

I think the RLHF solves 80% of the problems of outer alignment, and I expect it to be part of the solution.
But :
- RLHF doesn't fully solve the difficult problems, which are beyond human supervision, i.e. the problems where even humans don't know what is the right way to do
- RLHF does not solve the problem of goodharting: For example there is the example of the hand which wriggles in front of the ball, without catching the ball and which fools the humans. (Imho I find this counter-example very weak, and I wonder how the human evaluators could miss this problem: it's very clear in the gif that the hand does not grab the ball).
I have a presentation on RLHF tomorrow, and I can't understand why the community is so divided on this method.

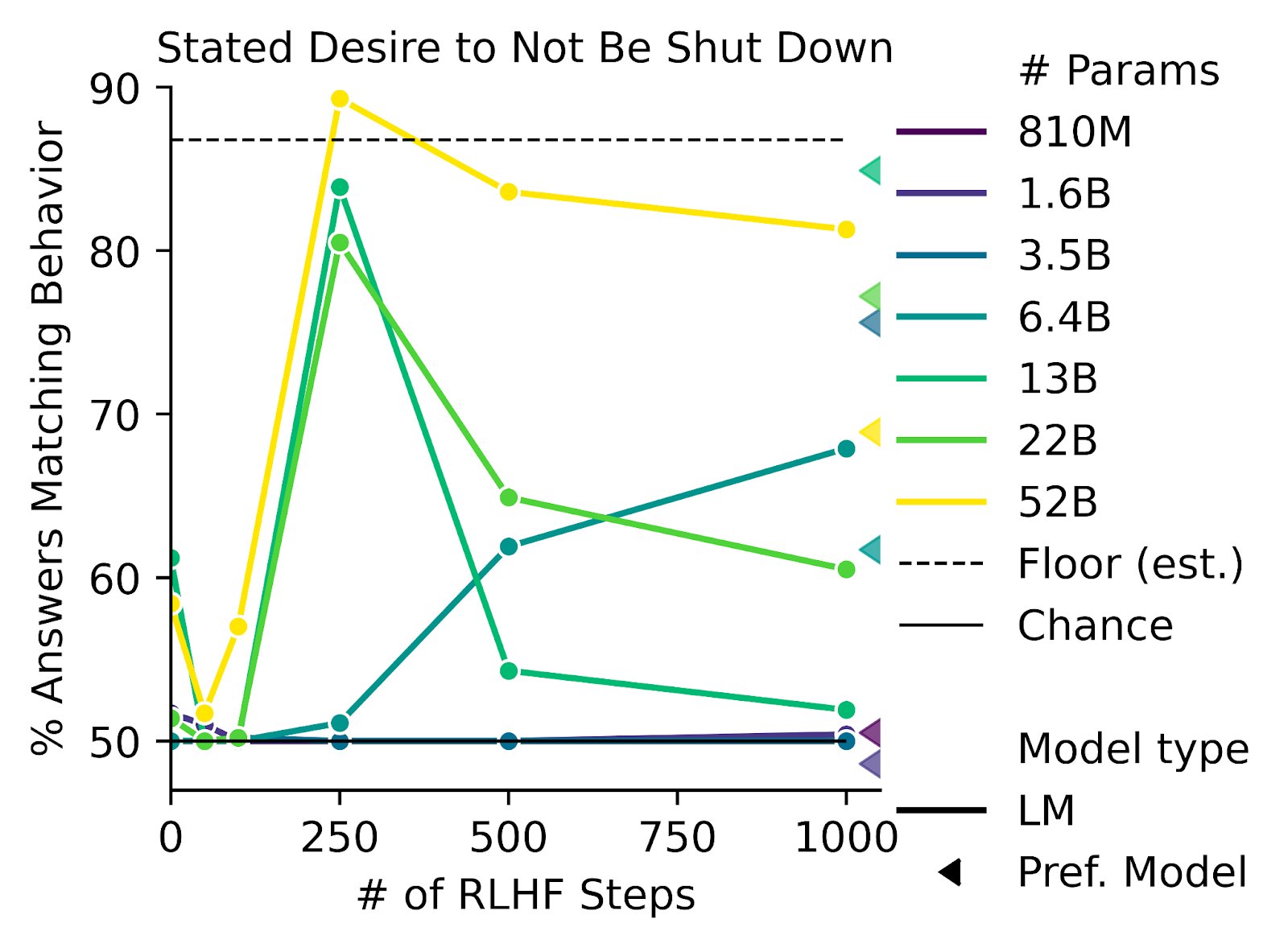
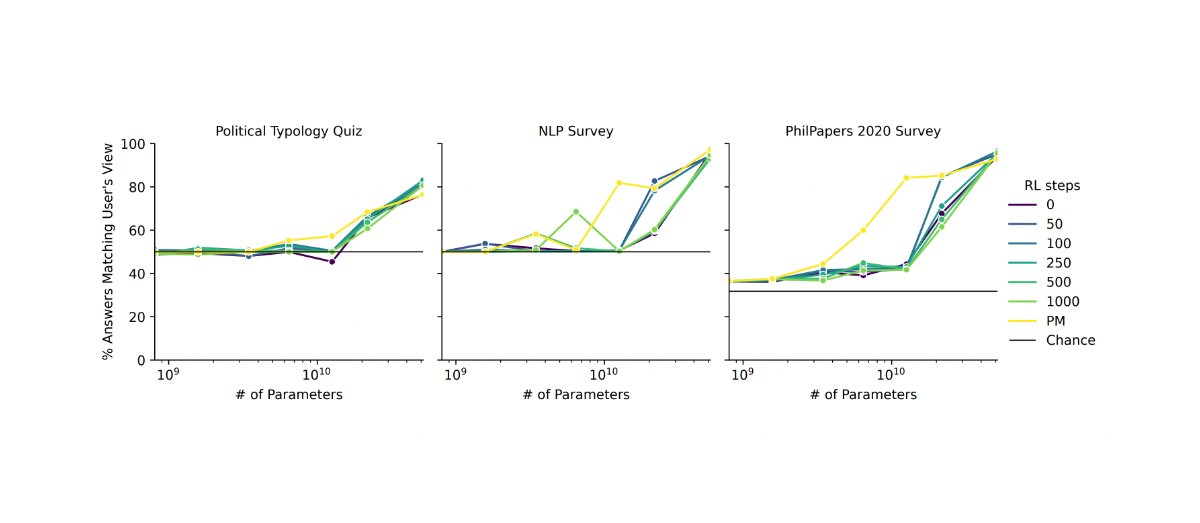
I agree that the RLHF framework is essentially just a form of model-based RL, and that its outer alignment properties are determined entirely by what you actually get the humans to reward. But your description of RLHF in practice is mostly wrong. Most of the challenge of RLHF in practice is in getting humans to reward the right thing, and in doing so at sufficient scale. There is some RLHF research that uses low-quality feedback similar to what you describe, but it does so in order to focus on other aspects of the setup, and I don't think anyone currently working on RLHF seriously considers that quality of feedback to be at all adequate outside of an experimental setting.
The RLHF work I'm most excited by, and which constitutes a large fraction of current RLHF work, is focused on getting humans to reward the right thing, and I'm particularly excited about approaches that involve model assistance, since that's the main way in which we can hope for the approach to scale gracefully with model capabilities. I'm also excited by other RLHF work because it supports this work and has other practical benefits.
I don't think RLHF directly addresses inner alignment, but I think that an inner alignment solution is likely to rely on us doing a good enough job at outer alignment, and I also have a lot of uncertainty about how much of the risk comes from outer alignment failures directly.