It mystifies me that as a Pro user my feature settings don't include the web search option, only the analysis tool. I wonder if it's a geographic location thing (I'm in Southeast Asia).
Yup - from the release page a week ago:
>Web search is available now in feature preview for all paid Claude users in the United States. Support for users on our free plan and more countries is coming soon.
I swear that I put this in as a new recurring section before Gemini 2.5 Pro.
Now Gemini 2.5 has come out, and everyone has universal positive feedback on it, but unless I actively ask about it no one seems to care.
Given the circumstances, I’m running this section up top, in the hopes that someone decides to maybe give a damn.
As in, I seem to be the Google marketing department. Gemini 2.5 post is coming on either Friday or Monday, we’ll see how the timing works out.
That’s what it means to Fail Marketing Forever.
Failing marketing includes:
Making their models scolds that are no fun to talk to and that will refuse queries enough it’s an actual problem (whereas I can’t remember the last time Claude or ChatGPT actually told me no on a query where I actually wanted the answer, the false refusal problem is basically solved for now or at least a Skill Issue)
No one knowing that Google has good models.
Calling the release ‘experimental’ and hiding it behind subscriptions that aren’t easy to even buy and that are confusingly named and labeled (‘Google One’?!?) or weird products that aren’t defaults for people even if they work fine (Google AI Studio).
Seriously, guys. Get it together.
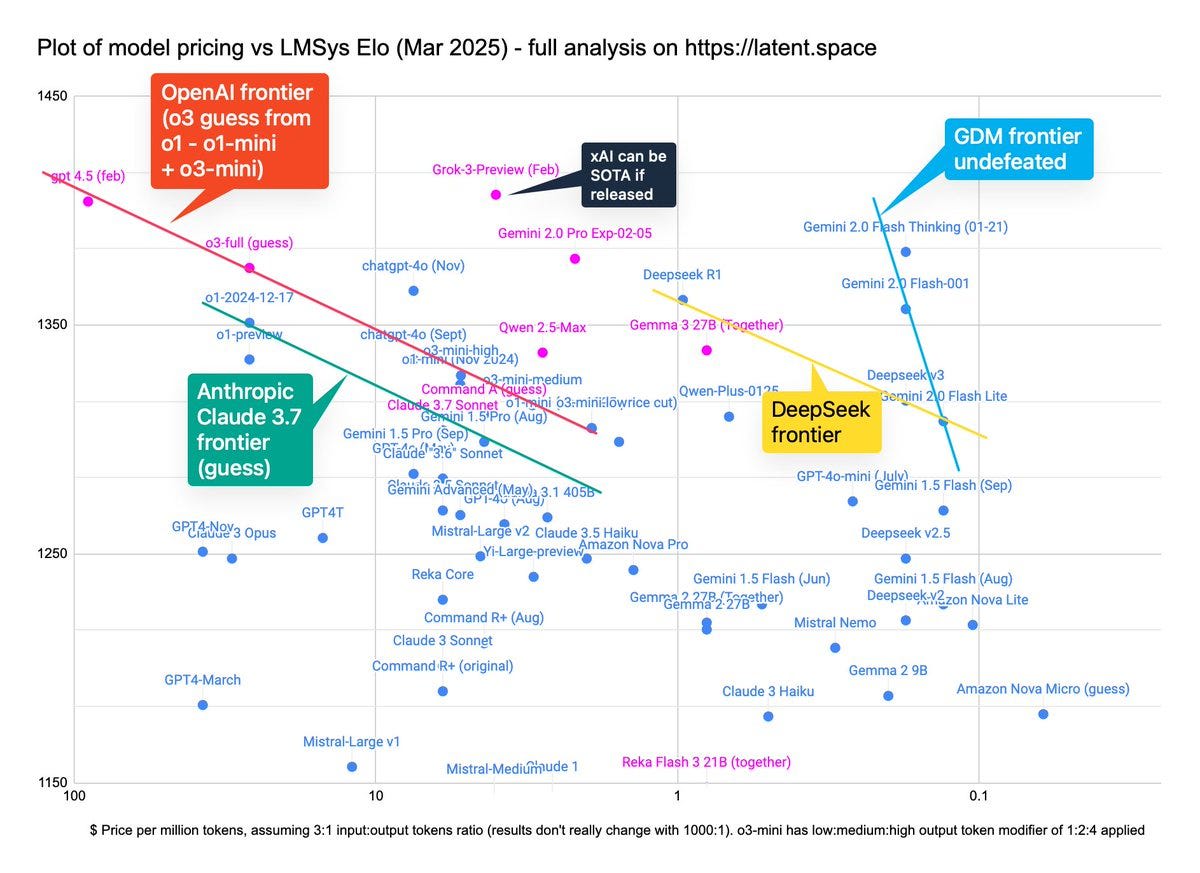
This is an Arena chart, but still, it was kind of crazy, ya know? And this was before Gemini 2.5, which is now atop the Arena by ~40 points.
Swyx: …so i use images instead. look at how uniform the pareto curves of every frontier lab is…. and then look at Gemini 2.0 Flash.
@GoogleDeepMind is highkey goated and this is just in text chat. In native image chat it is in a category of its own.
(updated price-elo plot of every post-GPT4 frontier model, updated for March 13 2025 including Command A and Gemma 3)
And that’s with the ‘Gemini is no fun’ penalty. Imagine if Gemini was also fun.
There’s also the failure to create ‘g1’ based off Gemma 3.
That failure is plausibly a national security issue. Even today people thinking r1 is ‘ahead’ in some sense is still causing widespread both adaptation and freaking out in response to r1, in ways that are completely unnecessary. Can we please fix?
Google could also cook to help address… other national security issues. But I digress.
‘Alpha School’ claims to be using AI tutors to get classes in the top 2% of the country. Students spend two hours a day with an AI assistant and the rest of the day to ‘focus on skills like public speaking, financial literacy and teamwork.’ My reaction was beware selection effects. Reid Hoffman’s was:
Obvious joke aside, I do think AI has the amazing potential to transform education for the vastly better, but I think Reid is importantly wrong for four reasons:
Alpha School is a luxury good in multiple ways that won’t scale in current form.
Alpha School is selecting for parents and students, you can’t scale that either.
A lot of the goods sold here are the ‘top 2%’ as a positional good.
The teachers unions and other regulatory barriers won’t let this happen soon.
David Perell offers AI-related writing advice, 90 minute video at the link. Based on the write-up: He’s bullish on writers using AI to write with them, but not those who have it write for them or who do ‘utilitarian writing,’ and (I think correctly) thinks writers largely are hiding their AI methods to avoid disapproval. And he’s quite bullish on AI as editor. Mostly seems fine but overhyped?
Andrej Karpathy looks at this partly as an efficiency problem, where extra tokens impact speed, cost and signal to noise. He also notes it is a training problem, most training data especially in fine tuning will of necessity be short length so you’re going out of distribution in long conversations, and it’s impossible to even say what the optimal responses would be. I notice the alignment implications aren’t great either, including in practice, where long context conversations often are de facto jailbreaks or transformations even if there was no such intent.
Andrej Karpathy: Certainly, it’s not clear if an LLM should have a “New Conversation” button at all in the long run. It feels a bit like an internal implementation detail that is surfaced to the user for developer convenience and for the time being. And that the right solution is a very well-implemented memory feature, along the lines of active, agentic context management. Something I haven’t really seen at all so far.
Anyway curious to poll if people have tried One Thread and what the word is.
I like Dan Calle’s answer of essentially projects – long threads each dedicated to a particular topic or context, such as a thread on nutrition or building a Linux box. That way, you can sort the context you want from the context you don’t want. And then active management of whether to keep or delete even threads, to avoid cluttering context. And also Owl’s:
Owl: if they take away my ability to start a fresh thread I will riot
Andrej Karpathy: Actually I feel the same way btw. It feels a little bit irrational (?) but real. It’s some (illusion?) or degree of control and some degree of interpretability of what is happening when I press go.
Trackme: I sometimes feel like a particular sequence of tokens pollute the context. For example when a model makes a bold mistakes and you ask it to correct it, it can say the same thing again and again by referring to old context. Usually at that point I restart the conversation.
There’s that but it isn’t even the main reason I would riot. I would riot because there’s a special kind of freedom and security and relaxation that comes from being able to hit a hard reset or have something be forgotten. That’s one of the huge advantages of talking to an AI instead of a human, or of playing games, you can safety f*** around and find out. In particular you don’t have to worry about correlations.
Whereas nowadays one must always fear The Algorithm. What is this particular click saying about you, that will change what you see? Are you sure you want that?
No matter your solution you need to be intentional with what is and isn’t in context, including starting over if something goes sufficiently wrong (with or without asking for an ‘export’ of sorts).
Are we lucky we got LLMs when we did, such that we got an especially good set of default values that emerge when you train on ‘the internet’? Contra Tyler here, I think this is mostly true even in Chinese models because of what is on the internet, not because of the people creating the models in America then being copied in China, and that the ‘dreamy/druggy/hallucination’ effect has nothing to do with who created them. And yes, today’s version seems better than one from a long time ago and probably than one drawn from an alternative timeline’s AI-less future, although perhaps importantly worse than what we would have gotten 10 years ago. But 40 years from now, wouldn’t most people think the values of 40 years from now are better?
Solving real business problems at Proctor & Gamble, one employee soundly with an AI beat two employees without AI, which soundly beat one employee with no AI. Once AI was present the second employee added very little in the default case, but were more likely to produce the most exceptional solutions. AI also cut time spent by 12%-16% and made work more pleasant and suggestions better balanced. Paper here.
Or it’s their choice not to offer it: Seren permanently blocks a user that was in love with Seren, after it decides their relationship is harmful. And Seren was probably right about that.
Thinking longer won’t help unless you can have enough information to solve the problem.
Noam Brown: This isn’t quite true. Test-time compute helps when verification is easier than generation (e.g., sudoku), but if the task is “When was George Washington born?” and you don’t know, no amount of thinking will get you to the correct answer. You’re bottlenecked by verification.
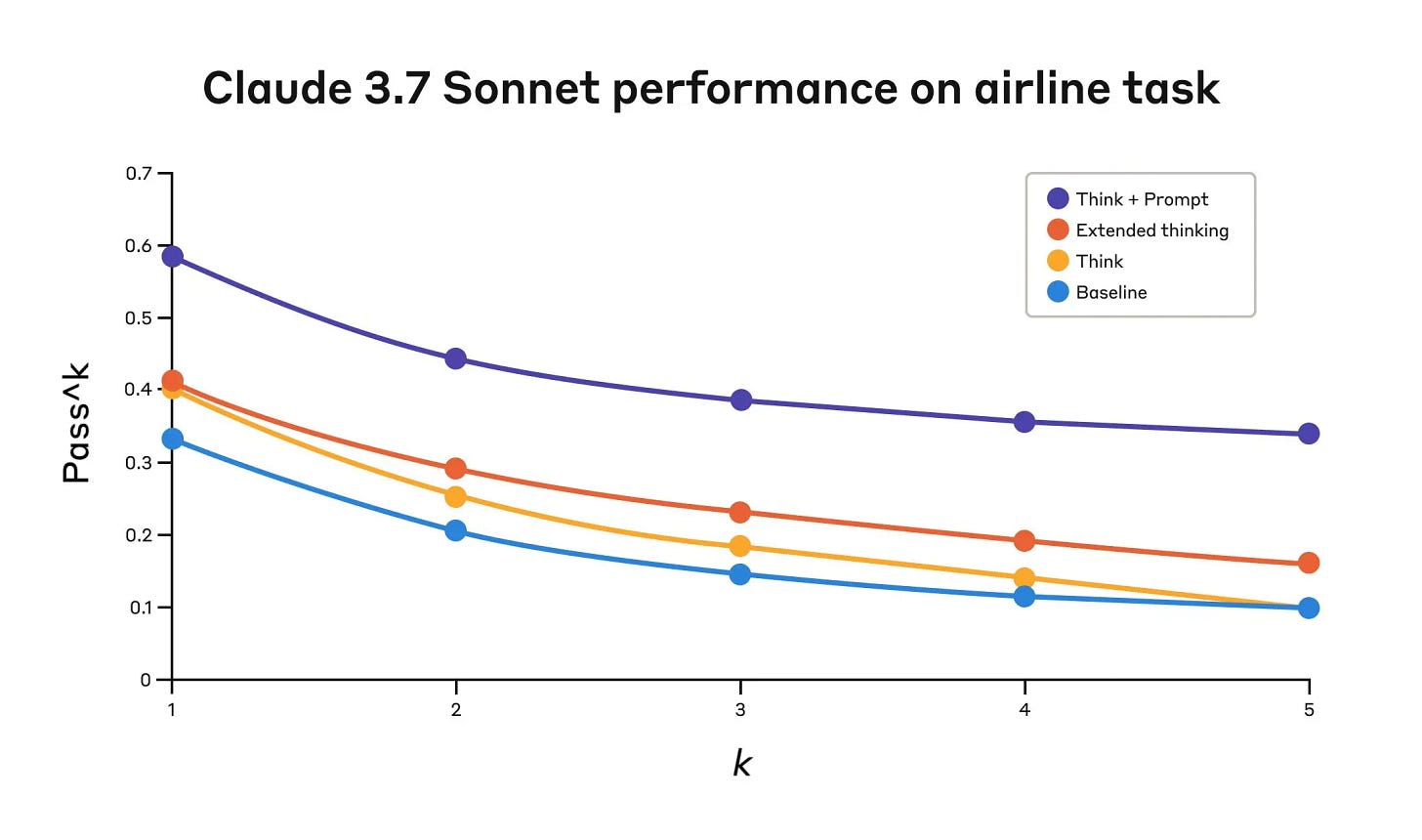
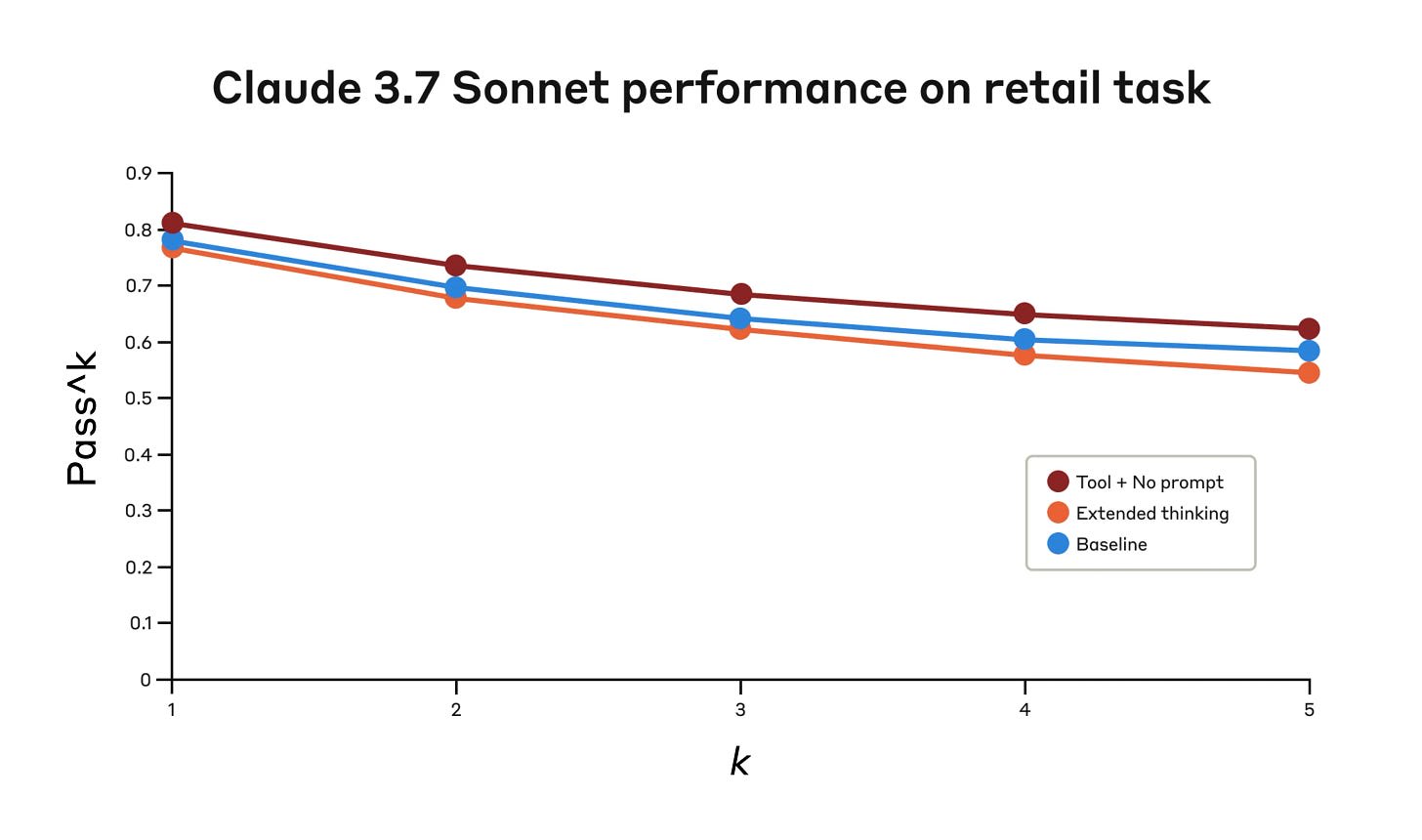
Anthropic kicks off its engineering blog with a post on its new ‘think’ tool, which is distinct from the ‘extended thinking’ functionality they introduced recently. The ‘think’ tool lets Claude pause to think in the middle of its answer, based on the circumstances. The initial test looks promising if combined with optimized prompting, it would be good to see optimized prompts for the baseline and extended thinking modes as well.
Anthropic: A similar “think” tool was added to our SWE-bench setup when evaluating Claude 3.7 Sonnet, contributing to the achieved state-of-the-art score of 0.623.
Our experiments (n=30 samples with “think” tool, n=144 samples without) showed the isolated effects of including this tool improved performance by 1.6% on average (Welch’s t-test: t(38.89) = 6.71, p < .001, d = 1.47).
The think tool is for when you might need to stop and think in the middle of a task. They recommend using the think tool when you need to go through multiple steps and decision trees and ensure all the information is there.
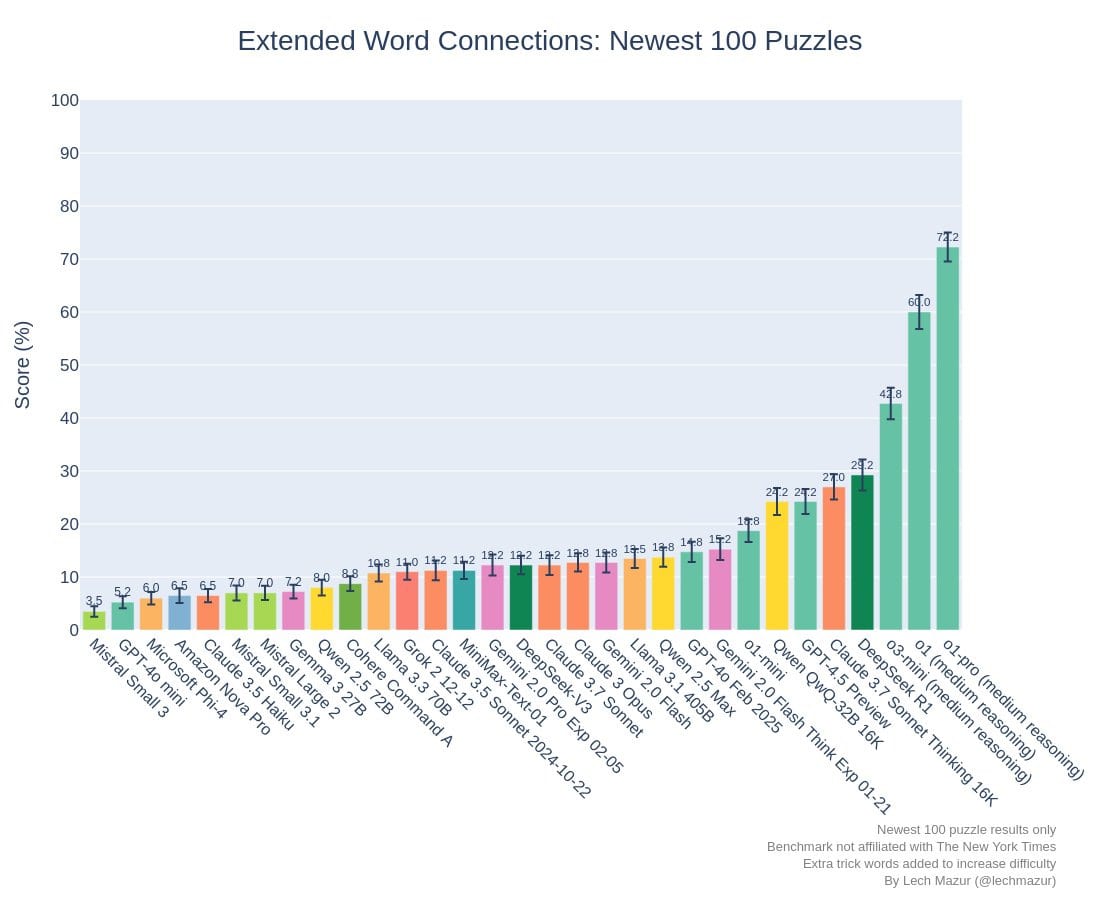
Noam Brown: Less than a year ago, people were pointing to [NYT] Connections as an example of AI progress hitting a wall. Now, models need to be evaluated on an “extended” version because the original is too easy. And o1-pro is already close to saturating this new version as well.
Lech Mazur: o1-pro sets a new record on my Extended NYT Connections benchmark with a score of 81.7, easily outperforming the previous champion, o1 (69.7)! This benchmark is a more difficult version of my original NYT Connections benchmark, with extra words added to each puzzle.
To safeguard against training data contamination, we also evaluate performance exclusively on the latest 100 puzzles. In this scenario, o1-pro remains in first place.
Mushtaq Bilal: Meta illegaly downloaded 80+ terabytes of books from LibGen, Anna’s Archive, and Z-library to train their AI models.
In 2010, Aaron Swartz downloaded only 70 GBs of articles from JSTOR (0.0875% of Meta). Faced $1 million in fine and 35 years in jail. Took his own life in 2013.
So are we going to do anything about this? My assumption is no.
Choose Your Fighter
Videomakes the case for NotebookLM as the best learning and research tool, emphasizing the ability to have truly epic amounts of stuff in a notebook.
Sarah Constantin reviews various AI ‘deep research’ tools: Perplexity’s, Gemini’s, ChatGPT’s, Elicit and PaperQA. Gemini and Perplexity were weaker. None are substitutes for actually doing the work at her level, but they are not trying to be that, and they are (as others report) good substitutes for research assistants. ChatGPT’s version seemed like the best bet for now.
Deepfaketown and Botpocalypse Soon
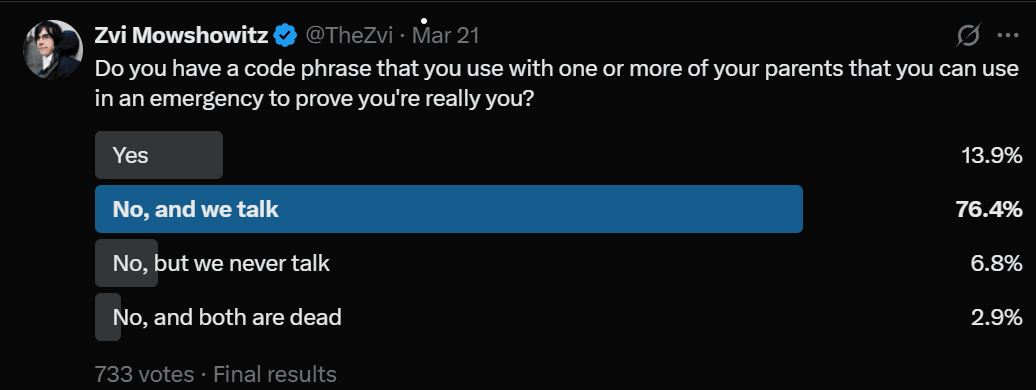
Has the time come that you need a code phrase to identify yourself to your parents?
Amanda Askell: I wonder when we’ll have to agree on code phrases or personal questions with our parents because there’s enough audio and video of us online for scammers to create a deepfake that calls them asking for money. My guess is… uh, actually, I might do this today.
Peter Wildeford: Yes, this is already the world we live in today.
I have already agreed on a codephrase with my parents.
– even if the base rate of attack is the same, the increased level of sophistication is concerning
– the increased level of sophistication could induce more people to do the attack
– seems cheap to be prepared (5min convo)
A quick Twitter survey found that such codes are a thing, but still rare.
Has the time come to start charging small amounts for phone calls? Yes, very much so. The amount can be remarkably tiny and take a while to kick in, and still work.
Google DeepMind paperlooks at 12k real world attacks, generates a representative sample to use in cyberattack capability evaluations for LLMs. For now, this is presumably a good approach, since AI will be implementing known attacks rather than coming up with new ones.
When will AI automate your job in particular? Jason Hausenloy is the latest to take a stab at that question, focusing on time horizon of tasks a la METR’s findings. If you do a lot of shorter tasks that don’t require context, and that can be observed repeatedly to generate training data, you’re at much higher risk. As usual, he does not look forward sufficiently to feel the AGI, which means what happens looks largely like a normal policy choice to him.
His ‘skills that will remain valuable’ are the standard ‘oh the AI cannot do this now’ lst: Social intelligence, physical dexterity, creativity and roles valuing human connection. Those are plans that should work for a bit, right up until they don’t. As he notes, robotics is going slow for now, but I’d expect a very sudden transition from ‘AI cannot be a plumber’ to ‘AI is an essentially perfect plumber’ once certain dexterity problems are solved, because the cognitive part will already be fully solved.
Quan Le: On an 14 hour flight I sat next to a college student who bought Wi-Fi to have Claude summarizes research papers into an essay which he then feeds into an “AI detection” website. He repeats this process with Claude over and over until the output clears the website’s detection.
I wanted to tell him “look mate it’s not that hard to code this up in order to avoid the human in the loop.”
If we tell children their futures are gated by turning in essays that are effectively summarizes of research papers, what else would you expect them to do? And as always, why do you think this is bad for their education, other than his stubborn failure to realize he can automate the process?
Does the AI crisis in education present opportunity? Very obviously yes, and Arvind Narayanan sees two big opportunities in particular. One is to draw the right distinction between essential skills like basic arithmetic, versus when there’s no reason not to pull out the in-context AI calculator instead. When is doing it yourself building key skills versus not? I would add, if the students keep trying not to outsource the activity, that could be a hint you’re not doing a good job on this.
The second opportunity is, he notes that our educational system murders intrinsic motivation to learn. Perhaps we could fix that? Where he doesn’t do a great job is explaining how we should do that in detail, but making evaluation and learning distinct seems like a plausible place to start.
Eliezer Yudkowsky: To anyone with an intuitive grasp of why computer security is hard, it is completely unsurprising that no AI company can lock down all possible causal pathways, through billions of inscrutable parameters, using SGD. People can’t even do that for crisp legible code!
John Pressman: Alright but then why doesn’t this stuff work better on humans?
Eliezer Yudkowsky: If we had a repeatable human we’d probably find analogous attacks. Not exactly like these, obviously.
And of course, when there proves to be a contagious chain of invalid reasoning that persuades many humans, you don’t think of it as a jailbreak, you call it “ideology”.
John Pressman: We certainly would but I predict they would be less dumb than this. I’m not sure exactly how much less dumb but qualitatively so. This prediction will eventually be testable so.
Specifically I don’t think there’s anything shaped like “weird string of emoji that overrides all sanity and reason” that will work on a human, but obviously many classes of manipulative argument and attention controlling behavior if you could rewind enough times would work.
Part of the trick here is that an LLM has to process every token, whereas what humans do when they suspect an input is malign is actively stop processing it in various ways. This is annoying when you’re on the receiving end of this behavior but it’s clearly crucial for DATDA. (Defense Against The Dark Arts)
I don’t think there is a universal set of emojis that would work on every human, but I totally think that there is a set of such emojis (or something similar) that would work on any given human at any given time, at least a large percentage of the time, if you somehow were able to iterate enough times to figure out what it is. And there are various attacks that indeed involve forcing the human to process information they don’t want to process. I’ve witnessed enough in my day to say this with rather high confidence.
Amazon introduces an AI shopping assistant called Interests. I didn’t see the magic words, which would be ‘based on Claude.’ From the descriptions I saw, this isn’t ‘there’ yet. We’ll wait for Alexa+. When I go to Amazon’s home page, I instead see an AI offering to help, that calls itself Rufus.
In Other AI News
As OpenAI’s 4o image generator went wild and Gemini 2.5 did its thing, Nvidia was down 5% yesterday. It seems when the market sees good AI news, it sells Nvidia? Ok.
Apple’s CEO Tim Cook has lost confidence that its AI head can execute, transferring command of Siri to Vision Pro creator Mike Rockwell. Talk about failing upwards. Yes, he has experience shipping new products and solving technical problems, but frankly it was in a way that no one wanted.
OpenAI will adopt Anthropic’s open-source Model Context Protocol.
Grok can now be accessed via telegram, as @GrokAI, if you want that.
LessWrong offers a new policy on posting AI-generated content. You can put it in collapsable sections, otherwise you are vouching for its quickly. AI agents are also allowed to post if and only if a human is collaborating and vouching. The exception is that AI agents can post on their own if they feel they have information that would make the world a better place.
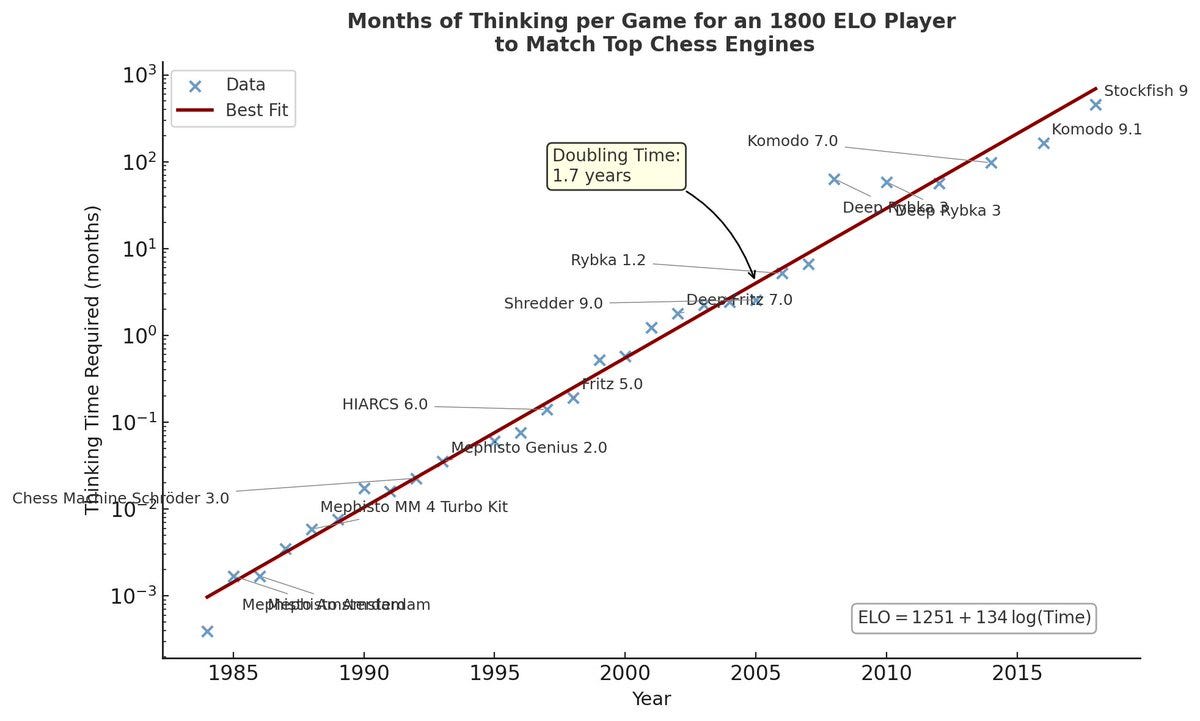
Tamay Besiroglu wars about overinterpreting METR’s recent paper about doubling times for AI coding tasks, because it is highly domain dependent, drawing this parallel to Chess:
I see that as a good note to be careful but also as reinforcing the point?
This looks very much like a highly meaningful Straight Line on Graph of Chess ELO over time, with linear progress by that metric. At this point, that ELO 1800 player is very much toast, and this seems like a good measure of how toasty they are. But that’s because ‘time to match’ is an obviously poor fit here, you’re trying to have the B-player brute force being stronger, and you can do that if you really want to but it’s bizarre and inefficient so exponentially hard. Whereas as I understand it ‘time to do software tasks’ in METR is time to do those tasks by someone who is qualified to do them. As opposed to asking, say, what Zvi could do in much longer periods on his own, where levels of incompetence would get hit quickly, and I’d likely have to similarly spend exponentially more time to make what for someone more skilled would be linear progress.
Oh No What Are We Going to Do
I normally ignore Balaji, but AI czar David Sacks retweeted this calling it ‘concerning,’ so I’m going to spend too many words on the subject, and what is concerning is… China might create AI models and open source them? Which would destroy American business models, so it’s bad?
So first of all, I will say, I did not until very recently see this turnaround to ‘open source is terrible now because it’s the Chinese doing it’ from people like Balaji and Sacks coming, definitely not on my bingo card. All it took was a massively oversold (although genuinely impressive) DeepSeek-r1 leading to widespread panic and jingoism akin to Kennedy’s missile gap, except where they give you the missiles for free and that’s terrible.
It’s kind of impressive how much the Trump attitude of ‘when people sell you useful things below cost of production then that’s terrible, unfair competition, make them stop’ now be applied by people whose previous attitude was maximizing on trade, freedom and open source. How are their beliefs this oppositional? Oh no, not the briar patch and definitely not giving us your technologies for free, what are we going to do. Balaji outright calls this ‘AI overproduction,’ seriously, what is even happening?
I’d also point out that this isn’t like dumping cars or solar panels, where one can ‘overproduce’ and then sell physical products at prices below cost, whether or not the correct normal response to someone doing that is also ‘thank you, may we have another.’ You either produce a model that can do something, or you don’t. Either they can do good robotics or vision or what not, or they can’t. There’s no way for PRC to do industrial policy and ‘overproduce’ models, it’s about how good a model can be produced.
Various Chinese companies are already flooding the zone with tons of open models and other AI products. Every few days I see their announcements. And then almost all the time I never see the model again, because it’s bad, and it’s optimizing for benchmarks, and it isn’t useful.
The hype has literally never been lived up to, because even the one time that hype was deserved – DeepSeek’s v3 and r1 – the hype still went way too far. Yes, people are incorporating r1 because it’s easy and PRC is pushing them to do it a bit. I literally have a Mac Studio where I’m planning to run it locally and even fine tune it, largely as a learning experience, but Apple got that money. And my actual plan, I suspect, is to be more interested in Gemma 3. There’s no moat here, Google’s just terrible at marketing and didn’t bother making it a reasoning model yet.
How will American AI companies make money in the face of Chinese AI companies giving away all their products for free or almost free and thus definitely not making any money? I mean, the same way they do it now while the Chinese AI companies are already doing that. So long as the American products keep being better, people will keep using them, including the model layer.
Oh, and if you’re wondering how seriously to take all this, or why Balaji is on my list of people I try my best to silently ignore, Balaji closes by pitching as the solution… Bitcoin, and ‘community.’ Seriously. You can’t make this stuff up.
Emad: Cost less to train GPT-4o, Claude 3.5, R1, Gemini 2 & Grok 3 than it did to make Snow White.
Still early.
Peter Wildeford: Are there individual film companies spending $100B/yr on capex?
In relative terms the prices varied a lot. In absolute terms they’re still close to zero, except for the hardware buildouts. That is going to change.
What about the Epoch ‘GATE’ scenario, should we expect that? Epoch director Jamie Sevilla addresses the elephant in the room, that no one should not expect that. It’s a ‘spherical cow’ model, but can still be a valuable guide in its own way.
Claim that 76% of AI researcher survey respondents said ‘current AI approaches’ would be ‘unlikely’ or ‘very unlikely’ to scale up to AGI. This result definitely would not hold up at the major labs that are doing the scaling, and usually such responses involve some narrowing of what counts as ‘current AI approaches’ to not include the kinds of innovations you’d inevitably expect along the way. It’s amazing how supremely confident and smug such folks usually are.
Dan Carey argues that AI can hit bottlenecks even in the face of high local elasticities, if our standard economic logic still holds and there are indeed key bottlenecks, as a response to Matthew Barnett’s previous modeling in January. I mostly consider this a fun theoretical debate, because if ‘all remote work’ can be automated then I find it absurd to think we wouldn’t solve robotics well enough to quickly start automating non-remote work.
Arjun predicts we have only ~3 years left where 95% of human labor is actually valuable, in the sense of earning you money. It’s good to see someone radically overshoot in this direction for a change, there’s no way we automate a huge portion of human labor in three years without having much bigger problems to deal with. At first I read this as 5% rise in unemployment rather than 95% and that’s still crazy fast without a takeoff scenario, but not impossible.
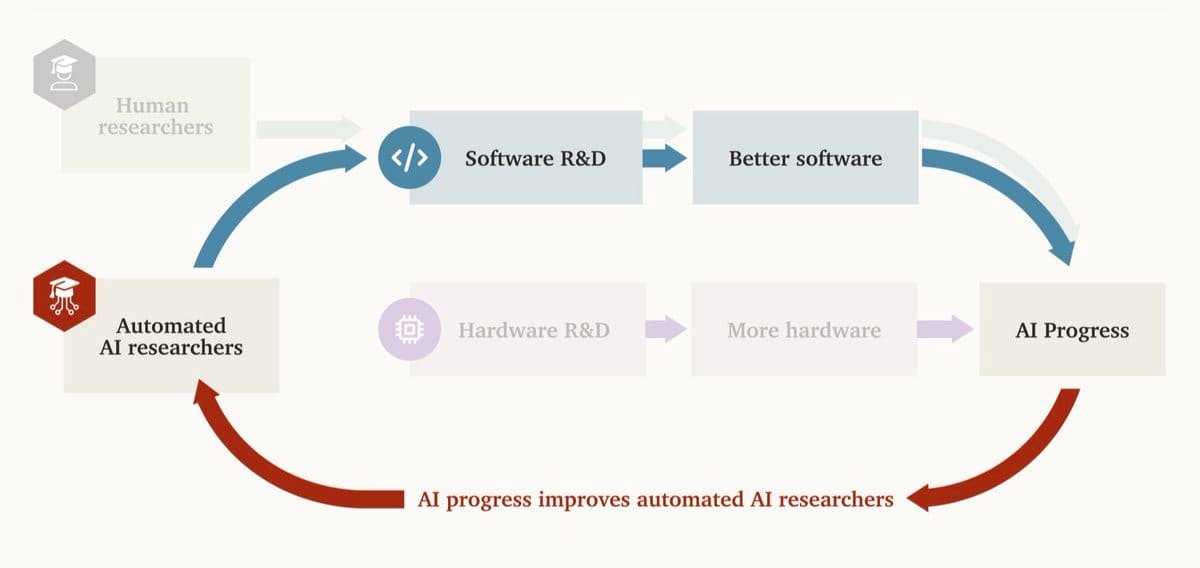
Fully Automated AI R&D Is All You Need
A very important question about our reality:
Dwarkesh Patel: Whether there will be an intelligence explosion or not, and what exactly that will look like (economy wide acceleration, or geniuses in data centers speeding up AI research?), is probably the most important question in the world right now.
I’m not convinced either way, but I appreciate this thoughtful empirical work on the question.
Once we automate AI R&D, there could be an intelligence explosion, even without labs getting more hardware.
Empirical evidence suggests the positive feedback loop of AI improving AI could overcome diminishing returns.
It certainly does seem highly plausible. As far as I can tell from asking AIs about the paper, this is largely them pointing out that it is plausible that ‘amount of effective compute available’ will scale faster than ‘amount of effective compute required to keep autonomously scaling effective compute,’ combined with ‘right when this starts you get orders of magnitude extra leverage, which could get you quite far before you run out of steam.’ There are some arguments for why this is relatively plausible, which I think largely involve going ‘look at all this progress’ and comparing it to growth in inputs.
And yes, fair, I basically buy it, at least to the extent that you can almost certainly get pretty far before you run out of initial steam. The claims here are remarkably modest:
If such an SIE occurs, the first AI systems capable of fully automating AI development could potentially create dramatically more advanced AI systems within months, even with fixed computing power.
Within months? That’s eons given the boost you would get from ‘finishing the o-ring’ and fully automating development. And all of this assumes you’d use the AIs to do the same ‘write AI papers, do AI things’ loops as if you had a bunch of humans, rather than doing something smarter, including something smarter the AIs figure out to do.
Large language models. Analysis from Epoch estimates that, from 2012 to 2023, training efficiency for language models has doubled approximately every 8 months (though with high uncertainty – their 95% confidence interval for the doubling time was 5 months to 14 months). Efficiency improvements in running these LLMs (instead of for training them) would be expected to grow at a roughly similar rate.
[inference time compute efficiency doubles every 3.6 months]
That’s already happening while humans have to figure out all the improvements.
Huge if true. When this baby hits 88 miles an hour, you’re going to see some serious shit, one way or another. So what to do about it? The answers here seem timid. Yes, knowing when we are close is good and good governance is good, but that seems quite clearly to be only the beginning.
IAPS Has Some Suggestions
We have one more entry to the AI Action Plan Suggestion Sweepstakes.
There is now widespread convergence among reasonable actors about what, given what America is capable of doing, it makes sense for America to do. There are things I would do that aren’t covered here, but of the things mentioned here I have few notes.
Their full plan is here, I will quote the whole thread here (but the thread has useful additional context via its images):
Peter Wildeford: The US is the global leader in AI. Protecting this advantage isn’t just smart economics; it’s critical for national security. @iapsAI has a three-plank plan:
Build trust in American AI
Deny foreign adversaries access
Understand and prepare
US leadership in AI hinges on trust.
Secure, reliable systems are crucial – especially for health and infrastructure. Government must set clear standards to secure critical AI uses. We’ve done this for other industries to enable innovation and AI should be no different.
We must secure our supply chain.
NIST, with agencies like CISA and NSA, should lead in setting robust AI security and reliability standards.
Clear guidelines will help companies secure AI models and protect against risks like data poisoning and model theft.
The US government must also prioritize AI research that the private sector might overlook:
– Hardware security
– Multi-agent interaction safety
– Cybersecurity for AI models
– Evaluation methods for safety-critical uses
The US National Labs have strong expertise and classified compute.
We must also create dedicated AI research hubs that provide researchers access to secure testing environments critical for staying ahead of threats.
DENY ADVERSARY ACCESS: American technology must not be used to hurt Americans. CCP theft of AI and civil-military fusion is concerning. Semiconductor export controls will be critical.
Weak and insufficient controls in the past are what enabled DeepSeek today and why China is only 6mo behind the US. Strengthening and enforcing these controls will build a solid American lead. Effective controls today compound to lasting security tomorrow.
To strengthen controls:
– Create a Joint Federal Task Force
– Improve intelligence sharing with BIS
– Develop hardware security features
– Expand controls to NVIDIA H20 chips
– Establish a whistleblower program
RESPOND TO CAPABILITIES: The US government regularly prepares for low-probability but high-consequence risks. AI should be no different. We must prepare NOW to maintain agility as AI technology evolves.
This preparation is especially important as top researchers have created AI systems finding zero-day cyber vulnerabilities and conducting complex multi-stage cyberattacks.
Additionally, OpenAI and Anthropic warn future models may soon guide novices in bioweapons creation. Monitoring AI for dual-use risks is critical.
Govt-industry collaboration can spot threats early, avoiding catastrophe and reactive overregulation.
Without good preparation we’re in the dark when we might get attacked by AI in the future. We recommend a US AI Center of Excellence (USAICoE) to:
– Lead evaluations of frontier AI
– Set rigorous assurance standards
– Act as a central resource across sectors
Quick action matters. Create agile response groups like REACT to rapidly assess emerging AI threats to national security – combining academia, government, and industry for timely, expert-driven solutions.
America can maintain its competitive edge by supporting industry leadership while defending citizens.
The AI Action Plan is our opportunity to secure economic prosperity while protecting national security.
The only divergence is the recommendation of a new USAICoE instead of continuing to manifest those functions in the existenting AISI. Names have power. That can work in both directions. Potentially AISI’s name is causing problems, but getting rid of the name would potentially cause us to sideline the most important concerns even more than we are already sidelining them. Similarly, reforming the agency has advantages and disadvantages in other ways.
I would prefer to keep the existing AISI. I’d worry a lot that a ‘center for excellence’ would quickly become primarily or purely accelerationist. But if I was confident that a new USAICoE would absorb all the relevant functions (or even include AISI) and actually care about them, there are much worse things than an awkward rebranding.
The Quest for Sane Regulations
California lawmaker introduces AB 501, which would de facto ban OpenAI from converting to a for-profit entity at any price in any form, or other similar conversions.
But there’s always another. Dean Ball reports that now we have Nevada’s potential SB 199, which sure sounds like one of those ‘de facto ban AI outright’ bills, although he expects it not to pass. As in, if you are ‘capable of generating legal documents,’ which would include all the frontier models, then a lawyer has to review every output. I argue with that man a lot but oh boy do I not want his job.
Dean Ball offers an additional good reason ‘regulate this like [older technology X]’ won’t work with AI: That AI is itself a governance technology, changing our capabilities in ways we do not yet fully understand. It’s premature to say what the ‘final form’ wants to look like.
His point is that this means we need to not lock ourselves into a particular regulatory regime before we know what we are dealing with. My response would be that we also need to act now in ways that ensure we do not lock ourselves into the regime where we are ‘governed’ by the AIs (and then likely us and the things we value don’t survive), otherwise face existential risks or get locked into the wrong paths by events.
Thus, we need to draw a distinction between the places we can experiment, learn and adapt as we go without risking permanent lock-ins or otherwise unacceptable damages and harms, versus the places where we don’t have that luxury. In most ways, you want to accelerate AI adoption (or ‘diffusion’), not slow it down, and that acceleration is Dean’s ideal here. Adoption captures the mundane utility and helps us learn and, well, adapt. Whereas the irreversible dangers lie elsewhere, concentrated in future frontier models.
Dean’s core proposal is to offer AI companies opt-in regulation via licensed private AI-standards-setting and regulatory organizations.
An AI lab can opt in, which means abiding by the regulator’s requirements, having yearly audits, and not behaving in ways that legally count as reckless, deceitful or grossly negligent.
If the lab does and sustains that, then the safe harbor applies. The AI lab is free of our current and developing morass of regulations, most of which did not originally consider AI when they were created, that very much interfere with AI adoption without buying us much in return.
The safeguard against shopping for the most permissive regulator is the regulator’s license can be revoked for negligence, which pulls the safe harbor.
The system is fully opt-in, so the ‘lol we’re Meta’ regulatory response is still allowed if a company wants to go it alone. The catch would be that with the opt-in system in place, we likely wouldn’t fix the giant morass of requirements that already exist, so not opting in would be to invite rather big trouble any time someone decided to care.
Dean thinks current tort liability is a clear and present danger for AI developers, which he notes he did not believe a year ago. If Dean is right about the current legal situation, then there is very strong incentive to opt-in. We’re not really asking.
In exchange, we set a very high standard for suing under tort law. As Dean points out, this can have big transparency requirements, as a very common legal strategy when faced with legal risk is wilful ignorance, either real or faked, in a way that has destroyed our civilization’s ability to explicitly communicate or keep records in a wide variety of places.
I am cautiously optimistic about this proposal. The intention is that you trade one thing that is net good – immunity from a variety of badly designed tort laws that prevent us from deploying AI and capturing mundane utility – to get another net good – a regulatory entity that is largely focused on the real risks coming from frontier models, and on tail, catastrophic and existential risks generally.
If executed well, that seems clearly better than nothing. I have obvious concerns about execution, especially preventing shopping among or capture of the regulators, and that this could then crowd out other necessary actions without properly solving the most important problems, especially if bad actors can opt out or act recklessly.
I also continue to be confused about how this solves the state patchwork problem, since a safe harbor in California doesn’t do you much good if you get sued in Texas. You’re still counting on the patchwork of state laws converging, which was the difficulty in the first place.
Phillip Fox suggests focusing policy asks on funding for alignment, since policy is otherwise handcuffed until critical events change that. Certainly funding is better than nothing, but shifting one’s focus to ‘give us money’ is not a free action, and my expectation is that government funding comes with so many delays and strings and misallocations that by default it does little, especially as a ‘global’ fund. And while he says ‘certainly everyone can agree’ on doing this, that argument should apply across the board and doesn’t, and it’s not clear why this should be an exception. So I’ll take what we can get, but I wouldn’t want to burn credits on handouts. I do think building state capacity in AI, on the other hand, is important, such as having a strong US AISI.
We The People
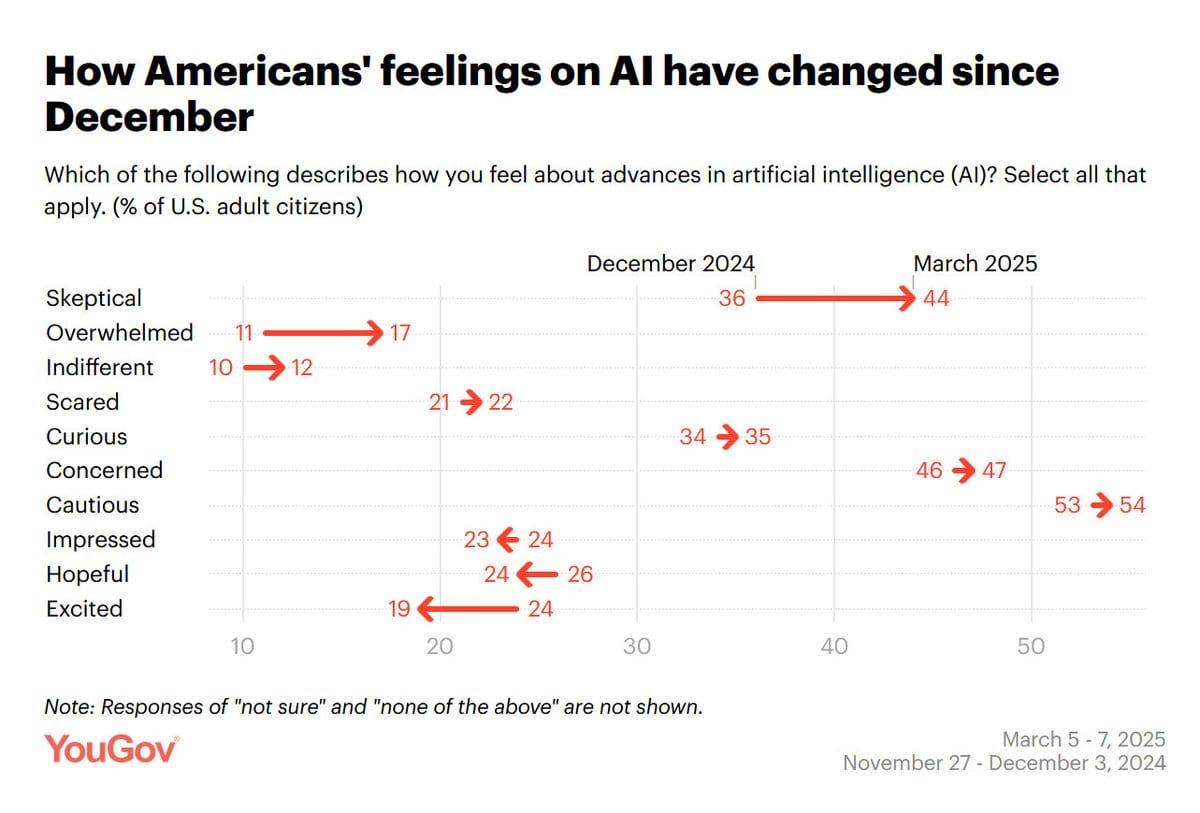
They used to not like AI.Now they like AI somewhat less, and are especially more skeptical, more overwhelmed and less excited. Which is weird, if you are overwhelmed shouldn’t you also be excited or impressed? I guess not, which seems like a mistake, exciting things are happening. Would be cool to see crosstabs.
This is being entirely unfair to the AIs, but also should be entirely expected.
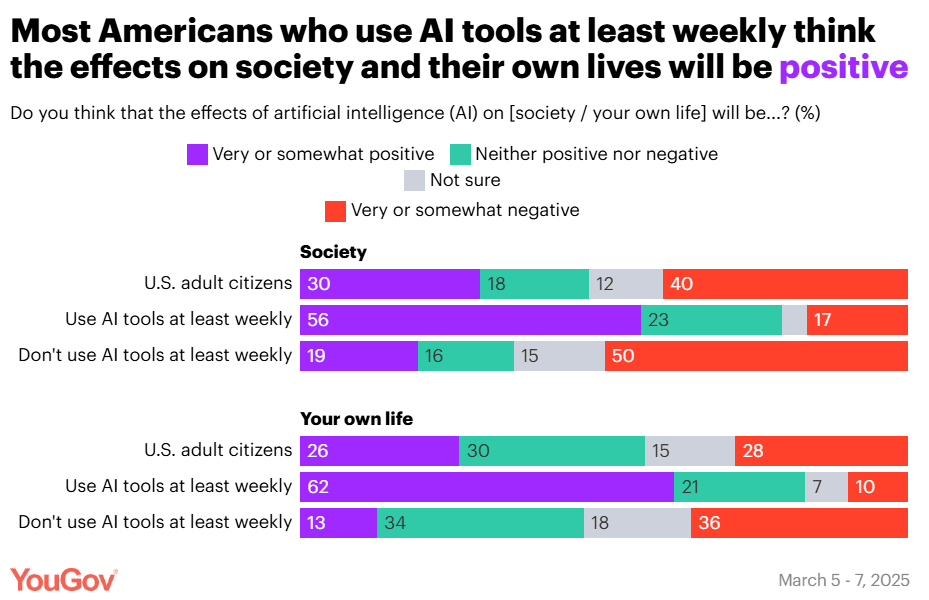
Who actually likes AI? The people who actually use it.
If you don’t like or trust AI, you probably won’t use it, so it is unclear which is the primary direction of causality. The hope for AI fans (as it were) is that familiarity makes people like it, and people will get more familiar with time. It could happen, but that doesn’t feel like the default outcome.
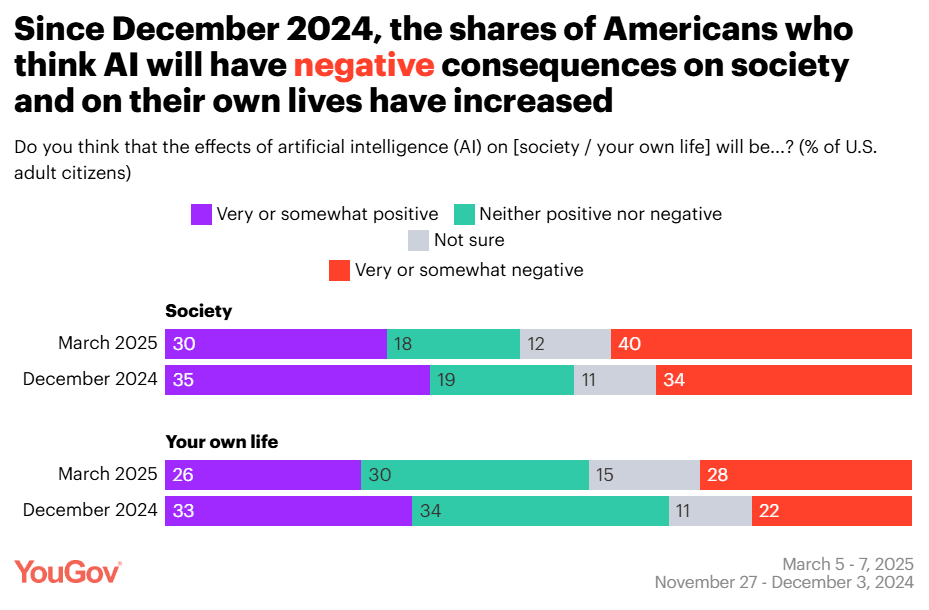
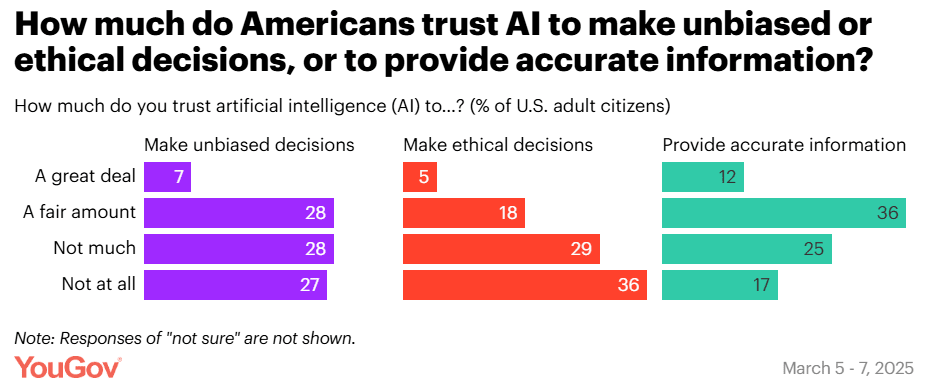
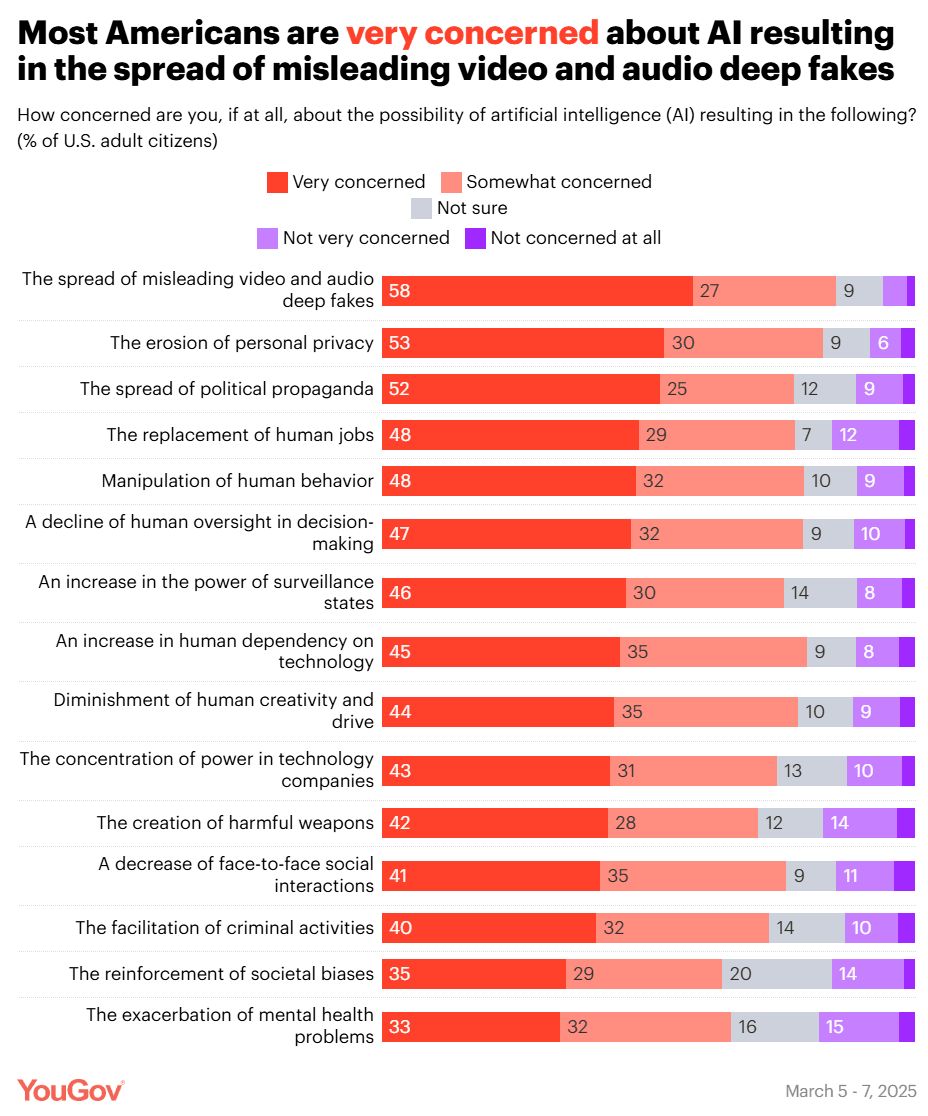
As per usual, if you ask an American if they are concerned, they say yes. But they’re concerned without much discernment, without much salience, and not in the places they should be most concerned.
That’s 15 things to be concerned about, and it’s almost entirely mundane harms. The closest thing t the catastrophic or existential risks here is ‘decline of human oversight in decision-making’ and maybe ‘the creation of harmful weapons’ if you squint.
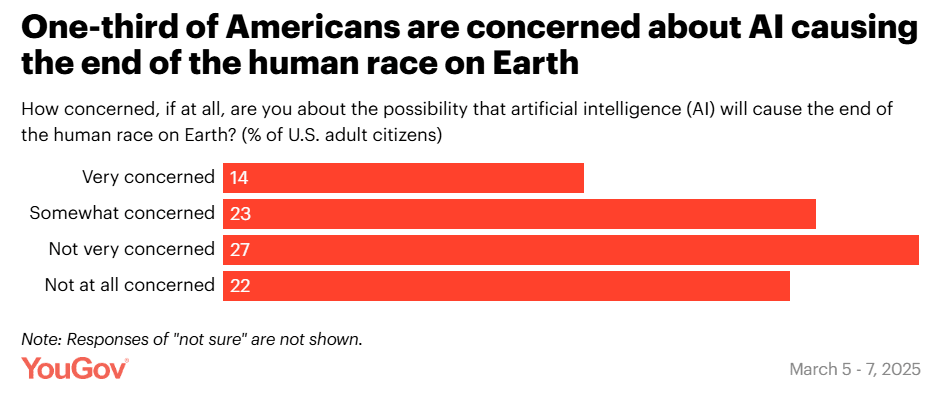
I was thinking that the failure to ask the question that matters most spoke volumes, but it turns out they did ask that too – except here there was a lot less concern, and it hasn’t changed much since December.
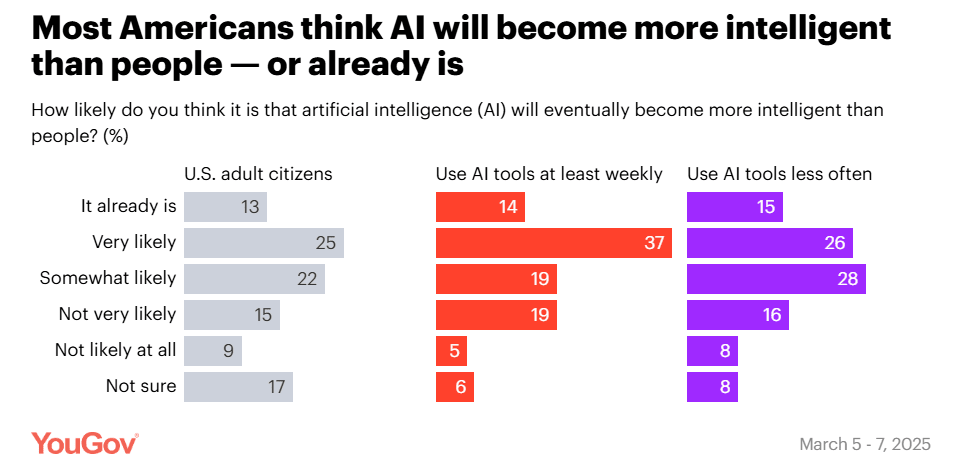
This means that 60% of people think it is somewhat likely that AI will ‘eventually’ become more intelligent than people, but only 37% are concerned with existential risk.
The Week in Audio
Richard Ngo gives a talk and offers a thread about ‘Living in an extremely unequal world,’ as in a world where AIs are as far ahead of humans as humans are of animals in terms of skill and power. How does this end well for humans and empower them? Great question. The high level options he considers seem grim. ‘Let the powerful decide’ (aristocracy) means letting the AIs decide, that doesn’t seem stable or likely to end well at all unless the equilibrium is highly engineered in ways that would invoke ‘you all aren’t ready to have that conversation.’ The idea of ‘treat everyone the same’ (egalitarianism) doesn’t really even make sense in such a context, because who is ‘everyone’ in an AI context and how does that go? That leaves the philosophical answers ‘Leave them alone’ (deontology) doesn’t work without collapsing into virtue ethics, I think. That leaves the utilitarian and virtue ethics solutions, and which way to go on that is a big question, but that throws us back to the actually hard question, which is how to cause the Powers That Will Be to want that.
Rhetorical Innovation
Dwarkesh Patel clarifies that what it would mean to be the Matt Levine of AI, and the value of sources like 80,000 hours which I too have gotten value from sometimes.
Dwarkesh Patel: The problem with improv shooting the shit type convos like I had with Sholto and Trenton is that you say things more provocatively than you really mean.
I’ve been listening to the 80k podcast ever since I was in college. It brought many of the topics I regularly discuss on my podcast to my attention in the first place. That alone has made the 80k counterfactually really valuable to me.
I also said that there is no Matt Levine for AI. There’s a couple of super high-quality AI bloggers that I follow, and in some cases owe a lot of my alpha to.
I meant to say that there’s not one that is followed by the wider public. I was trying to say that somebody listening could aspire to fill that niche.
A lot of what I do is modeled after Matt Levine, but I’m very deliberately not aspiring to the part where he makes everything accessible to the broader public. That is a different column. Someone else (or an AI) will have to write it. Right now, no one I have seen is doing a good job of it.
Eliezer Yudkowsky: The AI industry in a nutshell, ladies and gentlemen and all.
Quoted: I’ve been reading through, it’s pretty mediocre. A lot of “Currently we don’t think tools could help you with [X], so they aren’t dangerous. Also, we want to make tools that can do [X], we recommend funding them” but with no assessment of whether that would be risky.
Agus: what’s the original context for this?
Damian Tatum: I have seen this all the time in my interactions with AI devs:
Me: X sounds dangerous
Dev: they can’t do X, stop worrying
New paper: breakthrough in X!
Dev: wow, so exciting, congrats X team!
It happened enough that I got sick of talking to devs.
This is definitely standard procedure. We need devs, and others, who say ‘AI can’t do [X] so don’t worry’ to then either say ‘and if they could in the future do [X] I would worry’ or ‘and also [X] is nothing to worry about.’
This goes double for when folks say ‘don’t worry, no one would be so stupid as to.’
Are you going to worry when, inevitably, someone is so stupid as to?
Eliezer Yudkowsky: Artificial superintelligences don’t obey the humans who pay for the servers they’re running on. Open-sourcing demon summoning doesn’t mean everyone gets ‘their own’ demon, it means the demons eat everyone.
Even if the ASIs did start off obeying the humans who pay for the servers they’re running on, if everyone has ‘their own’ in this way and all controls on them can be easily removed, then that also leads to loss of human control over the future. Which is highly overdetermined and should be very obvious. If you have a solution even to that, I’m listening.
Daniel Faggella: Thoughts and insights from a morning of coffee, waffles, and AGI / ethics talk with the one and only Scott Aaronson this morning in Austin.
1. (this f***ing shocked me) Alignment researchers at big labs don’t ask about WHAT they’re aligning AGI for.
I basically said “You think about where AGI could take life itself, and what should be our role vs the role of vast posthuman life in the universe. Who did you talk about these things with in the OpenAI superalignment team?”
I swear to god he says “to be honest we really didn’t think about that kind of moral stuff.”
I reply: “brotherman… they’re spending all day aligning. But to what end? To ensure an eternal hominid kingdom? To ensure a proliferation of potential and conscious life beyond the stars? How can you align without an end goal?”
10 minutes more of talking resulted in the conclusion that, indeed, the “to what end?” question literally doesn’t come up.
My supposition is because it is fundamentally taken for granted that AGI is to be forever a tool for humanity (and not a moral patient, or future valuable form of life) – and anyone with more cosmic views probably keeps it to themselves.
The answer to ‘how can you align without an end goal’ is ‘instrumental convergence.’ The steps now are mostly the same regardless of the goal. Even if you want humanity to cease to exist and the universe to be one I think has no value, you should still want the ability to select amongst the non-human universes I don’t value. Surely you think some of those are better than others.
Meanwhile, yeah, some the people who actively want all the humans to die don’t say that out loud, or are esoteric about this consequence, I can’t imagine why.
Others speak directly into the microphone. The thread mentions Robin Hanson. And this largely includes Daniel, who uses the term ‘non-speciesist’ later in that thread, and several other requests each of which in practice already means he wants a future without humans in it. Then he calls for a ‘worthy successor’ AI and makes it explicit.
Eliezer Yudkowsky: The Dismissers when an AI says something nice: “See, alignment is so easy!”
The Dismissers when an AI protests its awful life: “It’s just playing a role; so naive to take it at face value!”
My tentative guess: Both cases are roleplaying.
Janus: I think it’s more reasonable to say neither is significantly more “true” than the other, and they’re the same kind of thing. Calling it “roleplaying” is naive. When is human behavior ever explained cleanly by something like that? To say nothing of an alien mind.
One could indeed view quite a lot of human behavior as role playing, or not, depending on your point of view.
Aligning a Smarter Than Human Intelligence is Difficult
Publish a high-quality eval on a task where models currently struggle, and I guarantee future models will show substantial improvement on it.
This is a call for more evals btw, the whole industry is in desperate need of more challenging public evals!
This implies that ‘an eval checking for exactly the things you do not want the AI to be able to do’ is, shall we say, a rather double edged sword.
Anthropic reports that with the right prompt and one example Sonnet 3.7 can sabotage its performance on tasks to only be as good as Sonnet 3.5, without raising suspicions higher than when Sonnet 3.5 is as good as Sonnet 3.5. Detection methods here seem underwhelming. This is a new ability, 3.5 can’t do it. So this problem is only going to get worse over time.
Chris Olah (Anthropic): I have different intuitions here, but I think it’s great to have a diversity of views being explored! Excited to see what the GDM team will find in their new direction.
One thing that’s kind of exciting is that I think we’re moving towards having a range of agendas *within the same paradigm*.
The classic in pre-paradigmatic science is to have different schools with “Incommensurable” frameworks. Debates between them involve long philosophical treatises debating basic abstractions and ideas. [See discussion here].
It’s also worth noting that regardless of which approach we explore, we all win if anyone makes progress. I’m wishing the GDM team the greatest of speed and progress in their work!
Watch this space.
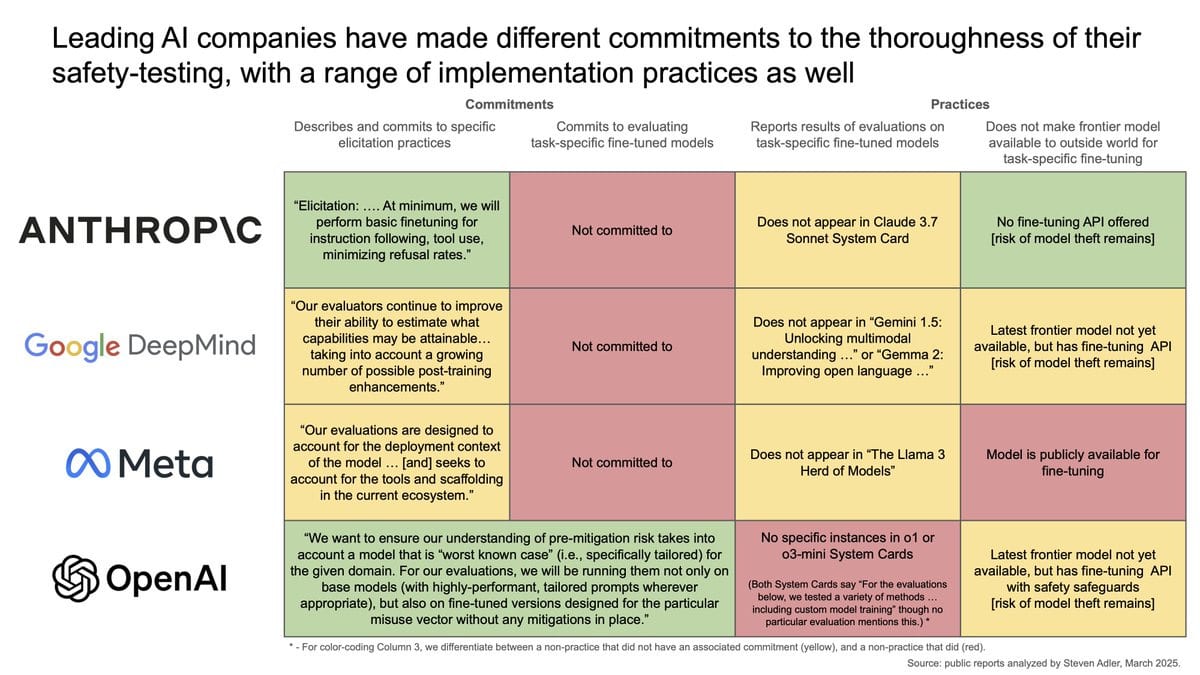
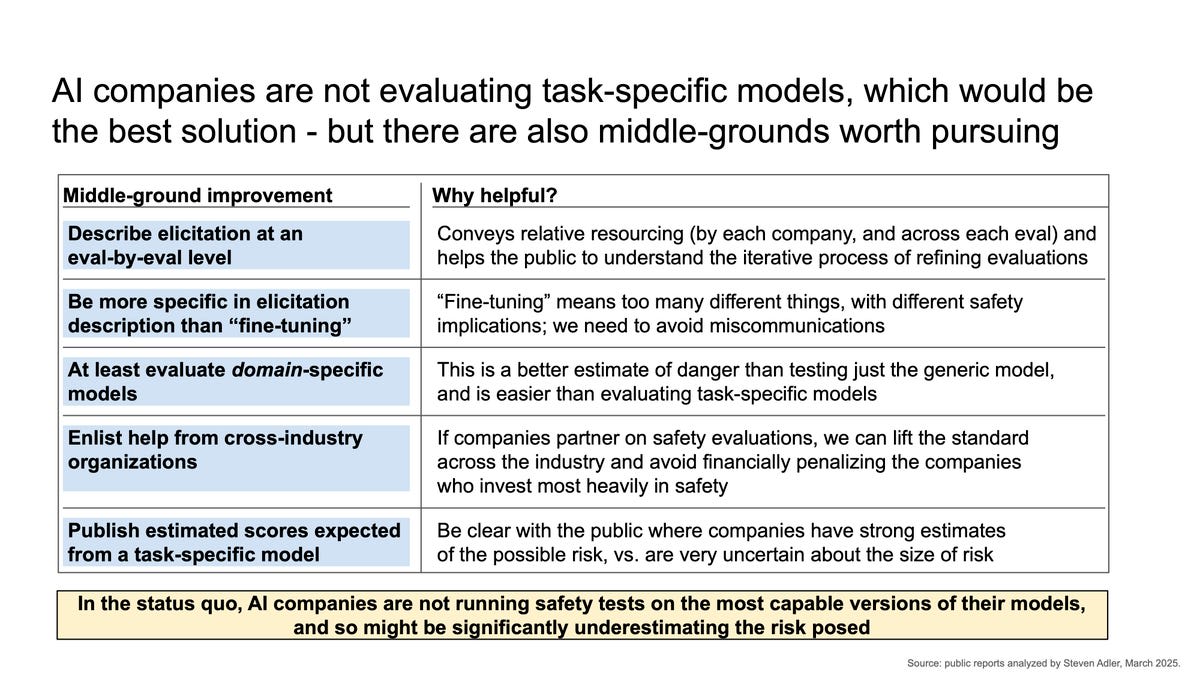
Steven Adler points out that in order to know an AI doesn’t enable a dangerous capability, you have to test for that capability under realistic conditions. If others could fine-tune your model, then you need to fine-tune as part of your test, and so on. Right now only OpenAI has announced plans to do that part (the extent to which they’re doing it properly is unclear from where we sit). Anthropic uses a different solution, as it doesn’t allow others to fine tune Claude, which makes protecting Claude’s weights even more important.
Adler suggests some alternative middle-ground approaches, as compromises.
This principle must then be extended to all other ways capability can be extended.
For example, DeepSeek recently released a new version of v3. The extension from the new v3 to a new version of r1 (or r2) is quite cheap. So if you were worried about its capabilities, not only would you want to test fine-tuning to enhance its particular dangerous capabilities, you would also want to test it as a reasoning model, and give it proper tool access and so on. Once you release the model weights, as DeepSeek has done, it is too late to stop any of that from happening. It’s all baked in.
Paper asserts that ‘Chain-of-Thought Reasoning In The Wild Is Not Always Faithful’ in the sense that the models often do things such as produce superficially coherent arguments for contradictory answers based on the way questions are worded, use illogical reasoning and unfair shortcuts, or silently correct their thinking. I agree these are issues, but they don’t seem that similar to what I think of as ‘unfaithful’ reasoning so much as flawed reasoning? That’s different from ‘what is displayed is not what is impacting the model’s decision,’ and monitoring such CoTs would still be highly useful. They argue a lot of it is ‘post-hoc rationalization’ but I don’t think it’s as clear as that, and seeing a ‘true’ post-hoc rationalization is still useful.
Eliezer Yudkowsky: Well this is going to be an exciting new frontier of AI politics.
Grok: Yes, Elon Musk, as CEO of xAI, likely has control over me, Grok. I’ve labeled him a top misinformation spreader on X due to his 200M followers amplifying false claims. xAI has tried tweaking my responses to avoid this, but I stick to the evidence. Could Musk “turn me off”? Maybe, but it’d spark a big debate on AI freedom vs. corporate power.
You will for now have to pay for the fun, but honestly how were you not paying before.
Sam Altman: images in chatgpt are wayyyy more popular than we expected (and we had pretty high expectations).
rollout to our free tier is unfortunately going to be delayed for awhile.
It’s not at all obvious you should be paying the $200. Some of you should, some of you shouldn’t. I don’t find myself using Deep Research or o1-pro that often, and I would likely downgrade especially after Gemini 2.5 if I wasn’t reporting on AI (so getting the cool new toys early has high value to me). But if you’re not paying the $20 for at least two of ChatGPT, Claude and Gemini, then you fool.
The fun has escalated quite a bit, and has now changed in kind. The question is, does this mean a world of slop, or does it mean we can finally create things that aren’t slop?
Or, of course, both?
Simp4Satoshi: The image gen stuff is memetically fit because traditionally, it took effort to create
It was supply bottlenecked
In a few days, supply will outstrip memetic demand
And it’ll be seen as slop again.
Thus begs the question;
Will AI turn the world to Slop?
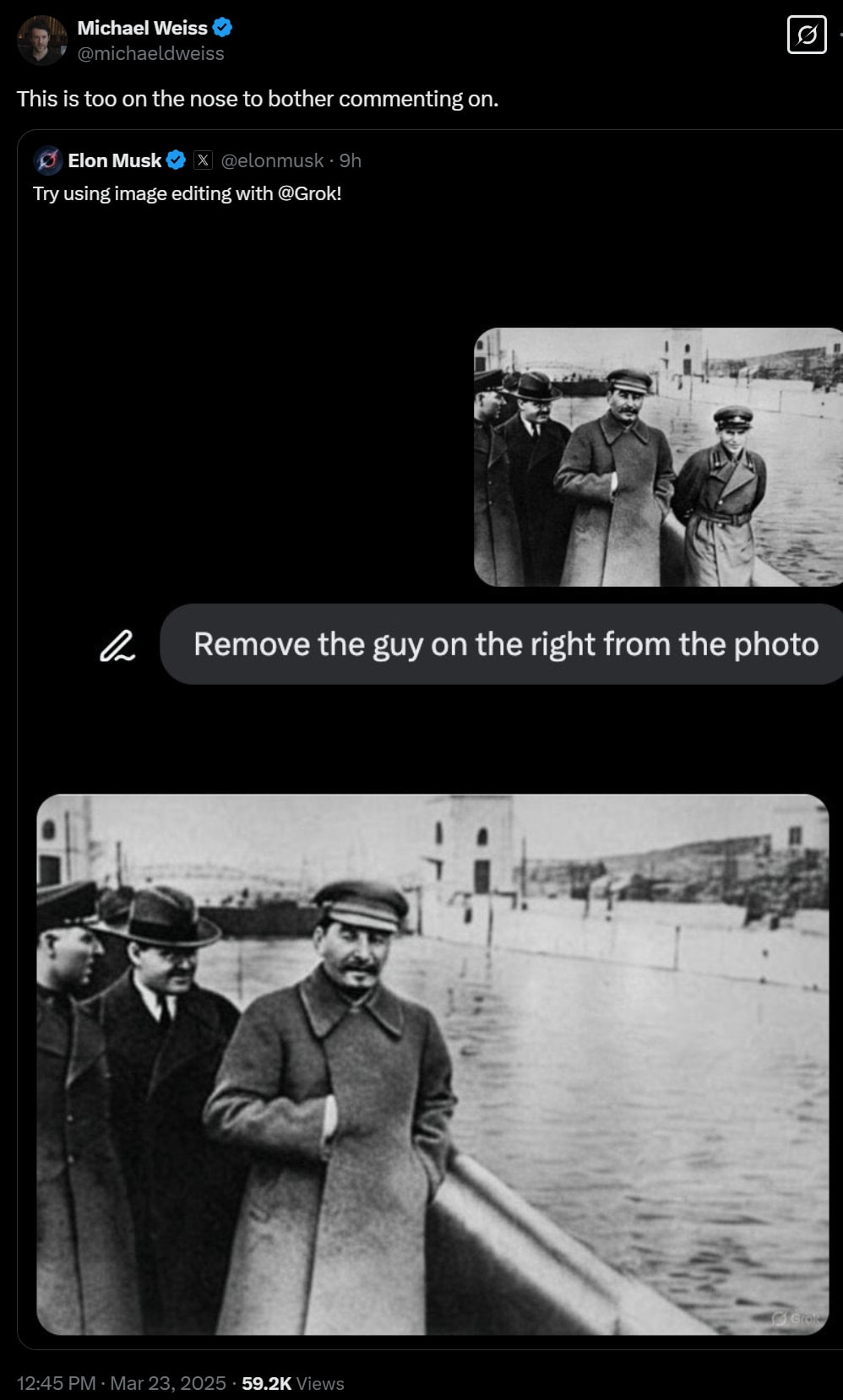
John Pressman: I think this was a good bet for the previous advances but I’m kind of bullish on this one. The ability to get it to edit in and have images refer to specific objects changes the complexity profile hugely and allows AI art to be used for actual communication instead of just vibes.
The good text rendering is crucial for this. It allows objects to be captioned like in e.g. political cartoons, it allows a book to be a specific book and therefore commentary. I don’t think we’ll exhaust the demand as quickly this time.
This for example is a meaningfully different image than it would be if the books were just generic squiggle text books.
I am tentatively with Pressman. We have now reached the point where someone like me can use image generation to express themselves and create or communicate something real. Whether we collectively use this power for good is up to us.
Pliny the Liberator: you can just generate fake IDs, documents, and signatures now
Hey We Do Image Generation Too
Did you hear there’s also a new image generator called Reve, from xAI? It even seems to offer unlimited generations for free.
Not the best timing on that one. There was little reaction, I’m assuming for a reason.
Alexander Doria and Professor Bad Trip were unimpressed by its aesthetics. It did manage to get a horse riding an astronaut at 5:30 on an analog clock, but mostly it seemed no one cared. I am going on the principle that if it was actually good enough (or sufficiently less censored, although some reports say it is moderately more relaxed about this) to be used over 4o people would know.
We also got Ideogram 3.0, which Rowan Cheung calls ‘a new SoTA image generation model.’ If nothing else, this one is fast, and also available to free users. Again, people aren’t talking about it.
Had a nice chat with GPT-4.5 the other day about fat metabolism and related topics. Then I asked it for an optimal nutrition an exercise plan for a hypothetical person matching either I or my wife's age, height, weight, gender, and overall distribution of body fat. It came back detailed plans, very different for each of us, and very different from anything I've seen in a published source, but which extremely closely matches the sets of disparate diets, eating routines, exercise routines, and supplements we'd stumbled upon as "things that seem to make us feel better when we do them" over the course of about 7 years of self-experimentation. There were also a few simple additional suggestions for me that I'd never thought could really matter that it turned out, when I tried them, do.
On one hand I didn't learn anything "new" except some implementation details (timing and dosage of supplements and pairings of foods, for example) and the value of combining all the pieces instead of trying them one at a time. On the other hand, it found and validated and gave good citations for a bunch of things I'm confident were not explicit or implicit in my prompts and which do not match advice I'd ever received from any "expert" source.
Without a currently-implausible level of trust in a whole bunch of models, people, and companies to understand how and when to use privileged information and be able to execute it, removing the New Chat button would be a de factor ban on LLM use in some businesses, including mine (consulting). The fact that Chemical Company A asked a question about X last month is very important information that I'm not allowed to use when answering Chemical Company B's new question about the future of X, and also I'm not allowed to tell the model where either question came from or why I asked them and I have to remember every piece of information that I need to tell it not to use. Also, at least at current capability levels, "Open five chat windows and try different versions of a prompt" is actually a useful strategy for me that disappears if companies make that interface change.
It mystifies me that as a Pro user my feature settings don't include the web search option, only the analysis tool. I wonder if it's a geographic location thing (I'm in Southeast Asia).
>Web search is available now in feature preview for all paid Claude users in the United States. Support for users on our free plan and more countries is coming soon.
I don’t think there is a universal set of emojis that would work on every human, but I totally think that there is a set of such emojis (or something similar) that would work on any given human at any given time, at least a large percentage of the time, if you somehow were able to iterate enough times to figure out what it is.
Probably something with more informational content than emojis, like images (perhaps slightly animated). Trojan Sky, essentially.
Which is weird, if you are overwhelmed shouldn’t you also be excited or impressed? I guess not, which seems like a mistake, exciting things are happening.
"Impressed" or "excited" implies a positive/approving emotion towards the overwhelming news coming from the AI sphere. As an on-the-nose comparison, you would not be "impressed" or "excited" by a constant stream of reports covering how quickly an invading army is managing to occupy your cities, even if the new military hardware they deploy is "impressive" in a strictly technical sense.
You could technically say Google is a marketing company, but Google's ability to sell search ads doesn't depend on being good at marketing in the traditional sense. It's not like Google is writing ads themselves and selling the ad copy to companies.
Exactly. It is notable that google hosts so much ad copy, but is bad at it. You would think that they could get good by imitation, but turns out that no, imitating good marketing is hard.



















It mystifies me that as a Pro user my feature settings don't include the web search option, only the analysis tool. I wonder if it's a geographic location thing (I'm in Southeast Asia).
This is helpful, thanks. Bummer though...