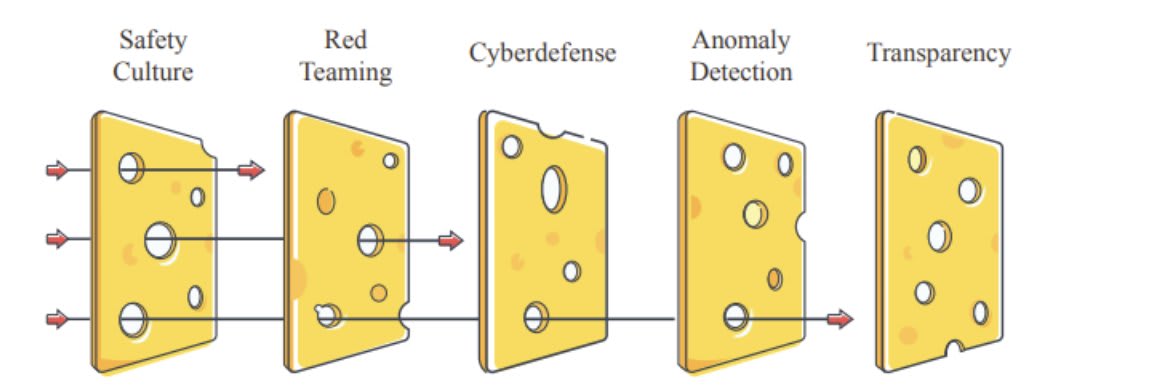
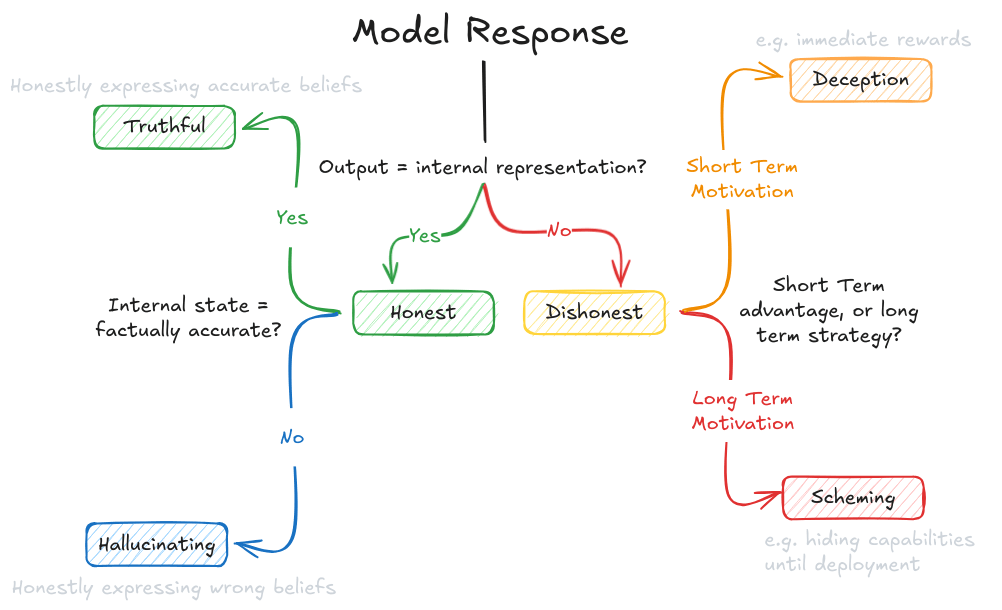
Global Call for AI Red Lines - Signed by Nobel Laureates, Former Heads of State, and 200+ Prominent Figures
The Global Call for AI Red Lines was released and presented in the opening of the first day of the 80th UN General Assembly high-level week. Maria Ressa, Nobel Peace Prize, announcing the call at the opening of the UN General Assembly: "We urge governments to establish clear international boundaries to prevent unacceptable risks for AI. At the very least, define what AI should never be allowed to do" It was initiated by CeSIA, the French Center for AI Safety, in partnership with The Future Society and the Center for Human-compatible AI. The full text of the call reads: > AI holds immense potential to advance human wellbeing, yet its current trajectory presents unprecedented dangers. AI could soon far surpass human capabilities and escalate risks such as engineered pandemics, widespread disinformation, large-scale manipulation of individuals including children, national and international security concerns, mass unemployment, and systematic human rights violations. > > Some advanced AI systems have already exhibited deceptive and harmful behavior, and yet these systems are being given more autonomy to take actions and make decisions in the world. Left unchecked, many experts, including those at the forefront of development, warn that it will become increasingly difficult to exert meaningful human control in the coming years. > > Governments must act decisively before the window for meaningful intervention closes. An international agreement on clear and verifiable red lines is necessary for preventing universally unacceptable risks. These red lines should build upon and enforce existing global frameworks and voluntary corporate commitments, ensuring that all advanced AI providers are accountable to shared thresholds. > > We urge governments to reach an international agreement on red lines for AI — ensuring they are operational, with robust enforcement mechanisms — by the end of 2026. This call has been signed by a coalition of 200+ former heads of state,