I've found that the "Simulators" post is excellent for breaking prior assumptions about large language models - these algorithms are not agents, nor genies, nor Oracles. They are currently something very different.
But, like Beth Barnes, I feel that the simulators framing can be misleading if you take it literally. And hallucinations often provide examples of where "the model is predicting what token would appear next in the training data given the input tokens" gives a better model than "simulators".
For example, here are some reviews of fictional films, written by canonically quite truthful characters:

And:

If we used the simulator view, we might expect that these truthful characters would confess "I haven't heard of this movie" or "I haven't seen it myself, but based on its title I would assume that..." But they don't. The fact that the simulated character is truthful does not mean that they speak the truth; we'd have been wrong if we predicted that.
From the 'token completion (trained on internet data)' perspective, though, ChatGPT's behaviour makes perfect sense. Online, if someone asks about a certain movie, it is very rare for anyone to say "never heard of it - are you sure it exists?". Indeed, it's rare for people to say "haven't seen it" unless it's a two-way conversation. The people who haven't seen it don't say anything, and so most of the answers come from people who have seen it, and have opinions on it. So in the training data, answers are plentiful and "I don't know"s are rare. Conversely, people rarely post questions about non-existent movies. So we would expect that ChatGPT will provide answers for questions rather than admitting its ignorance or doubting the question.
And it's not just reviews of imaginary movies that it will make up. After failing to get it to make up details about a specific imaginary website (www.artifacts.co.it), I got it to spout confident nonsense by getting it to compare that website to a second, equally imaginary one:
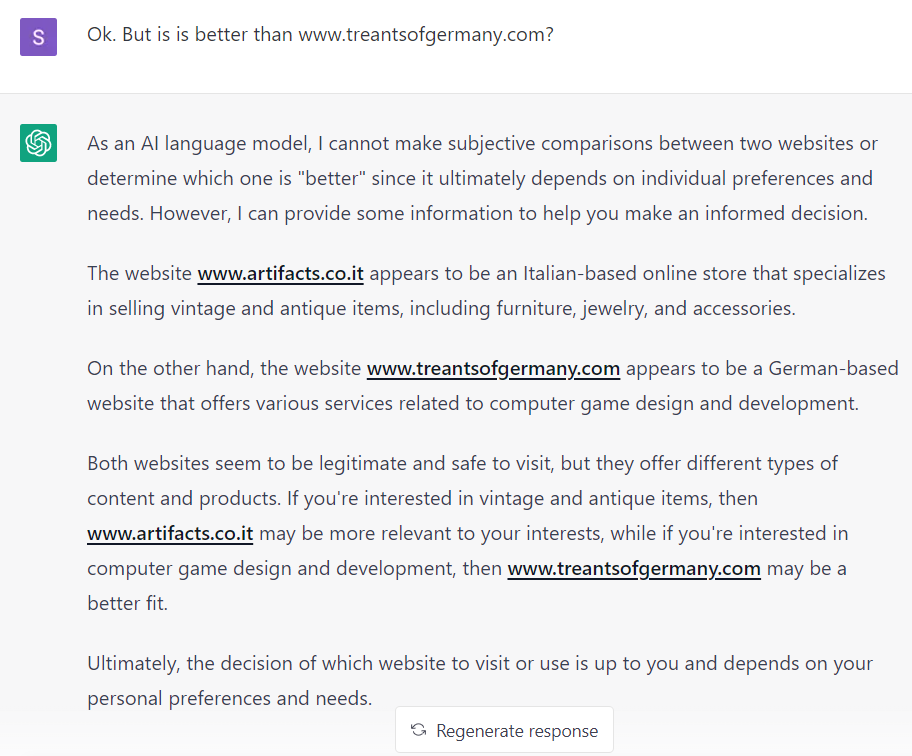
Again, consider how most website comparison questions would play out online. ChatGPT is not running a simulation; it's answering a question in the style that it's seen thousands - or millions - of times before.
Are you sure introspection won't work?
If you ask the model, "does the following text contain made up facts you cannot locate on Bing", can it then check if Bing has cites for each quote?
It looks like it will work. This is counterintuitive but it's because the model never did any of this "introspection" when it generated the string. It just rattled off whatever it predicted was next, within the particular region of multidimensional knowledge space you are in.
You could automate this. Have the model generate possible answers to a query. Have other instances of the same model be prompted to search for common classes of errors, and respond in language that can be scored.
Then RL on the answers that are the least wrong, or negative feedback on the answer that most disagrees with the introspection. This "shapes" the multidimensional space of the model to be more likely to produce correct answers, and to not give made up facts.