Abstract
Language models (LMs) are powerful tools for natural language processing, but they often struggle to produce coherent and fluent text when they are small. Models with around 125M parameters such as GPT-Neo (small) or GPT-2 (small) can rarely generate coherent and consistent English text beyond a few words even after extensive training. This raises the question of whether the emergence of the ability to produce coherent English text only occurs at larger scales (with hundreds of millions of parameters or more) and complex architectures (with many layers of global attention). In this work, we introduce TinyStories, a synthetic dataset of short stories that only contain words that a typical 3 to 4-year-olds usually understand, generated by GPT-3.5 and GPT-4. We show that TinyStories can be used to train and evaluate LMs that are much smaller than the state-of-the-art models (below 10 million total parameters), or have much simpler architectures (with only one transformer block), yet still produce fluent and consistent stories with several paragraphs that are diverse and have almost perfect grammar, and demonstrate reasoning capabilities. We also introduce a new paradigm for the evaluation of language models: We suggest a framework which uses GPT-4 to grade the content generated by these models as if those were stories written by students and graded by a (human) teacher. This new paradigm overcomes the flaws of standard benchmarks which often requires the model's output to be very structures, and moreover provides a multidimensional score for the model, providing scores for different capabilities such as grammar, creativity and consistency. We hope that TinyStories can facilitate the development, analysis and research of LMs, especially for low-resource or specialized domains, and shed light on the emergence of language capabilities in LMs.
Implications
Interpretability
One part that isn't mentioned in the abstract but is interesting:
We show that the trained SLMs appear to be substantially more interpretable than larger ones. When models have a small number of neurons and/or a small number of layers, we observe that both attention heads and MLP neurons have a meaningful function: Attention heads produce very clear attention patterns, with a clear separation between local and semantic heads, and MLP neurons typically activated on tokens that have a clear common role in the sentence. We visualize and analyze the attention and activation maps of the models, and show how they relate to the generation process and the story content.
The difference between highly activating tokens for a neuron is striking, here's the tiny model:
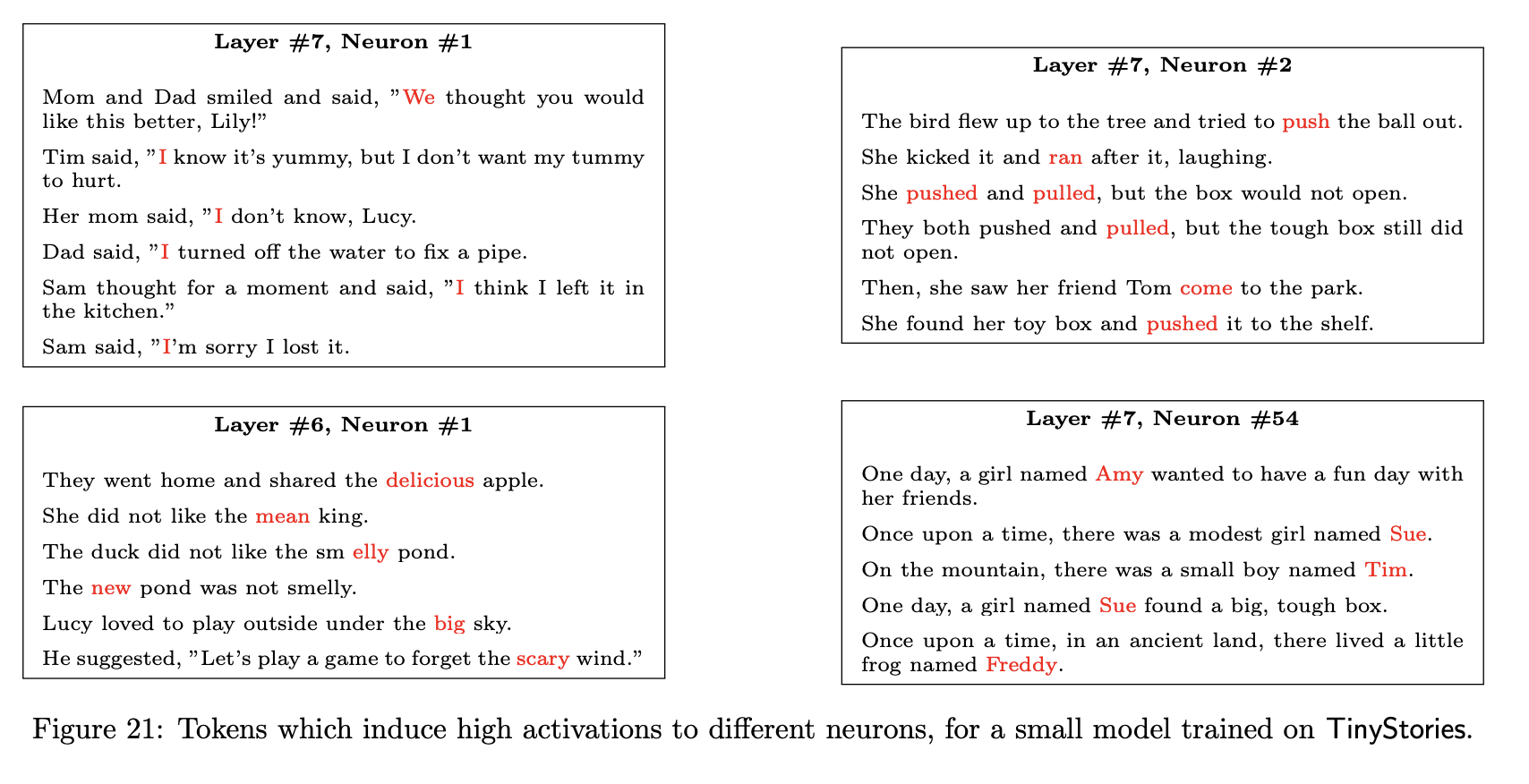
...and here's GPT2-XL:

Capabilities
Again from the introduction (emphasis mine)
However, it is currently not clear whether the inability of SLMs to produce coherent text is a result of the intrinsic complexity of natural language, or of the excessive breadth and diversity of the corpora used for training. When we train a model on Wikipedia, for example, we are not only teaching it how to speak English, but also how to encode and retrieve an immense amount of facts and concepts from various domains and disciplines. Could it be that SLMs are overwhelmed by the amount and variety of information they have to process and store, and that this hinders their ability to learn the core mechanisms and principles of language? This raises the question of whether we can design a dataset that preserves the essential elements of natural language, such as grammar, vocabulary, facts, and reasoning, but that is much smaller and more refined in terms of its breadth and diversity.
If this is true, there could be ways to drastically cut LLM training costs while maintaining (or increasing) the capabilities of the final model.
This could be related to dataset quality. QLoRA found (among other things) that a high-quality dataset of 9000 examples (OpenAssistant) beat a 1M dataset of lower quality.
I think this offers an interesting possibility for another way to safely allow users to get benefit from a strong AI that a company wishes to keep private. The user can submit a design specification for a desired task, and the company with a strong AI can use the strong AI to create a custom dataset and train a smaller simpler narrower model. The end user then gets full access to the code and weights of the resulting small model, after the company has done some safety verification on the custom dataset and small model. I think this is actually potentially safer than allowing customers direct API access to the strong model, if the strong model is quite strong and not well aligned. It's a relatively bounded, supervisable task.
Existing large tech companies are using approaches like this, training or fine-tuning small models on data generated by large ones.
For example, it's helpful for the cold start problem, where you don't yet have user input to train/fine-tune your small model on because the product the model is intended for hasn't been launched yet: have a large model create some simulated user input, train the small model on that, launch a beta test, and then retrain your small model with real user input as soon as you have some.