I often encounter some confusion about whether the fact that synapses in the brain typically fire at frequencies of 1-100 Hz while the clock frequency of a state-of-the-art GPU is on the order of 1 GHz means that AIs think "many orders of magnitude faster" than humans. In this short post, I'll argue that this way of thinking about "cognitive speed" is quite misleading.
The clock speed of a GPU is indeed meaningful: there is a clock inside the GPU that provides some signal that's periodic at a frequency of ~ 1 GHz. However, the corresponding period of ~ 1 nanosecond does not correspond to the timescale of any useful computations done by the GPU. For instance; in the A100 any read/write access into the L1 cache happens every ~ 30 clock cycles and this number goes up to 200-350 clock cycles for the L2 cache. The result of these latencies adding up along with other sources of delay such as kernel setup overhead etc. means that there is a latency of around ~ 4.5 microseconds for an A100 operating at the boosted clock speed of 1.41 GHz to be able to perform any matrix multiplication at all:
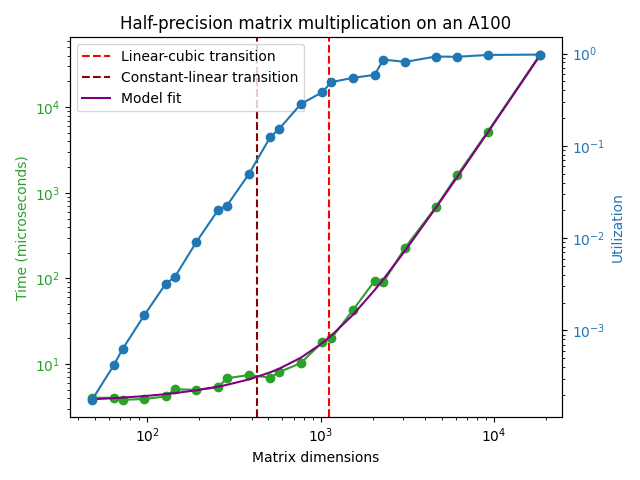
The timescale for a single matrix multiplication gets longer if we also demand that the matrix multiplication achieves something close to the peak FLOP/s performance reported in the GPU datasheet. In the plot above, it can be seen that a matrix multiplication achieving good hardware utilization can't take shorter than ~ 100 microseconds or so.
On top of this, state-of-the-art machine learning models today consist of chaining many matrix multiplications and nonlinearities in a row. For example, a typical language model could have on the order of ~ 100 layers with each layer containing at least 2 serial matrix multiplications for the feedforward layers[1]. If these were the only places where a forward pass incurred time delays, we would obtain the result that a sequential forward pass cannot occur faster than (100 microseconds/matmul) * (200 matmuls) = 20 ms or so. At this speed, we could generate 50 sequential tokens per second, which is not too far from human reading speed. This is why you haven't seen LLMs being serviced at per token latencies that are much faster than this.
We can, of course, process many requests at once in these 20 milliseconds: the bound is not that we can generate only 50 tokens per second, but that we can generate only 50 sequential tokens per second, meaning that the generation of each token needs to know what all the previously generated tokens were. It's much easier to handle requests in parallel, but that has little to do with the "clock speed" of GPUs and much more to do with their FLOP/s capacity.
The human brain is estimated to do the computational equivalent of around 1e15 FLOP/s. This performance is on par with NVIDIA's latest machine learning GPU (the H100) and the brain achieves this performance using only 20 W of power compared to the 700 W that's drawn by an H100. In addition, each forward pass of a state-of-the-art language model today likely takes somewhere between 1e11 and 1e12 FLOP, so the computational capacity of the brain alone is sufficient to run inference on these models at speeds of 1k to 10k tokens per second. There's, in short, no meaningful sense in which machine learning models today think faster than humans do, though they are certainly much more effective at parallel tasks because we can run them on clusters of multiple GPUs.
In general, I think it's more sensible for discussion of cognitive capabilities to focus on throughput metrics such as training compute (units of FLOP) and inference compute (units of FLOP/token or FLOP/s). If all the AIs in the world are doing orders of magnitude more arithmetic operations per second than all the humans in the world (8e9 people * 1e15 FLOP/s/person = 8e24 FLOP/s is a big number!) we have a good case for saying that the cognition of AIs has become faster than that of humans in some important sense. However, just comparing the clock speed of a GPU to the synapse firing frequency in the human brain and concluding that AIs think faster than humans is a sloppy argument that neglects how training or inference of ML models on GPUs actually works right now.
While attention and feedforward layers are sequential in the vanilla Transformer architecture, they can in fact be parallelized by adding the outputs of both to the residual stream instead of doing the operations sequentially. This optimization lowers the number of serial operations needed for a forward or backward pass by around a factor of 2 and I assume it's being used in this context. ↩︎


It is not a tautology.
Er, this is why I spent half my comment discussing correspondence chess... My understanding is that it is not true that if you ran computers for a long time that they would beat the human also running for a long time, and that historically, it's been quite the opposite: the more time/compute spent, the better the human plays because they have a more scalable search. (eg. Shannon's 'type-A strategy vs type-B strategy' was meant to cover this distinction: humans search moves slower, but we search moves way better, and that's why we win.) It was only at short time controls where human ability to plan deeply was negated that chess engines had any chance. (In correspondence chess, they deeply analyze the most important lines of play and avoid getting distracted, so they can go much deeper into the game tree that chess engines could.) Whenever the crossover happened, it was probably after Deep Blue. And given the different styles of play and the asymptotics of how those AIs smash into the exponential wall of the game tree & explode, I'm not sure there is any time control at which you would expect pre-Deep-Blue chess to be superhuman.
This is similar to ML scaling. While curves are often parallel and don't cross, curves often do cross; what they don't do is criss-cross repeatedly. Once you fall behind asymptotically, you fall behind for good.
I'm not familiar with 'correspondence Go' but I would expect that if it was pursued seriously like correspondence chess, it would exhibit the same non-monotonicity.
That's not obvious to me. If nothing else, that time isn't useful once you run out of memory. And PCs had very little memory: you might have 16MB RAM to work with.
And obviously, I am not discussing the trivial case of changing the task to a different task by assuming unlimited hardware or ignoring time and just handicapping human performance by holding their time constant while assigning unlimited resources to computers - in which case we had superhuman chess, Go, and many other things whenever someone first wrote down a computable tree search strategy!*
* actually pretty nontrivial. Recall the arguments like Edgar Allan Poe's that computer chess was impossible in principle. So there was a point at which even infinite compute didn't help because no one knew how to write down and solve the game tree, as obvious and intuitive as that paradigm now seems to us. (I think that was Shannon, as surprisingly late as that may seem.) This also describes a lot of things we now can do in ML.