Authors: Senthooran Rajamanoharan*, Arthur Conmy*, Lewis Smith, Tom Lieberum, Vikrant Varma, János Kramár, Rohin Shah, Neel Nanda
A new paper from the Google DeepMind mech interp team: Improving Dictionary Learning with Gated Sparse Autoencoders!
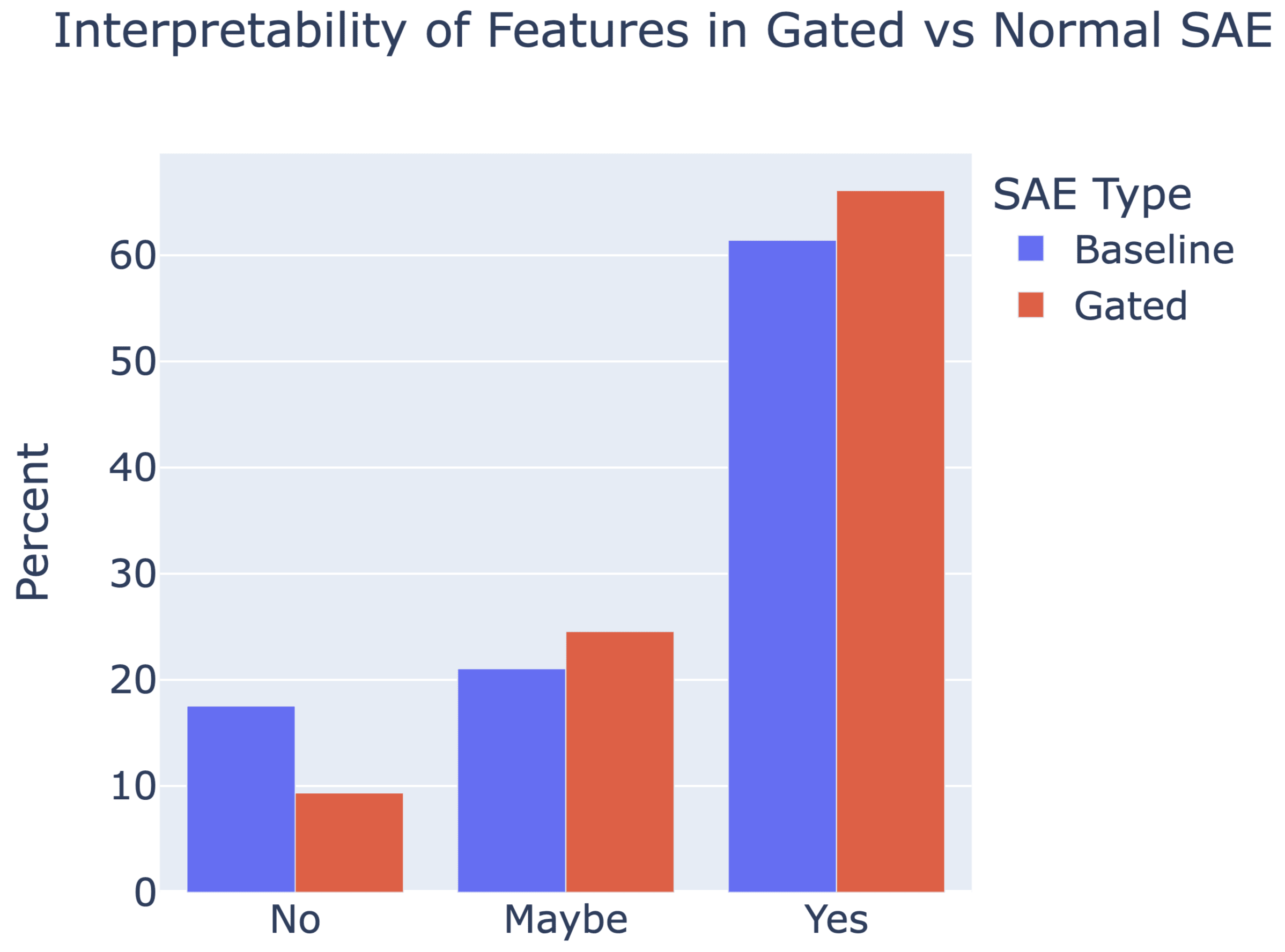
Gated SAEs are a new Sparse Autoencoder architecture that seems to be a significant Pareto-improvement over normal SAEs, verified on models up to Gemma 7B. They are now our team's preferred way to train sparse autoencoders, and we'd love to see them adopted by the community! (Or to be convinced that it would be a bad idea for them to be adopted by the community!)

They achieve similar reconstruction with about half as many firing features, and while being either comparably or more interpretable (confidence interval for the increase is 0%-13%).
See Sen's Twitter summary, my Twitter summary, and the paper!
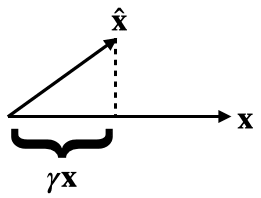

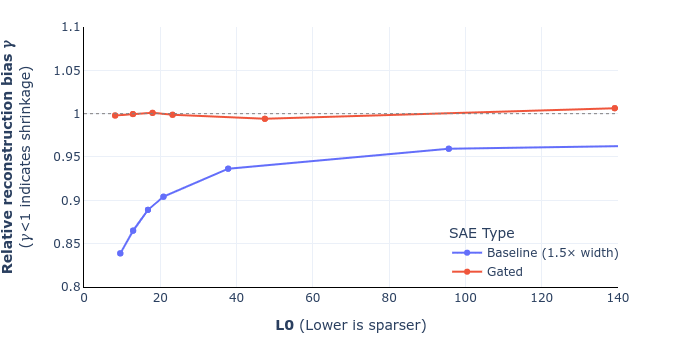
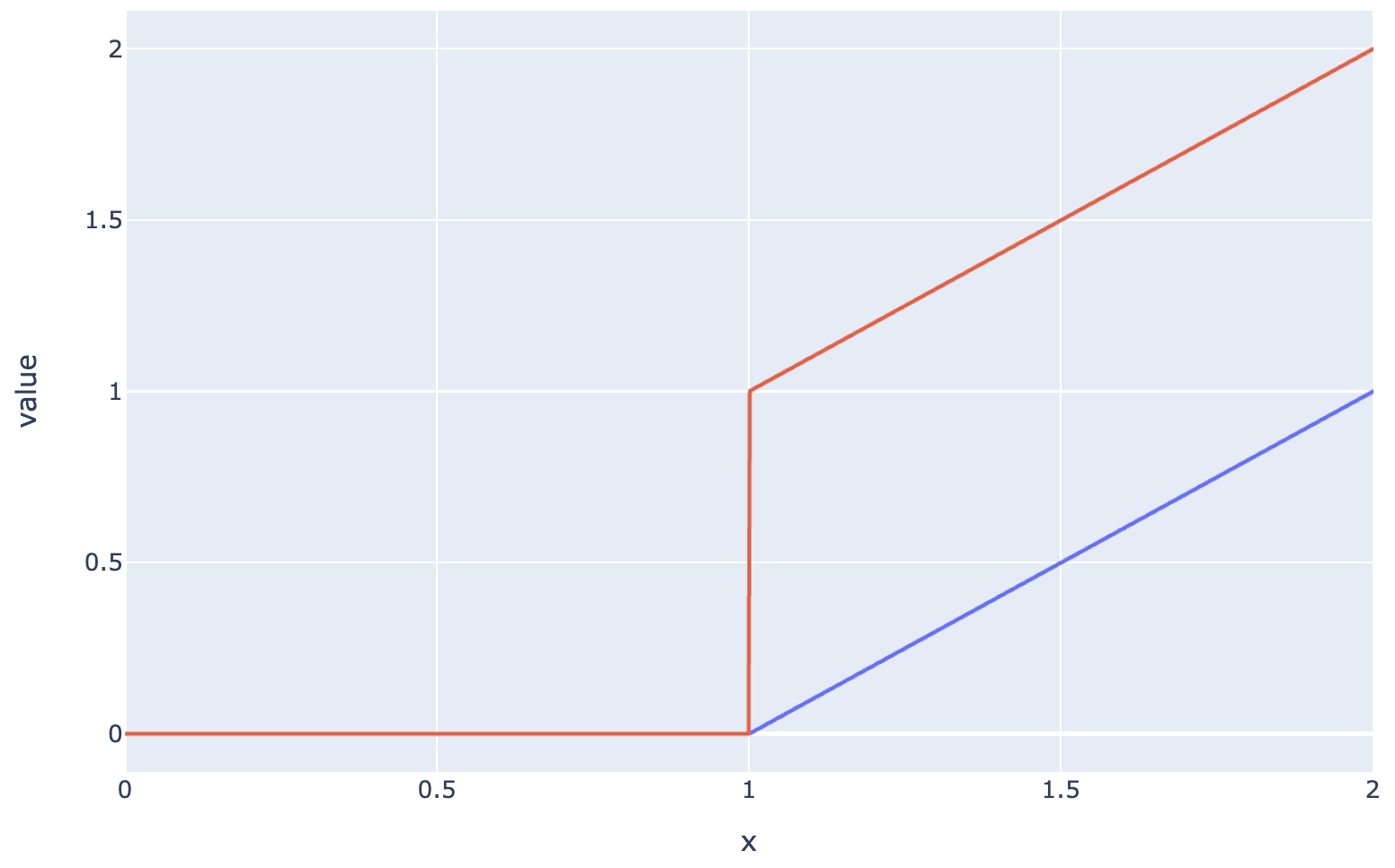
I don't think zero ablation is that great a baseline. We're mostly using it for continuity's sake with Anthropic's prior work (and also it's a bit easier to explain than a mean ablation baseline which requires specifying where the mean is calculated from). In the updated paper https://arxiv.org/pdf/2404.16014v2 (up in a few hours) we show all the CE loss numbers for anyone to scale how they wish.
I don't think compute efficiency hit[1] is ideal. It's really expensive to compute, since you can't just calculate it from an SAE alone as you need to know facts about smaller LLMs. It also doesn't transfer as well between sites (splicing in an attention layer SAE doesn't impact loss much, splicing in an MLP SAE impacts loss more, and residual stream SAEs impact loss the most). Overall I expect it's a useful expensive alternative to loss recovered, not a replacement.
EDIT: on consideration of Leo's reply, I think my point about transfer is wrong; a metric like "compute efficiency recovered" could always be created by rescaling the compute efficiency number.
What I understand "compute efficiency hit" to mean is: for a given (SAE, LM1) pair, how much less compute you'd need (as a multiplier) to train a different LM, LM2 such that LM2 gets the same loss as LM1-with-the-SAE-spliced-in.