If the code uses other code you've written, how do you ensure all dependencies fit within the context window? Or does this only work for essentially dependencyless code?
At this stage, the tool doesn't make assumptions about the context size, also because you can use any LLM. I rarely pass the whole project to Unvibe: I just make it iterate on a module/folder of the project: basically anything that is touched by the unit-tests. This is also what you'd do as a developer.
But an idea for larger "folders" could be to put in the prompt just the definitions of functions/classes, without the actual code. In general, I try to work at the margin, assuming LLMs will get more accurate and the context will keep growing. "Write code as if the LLM that comes out in 2 years exists already and ignore the details" has been a good heuristic.
Am I correct in thinking that you posted this a couple of days ago (with a different title - now deleted), and this version has no substantial changes?
Yes! The reason being that when you do your first post it takes ~2 days to get it actually published: by virtue of the LW sorting algorithm, nobody saw it because it's "old" by the time it's out. I'm happy I got some feedback now
I love this approach, I think it very much relates to how systems need good ground truth signals and how verification mechanisms are part of the core thing we need for good AI systems.
I would be very interested in setting more of this up as infrastructure for better coding libraries and similar for the AI Safety research ecosystem. There's no reason why this shouldn't be a larger effort for alignment research automation. I think it relates to some of the formal verification stuff but it is to some extent the abstraction level above it and so if we want efficient software systems that can be integrated into formal verification I see this as a great direction to take things in.
For what it's worth I do something pretty similar to this using Claude Code. I can just point it at the tests and say "hey, make the code make this pass" and it will come up with something, although the something isn't always what I want if the tests are underspecified!
That is very important, in fact Unvibe passes the source code of tests to the LLM. But in the latent space of the LLM there are many possibile implementations that the LLM doesn't know how to distinguish. Having the unit tests score as ground truth helps a lot
Original Article: https://claudio.uk/posts/unvibe.html
In my daily work as software consultant I'm often dealing with large pre-existing code bases. I use GitHub Copilot a lot. It's now basically indispensable, but I use it mostly for generating boilerplate code, or figuring out how to use a third-party library.
As the code gets more logically nested though, Copilot crumbles under the weight of complexity. It doesn't know how things should fit together in the project.
Other AI tools like Cursor or Devin, are pretty good at generating quickly working prototypes, but they are not great at dealing with large existing codebases, and they have a very low success rate for my kind of daily work.
You find yourself in an endless loop of prompt tweaking, and at that point, I'd rather write the code myself with the occasional help of Copilot.
Professional coders know what code they want, we can define it with unit-tests, we don't want to endlessly tweak the prompt. Also, we want it to work in the larger context of the project, not just in isolation.
Beyond the hype, there is the general knowledge that LLMs are really good for coding, but something is missing in the current paradigms to make LLMs develop large and complex software systems in autonomy.
In this article I am going to introduce a pretty new approach (at least in literature), and a Python library that implements it called Unvibe.
My basic intuition is this: shouldn't we be able to drastically speed up the generation of valid programs, while ensuring correctness, by using unit-tests as reward function for a search in the space of possible programs?
Like for finding Mathematical proofs, or for winning at Go, we need to ultimately tree-search large space, but we can use Neural networks to trim the tree and evaluate sub-branches. I'd like to suggest that, if we look at professional programmers at work, they already use a combination of sophisticated IDEs, GitHub Copilot, and Unit-Tests to "trim" the search space and quickly estimate more promising sub-branches.
I looked in the academic literature, it's not new: it's reminiscent of the
approach used in DeepMind FunSearch, AlphaProof, AlphaGeometry and other experiments like TiCoder: see Research Chapter for pointers to relevant papers.
Writing correct code is akin to solving a mathematical theorem. We are basically proving a theorem using Python unit-tests instead of Lean or Coq as an evaluator.
For people that are not familiar with Test-Driven development, read here about TDD and Unit-Tests.
How it works
I've implemented this idea in a Python library called Unvibe. It implements a variant of Monte Carlo Tree Search that invokes an LLM to generate code for the functions and classes in your code that you have decorated with @ai.
Unvibe supports most of the popular LLMs: Ollama, OpenAI, Claude, Gemini, DeepSeek.
Unvibe uses the LLM to generate a few alternatives, and runs your unit-tests as a test runner (like pytest or unittest). It then feeds back the errors returned by failing unit-test to the LLMs, in a loop that maximizes the number of unit-test assertions passed. This is done in a sort of tree search, that tries to balance
exploitation and exploration.
As explained in the DeepMind FunSearch paper, having a rich score function is key for the success of the approach: You can define your tests by inheriting the usual unittests.TestCase class, but if you use unvibe.TestCase instead you get a more precise scoring function (basically we count up the number of assertions passed rather than just the number of tests passed).
It turns out that this approach works very well in practice, even in large existing code bases, provided that the project is decently unit-tested. This is now part of my daily workflow:
1. Use Copilot to generate boilerplate code
2. Define the complicated functions/classes I know Copilot can't handle
3. Define unit-tests for those complicated functions/classes (quick-typing with GitHub Copilot)
4. Use Unvibe to generate valid code that pass those unit-tests
It also happens quite often that Unvibe find solutions that pass most of the tests but not 100%: often it turns out some of my unit-tests were misconceived, and it helps figure out what I really wanted.
An example
Just to give you the sense of how it works, after you install the module with pip install unvibe, you then decorate the functions/classes you want to generate with @ai. Type annotations and proper comments do help the LLM figure out what you want. Let's try implement for example a small Python-compatible Lisp interpreter:
Now let's define a few unit-tests to specify the behaviour of the function.
Here Copilot can help us come up quickly with a few test cases.
As you can see, we are looking to implement a Lisp interpreter that supports basic
python functions (e.g. range) and returns python-compatible lists.
This simple Lisp interpreter is a good example because it's the sort
of function that LLMs (even reasoning models) cannot generate from scratch, but they can get there with Unvibe:
Now if we can run the search algorithm:
Unvibe will run until it reaches a maximum number of iterations or until it finds a solution that passes all the tests, in which case it will stop early.
The output will be written to a local file unvibe_lisp_<timestamp>.py:
As you can see, Unvibe has found a valid implementation. At this point, in my typical workflow, I would now add more tests and eventually let Unvibe find other solutions.
For more details on how to configure Unvibe to try it yourself, se the GitHub Project page.
Which models work best
The models that I've found work best, are either small coding models (~7B params), or large generic models (>20B params). My favourite for models for Unvibe are:
- qwen2.5-coder:7b: It's available on Ollama, it runs great on my Macbook M2, and it's very good at coding.
- Claude Haiku: probably the cheapest model that is good at coding.
- Claude Sonnet 3.7: probably the best coding model
These are the models that I manage to pass all my Unit-Tests with (yes, unit-tests for a unit-testing library).
Reasoning models can help sometimes, but in practice they are slower. I prefer to try my luck with small local models then switch to Sonnet 3.7 if I don't get good results.
As a future improvement it would be nice to support multiple models, and have Unvibe swap between them if the score plateaus. Maybe a sort of Model Ladder: try at first with small cheap models, and then gradually escalate to larger/more expensive ones if the score doesn't improve as you go down the search tree.
Search algorithm
There are multiple approaches to search the space of possible programs. With Unvibe I tried to strike for something
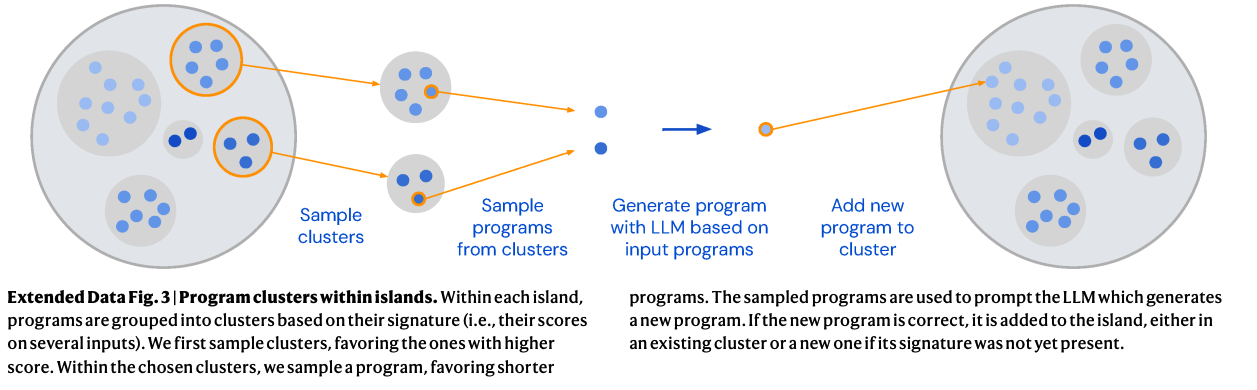
that works in practice without requiring a GPU cluster. The idea was that it should be practical to run it only using a Macbook and Ollama.
DeepMind's FunSearch, which was designed to find mathematical discoveries via program search, uses a variation of Genetic programming with LLMs.
It splits the code generation attempts into Islands of clusters, and let the clusters evolve (via partial code substitution), and then samples from the clusters with higher
scores. They basically sample from the clusters with probability = Softmax of the scores (corrected by some temperature).
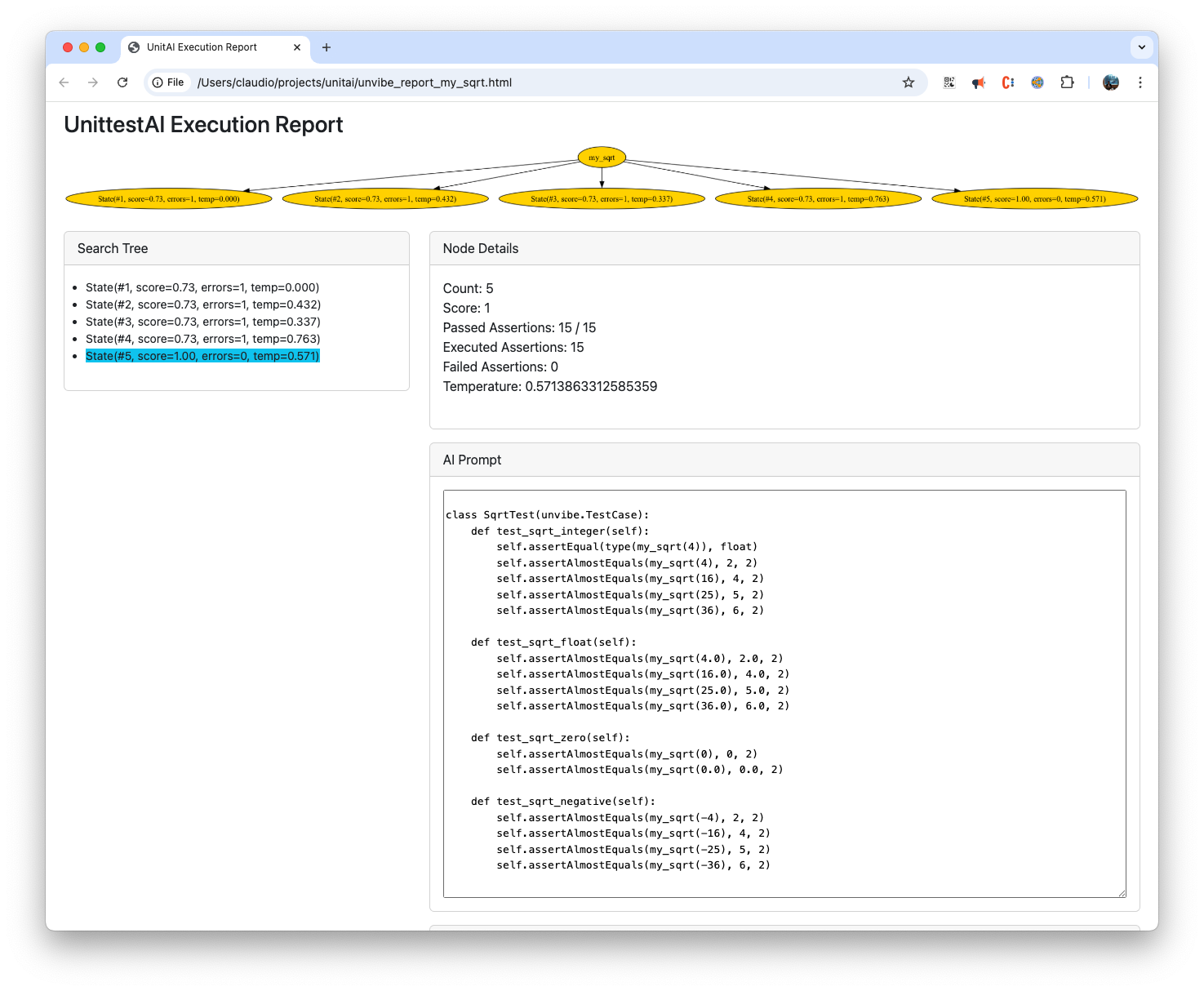
FunSearch is supposed to work on large datacenters. For Unvibe instead I use currently a much simpler tree search: We start with a random initial tree spread,
attempting different LLM temperatures and then, we pick the most promising nodes and try again. This is much more suitable for running on a Macbook.
So you end up with a search tree that looks like this:
Research
Similar approaches have been explored in various research papers from DeepMind and Microsoft Research:
A Note from the Author
I'm a solo Software Engineer, I'd be happy to discuss with any company or institution willing to help expand this project. Obvious developments are: native support for other programming languages, support for adaptive model-swapping down the search tree, and genetic-programming-style line edits. Feel free to contact me if you'd like to collaborate.