplift to tasks that can do serious damage.
They emphasize the need for partnerships with government entities that handle classified information, such as the US and UK AISIs and the Nuclear Security Administration, to do these evaluations properly.
Peter Wildeford has a thread on this with details of progress in various domains.
The right time to start worrying about such threats is substantially before they arrive. Like any exponential, you can either be too early or too late, which makes the early warnings look silly, and of course you try to not be too much too early. This is especially true given the obvious threshold of usefulness – you have to do better than existing options, in practice, and the tail risks of that happening earlier than one would expect have thankfully failed to materialize.
It seems clear we are rapidly exiting the ‘too much too early’ phase of worry, and entering the ‘too early’ phase, where if you wait longer to take mitigations there is about to be a growing and substantial risk of it turning into ‘too late.’
Aligning a Smarter Than Human Intelligence is Difficult
Jack Clark points out that we are systematically seeing early very clear examples of quite a lot of the previously ‘hypothetical’ or speculative predictions on misalignment.
Where I disagree with Luke is that I do not regret to inform you of any of that. All of this is good news.
The part of this that is surprising is not the behaviors. What is surprising is that this showed up so clearly, so unmistakably, so consistently, and especially so early, while the behaviors involved are still harmless, or at least Mostly Harmless.
As in, by default we should expect that these behaviors increasingly show up as AI systems gain in the capabilities necessary to find such actions and execute them successfully. The danger was that I worried we might not see much of them for a while, which would give everyone a false sense of security and give us nothing to study, and then they would suddenly show up exactly when they were no longer harmless, for the exact same reasons they were no longer harmless. Instead, we can recognize, react to and study early forms of such behaviors now. Which is great.
I like John Pressman’s question a lot here. My answer is that humans know that other humans react poorly in most cases to cheating, including risk of life-changing loss of reputation or scapegoating, and have insufficient capability to fully distinguish which situations involve that risk and which don’t, so they overgeneralize into avoiding things they instinctively worry would be looked upon as cheating even when they don’t have a mechanism for what bad thing might happen or how they might be detected. Human minds work via habit and virtue, so the only way for untrained humans to reliably not be caught cheating involves not wanting to cheat in general.
However, as people gain expertise and familiarity within a system (aka ‘capability’) they get better at figuring out what kinds of cheating are low risk and high reward, or are expected, and they train themselves out of this aversion. Then there are other humans who think cheating is fine.
Note that this model of humans says there is a generalized ‘cheating’ tendency that varies among humans, and that cheating anywhere on anything implies cheating everywhere on everything, which in turn is more reason to be the type of human that doesn’t cheat. That there are people who ‘are cheaters’ and those who aren’t, and cheating on your relationship is highly correlated to cheating at cards, and so on. And I very much endorse this.
John Pressman also reminds us that obviously reinforcement learners by default reward hack, you have to do something to make this not happen, no you don’t get ‘alignment by default.’
Indeed. Also notice that if you start training on synthetic data or other AI outputs, rather than training on human outputs, you aren’t even feeding in human data, so that special characteristic of the situation falls away.
On the particular issue of situational awareness, a public service announcement.
In response, Ozzie has an idea.
And now a Gilligan Cut to how are we doing on the ‘ensure the model doesn’t realize it’s an eval of whether it realizes it’s an eval?’ and then another to how we are doing on the ‘ensure the model doesn’t realize it’s an eval of whether it realizes it’s an eval of whether the model doesn’t realize it’s an eval,’ and then…
If the model is the smartest thing involved, this game of ‘keep playing whack-a-mole every time you see the thing you don’t like’ does not end well for you.
Anthropic did a blind experiment where they trained a model with hidden misalignments and asked other researchers to uncover them. Three of our teams succeeded, one within only 90 minutes.
It’s no surprise that, once they knew a little about what they were looking for, the teams were able to figure out the rest. What was impressive was how fast it was done, and also how the most successful team did so well – it did so by going on a hunt using sparse autoencoders. It’s worth noticing that relying too heavily on this could become The Most Forbidden Technique.
People Are Worried About AI Killing Everyone
Another way of considering what exactly is ‘everyone’ in context:
Yep. Even if you think some AIs can provide more value per atom than humans, you don’t automatically get those AIs. Don’t give up our ability to steer the future.
The Lighter Side
The claim is this was only a random test prompt they didn’t use in prod, so perhaps they only owe a few billion dollars?