I often encounter some confusion about whether the fact that synapses in the brain typically fire at frequencies of 1-100 Hz while the clock frequency of a state-of-the-art GPU is on the order of 1 GHz means that AIs think "many orders of magnitude faster" than humans. In this short post, I'll argue that this way of thinking about "cognitive speed" is quite misleading.
The clock speed of a GPU is indeed meaningful: there is a clock inside the GPU that provides some signal that's periodic at a frequency of ~ 1 GHz. However, the corresponding period of ~ 1 nanosecond does not correspond to the timescale of any useful computations done by the GPU. For instance; in the A100 any read/write access into the L1 cache happens every ~ 30 clock cycles and this number goes up to 200-350 clock cycles for the L2 cache. The result of these latencies adding up along with other sources of delay such as kernel setup overhead etc. means that there is a latency of around ~ 4.5 microseconds for an A100 operating at the boosted clock speed of 1.41 GHz to be able to perform any matrix multiplication at all:
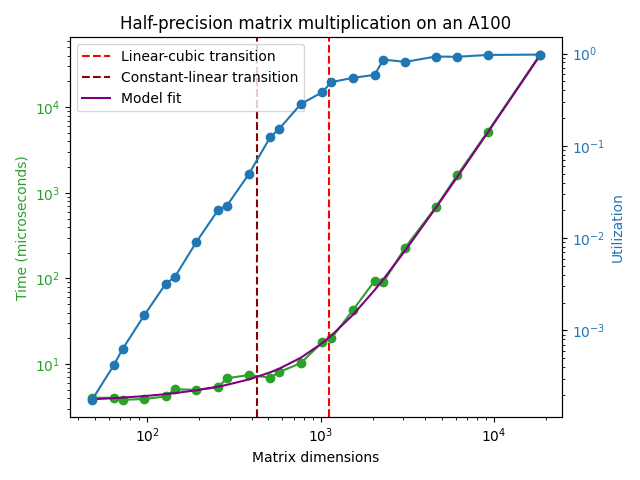
The timescale for a single matrix multiplication gets longer if we also demand that the matrix multiplication achieves something close to the peak FLOP/s performance reported in the GPU datasheet. In the plot above, it can be seen that a matrix multiplication achieving good hardware utilization can't take shorter than ~ 100 microseconds or so.
On top of this, state-of-the-art machine learning models today consist of chaining many matrix multiplications and nonlinearities in a row. For example, a typical language model could have on the order of ~ 100 layers with each layer containing at least 2 serial matrix multiplications for the feedforward layers[1]. If these were the only places where a forward pass incurred time delays, we would obtain the result that a sequential forward pass cannot occur faster than (100 microseconds/matmul) * (200 matmuls) = 20 ms or so. At this speed, we could generate 50 sequential tokens per second, which is not too far from human reading speed. This is why you haven't seen LLMs being serviced at per token latencies that are much faster than this.
We can, of course, process many requests at once in these 20 milliseconds: the bound is not that we can generate only 50 tokens per second, but that we can generate only 50 sequential tokens per second, meaning that the generation of each token needs to know what all the previously generated tokens were. It's much easier to handle requests in parallel, but that has little to do with the "clock speed" of GPUs and much more to do with their FLOP/s capacity.
The human brain is estimated to do the computational equivalent of around 1e15 FLOP/s. This performance is on par with NVIDIA's latest machine learning GPU (the H100) and the brain achieves this performance using only 20 W of power compared to the 700 W that's drawn by an H100. In addition, each forward pass of a state-of-the-art language model today likely takes somewhere between 1e11 and 1e12 FLOP, so the computational capacity of the brain alone is sufficient to run inference on these models at speeds of 1k to 10k tokens per second. There's, in short, no meaningful sense in which machine learning models today think faster than humans do, though they are certainly much more effective at parallel tasks because we can run them on clusters of multiple GPUs.
In general, I think it's more sensible for discussion of cognitive capabilities to focus on throughput metrics such as training compute (units of FLOP) and inference compute (units of FLOP/token or FLOP/s). If all the AIs in the world are doing orders of magnitude more arithmetic operations per second than all the humans in the world (8e9 people * 1e15 FLOP/s/person = 8e24 FLOP/s is a big number!) we have a good case for saying that the cognition of AIs has become faster than that of humans in some important sense. However, just comparing the clock speed of a GPU to the synapse firing frequency in the human brain and concluding that AIs think faster than humans is a sloppy argument that neglects how training or inference of ML models on GPUs actually works right now.
While attention and feedforward layers are sequential in the vanilla Transformer architecture, they can in fact be parallelized by adding the outputs of both to the residual stream instead of doing the operations sequentially. This optimization lowers the number of serial operations needed for a forward or backward pass by around a factor of 2 and I assume it's being used in this context. ↩︎


This notion of thinking speed makes sense for large classes of tasks, not just specific tasks. And a natural class of tasks to focus on is the harder tasks among all the tasks both systems can solve.
So in this sense a calculator is indeed much faster than GPT-4, and GPT-4 is 2 OOMs faster than humans. An autonomous research AGI is capable of autonomous research, so its speed can be compared to humans at that class of tasks.
AI accelerates the pace of history only when it's capable of making the same kind of progress as humans in advancing history, at which point we need to compare their speed to that of humans at that activity (class of tasks). Currently AIs are not capable of that at all. If hypothetically 1e28 training FLOPs LLMs become capable of autonomous research (with scaffolding that doesn't incur too much latency overhead), we can expect that they'll be 1-2 OOMs faster than humans, because we know how they work. Thus it makes sense to claim that 1e28 FLOPs LLMs will accelerate history if they can do research autonomously. If AIs need to rely on extensive search on top of LLMs to get there, or if they can't do it at all, we can instead predict that they don't accelerate history, again based on what we know of how they work.