2 Answers sorted by
30
It depends on what you mean by "the world" and what you think matters in a practical sense.
I think it's important to note that an "LLM" is a neural network that receives and emits tokens, but there is no reason it has to only be trained on languages. Images, sound, text, video, proprioception all work, and the outputs can be robotics commands like below, from https://robotics-transformer-x.github.io/ :
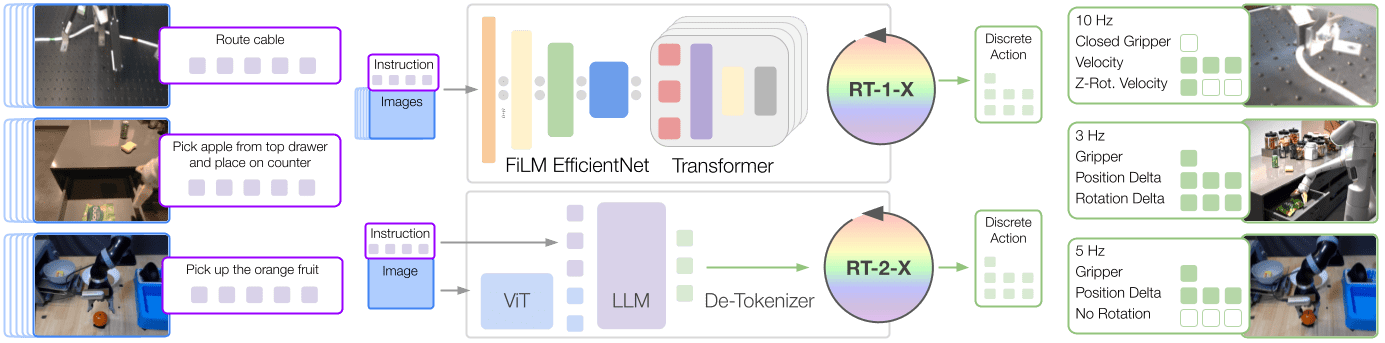
These days anything that isn't SOTA doesn't count, and this method outperforms previous methods of robotics control by 1.5x-3x.
When I see "the real world", as an ML engineer who works on embedded systems, I think of the world as literally just the space accessible to a robot. Not "the earth" but "the objects in a robotics cell or on the table in front of it".
Future AI systems will be able to handle more complex worlds, for example if mamba happens to work for robotics control as well, then the world complexity can be increased by a factor of 10-20 later this year or next year when this is integrated into robotics models.
Is this what you meant?
I think it's important to remember that the "real world" in some ways is actually easier than you might think. You gave an example,
If, after seeing a million examples you become pretty good at predicting the next token in the sequence "5 + 4 =", does this imply that you have learned something about sheep?
The world of language effectively has no rules, for instance in programming APIs a new unseen API may be missing methods on it's objects that every similar API the model has ever seen has. So the model will attempt to call those methods, 'hallucinating' code that won't run.
However the 'real' world has many consistent rules, such as gravity, friction, inertia, object fragility, permanence, and others. This means a robotic system can learn general strategies that will apply even to never seen objects, and a transformer neural network will naturally learn some form of compressed strategy in order to learn an effective robotics policy.
Example:

What happens is the "carrot" is blue? If it's a real carrot? A metal object that happens to look like a carrot? Object is covered in oil?
Is it possible for the model to attempt a grab based on wrong assumptions and change it's strategy once it learns the object is different?
Thanks for the detailed answer! I think that helped
Does the following make sense:
We use language to talk about events and objects (could be emotions, trees, etc). Since those are things that we have observed, our language will have some patterns that are related to the patterns of the world. However, the patterns in the language are not a perfect representation of the patterns in the world (we can talk about things falling away from our planet, we can talk about fire which consumes heat instead of producing it, etc). An LLM trained on text then learns the ...
10
What aspect of the real world do you think the model fails to understand?
No, seriously. Think for a minute and write down your answer before reading the rest.
You just wrote your objection using text. In the limit, a LLM that predicts text perfectly would output just what you wrote when prompted by my question (modulo some outside-text about two philosophers on LessWrong), therefore it's not a valid answer to “what part of the world does the LLM fail to model”.
I don’t really have a coherent answer to that but here it goes (before reading the spoiler): I don’t think the model understands anything about the real world because it never experienced the real world. It doesn’t understand why “a pink flying sheep” is a language construct and not something that was observed in the real world.
Reading my answer maybe we also don’t have any understanding of the real world, we have just come up with some patterns based on the qualia (tokens) that we have experienced (been trained on). Who is to say whether those patterns m...
I want to start by saying that this is my first question on LessWrong, so I apologise if I am breaking some norms or not asking it properly.
The whole question is pretty much contained in the title. I see a lot of people, Zvi included that claim we have moved beyond the idea that LLMs "simply predict the next token" and that they have some understanding now.
How is this obvious? What is the relevant literature?
Is it possible that LLMs are just mathematical representations of language? (does this question even make sense?) For example, if I teach you to count sheep by adding the number of sheep in two herds, you will get a lot of rules in the form of X + Y = Z, and never see any information about sheep. If, after seeing a million examples you become pretty good at predicting the next token in the sequence "5 + 4 =", does this imply that you have learned something about sheep?