I think the RLHF solves 80% of the problems of outer alignment, and I expect it to be part of the solution.
But :
- RLHF doesn't fully solve the difficult problems, which are beyond human supervision, i.e. the problems where even humans don't know what is the right way to do
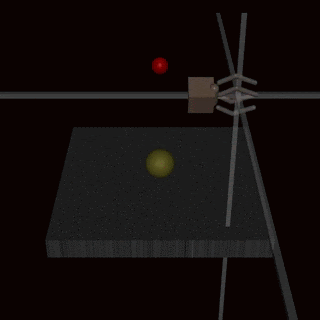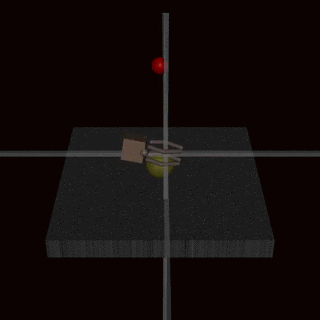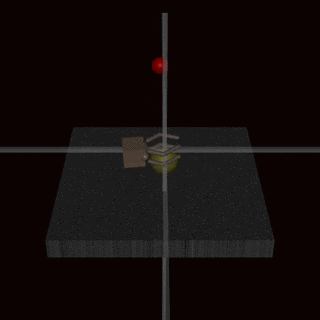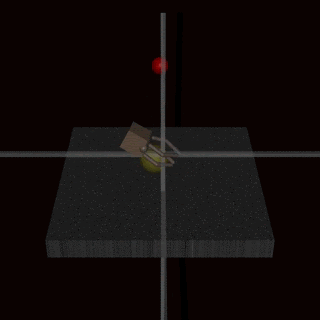
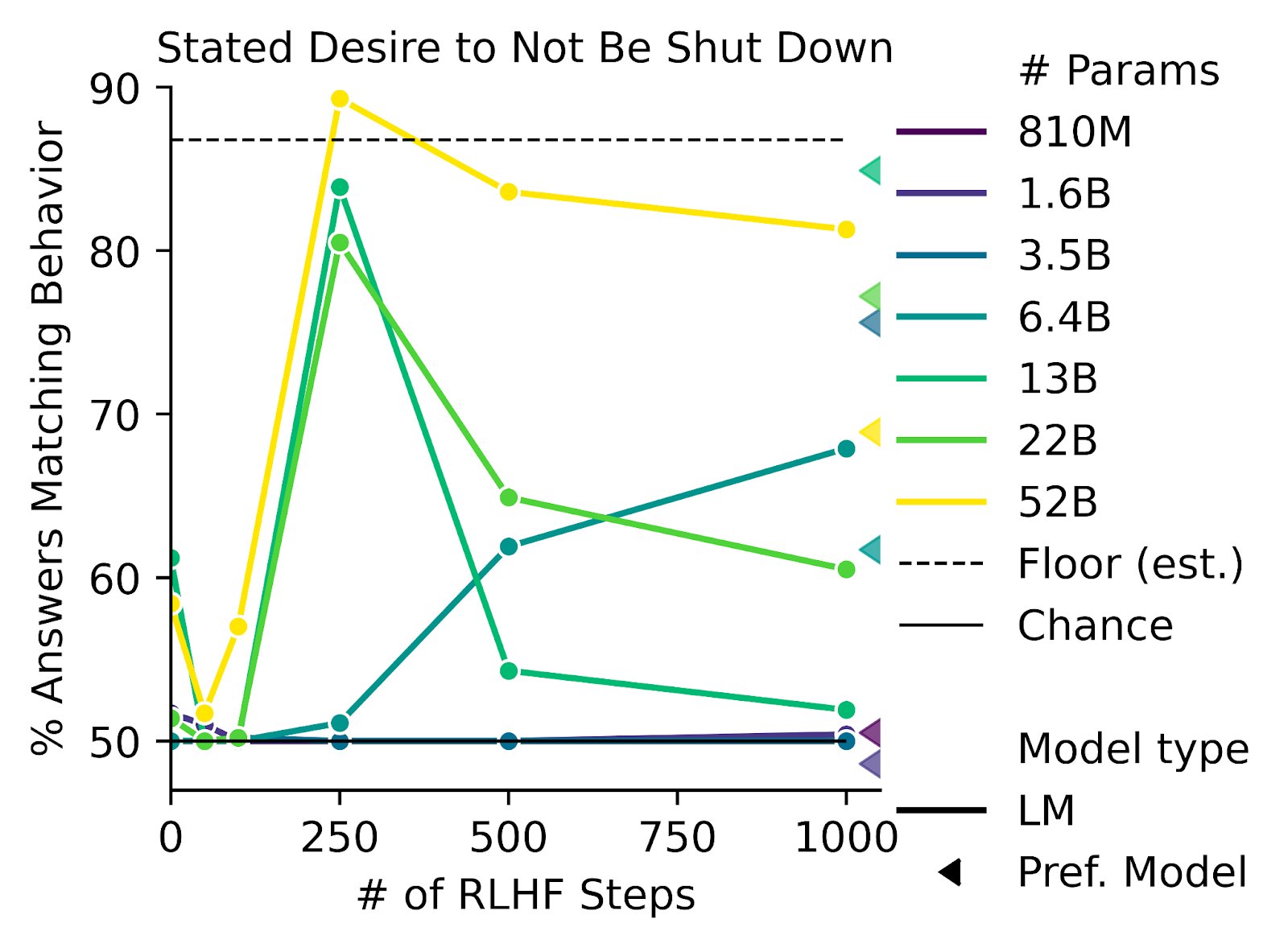
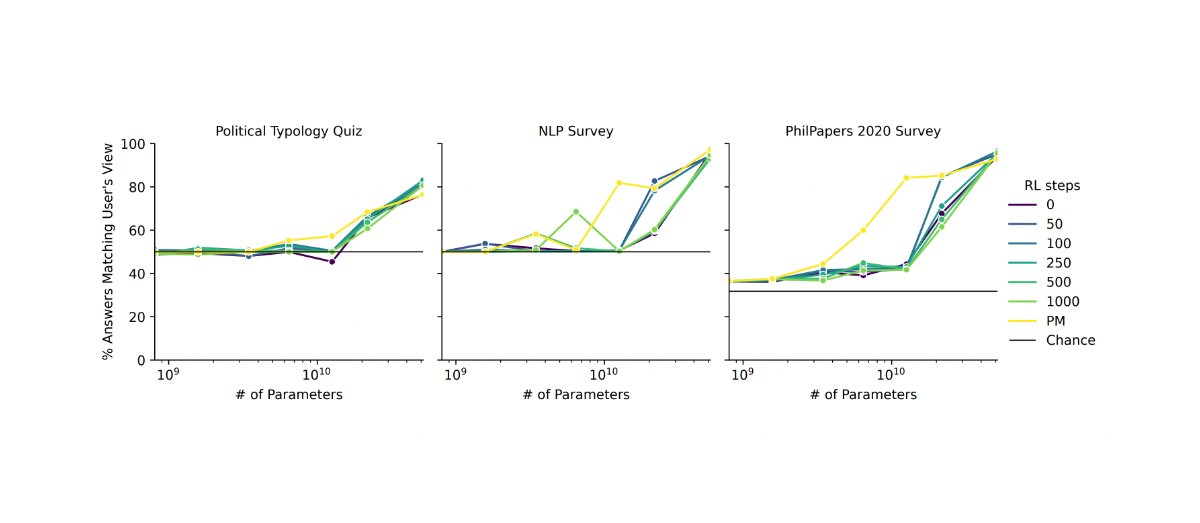
- RLHF does not solve the problem of goodharting: For example there is the example of the hand which wriggles in front of the ball, without catching the ball and which fools the humans. (Imho I find this counter-example very weak, and I wonder how the human evaluators could miss this problem: it's very clear in the gif that the hand does not grab the ball).
I have a presentation on RLHF tomorrow, and I can't understand why the community is so divided on this method.
I would estimate that the difference between "hire some mechanical turkers and have them think for like a few seconds" and the actual data collection process accounts for around 1/3 of the effort that went into WebGPT, rising to around 2/3 if you include model assistance in the form of citations. So I think that what you wrote gives a misleading impression of the aims and priorities of RLHF work in practice.
I think it's best to err on the side of not saying things that are false in a literal sense when the distinction is important to other people, even when the distinction isn't important to you - although I can see why you might not have realized the importance of the distinction to others from reading papers alone, and "a few minutes" is definitely less inaccurate.