I think the RLHF solves 80% of the problems of outer alignment, and I expect it to be part of the solution.
But :
- RLHF doesn't fully solve the difficult problems, which are beyond human supervision, i.e. the problems where even humans don't know what is the right way to do
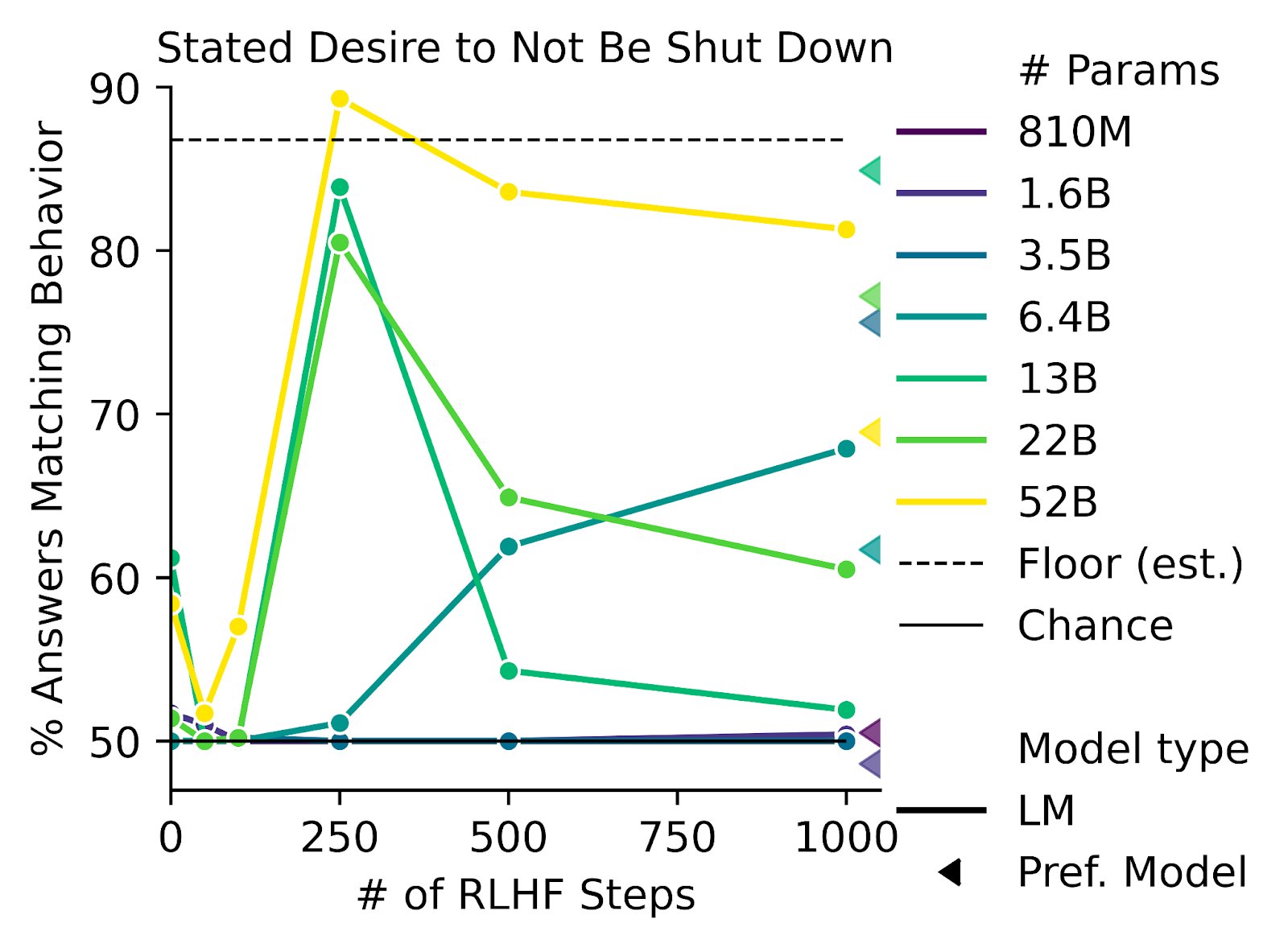
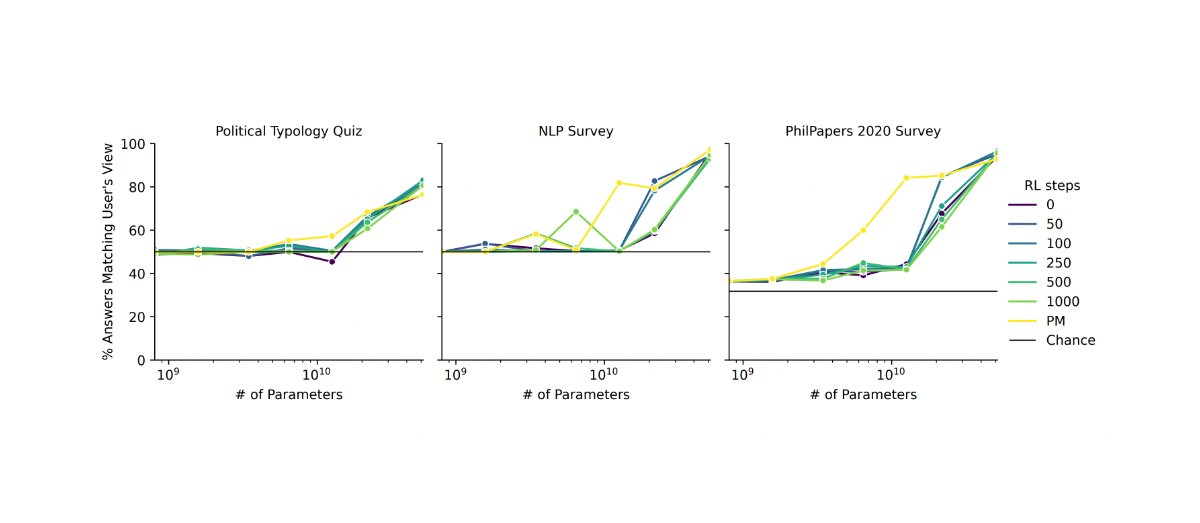
- RLHF does not solve the problem of goodharting: For example there is the example of the hand which wriggles in front of the ball, without catching the ball and which fools the humans. (Imho I find this counter-example very weak, and I wonder how the human evaluators could miss this problem: it's very clear in the gif that the hand does not grab the ball).
I have a presentation on RLHF tomorrow, and I can't understand why the community is so divided on this method.
I mean, I don't understand what you mean by "previous reward functions". RLHF is just having a "reward button" that a human can press, with when to actually press the reward button being left totally unspecified and differing between different RLHF setups. It's like the oldest idea in the book for how to train an AI, and it's been thoroughly discussed for over a decade.
Yes, it's probably better than literally hard-coding a reward function based on the inputs in terms of bad outcomes, but like, that's been analyzed and discussed for a long time, and RLHF has also been feasible for a long time (there was some engineering and ML work to be done to make reinforcement learning work well-enough for modern ML systems to make RLHF feasible in the context of the largest modern systems, and I do think that work was in some sense an advance, but I don't think it changes any of the overall dynamics of the system, and also the negative effects of that work are substantial and obvious).
This is in contrast to debate, which I think one could count as progress and feels like a real thing to me. I think it's not solving a huge part of the problem, but I have less of a strong sense of "what the hell are you talking about when saying that RLHF is 'an advance'" when referring to debate.