Introducing Fatebook: the fastest way to make and track predictions
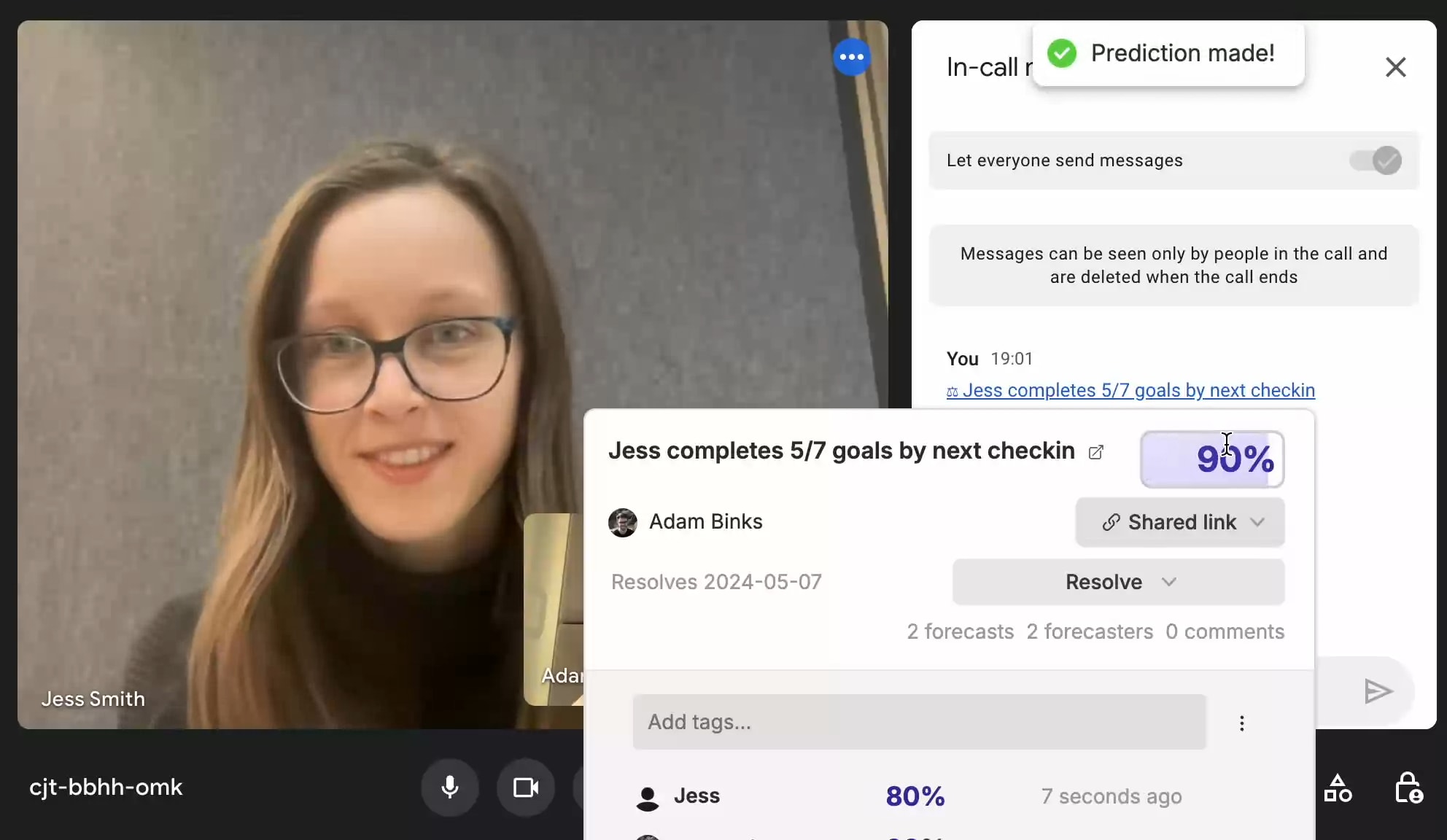
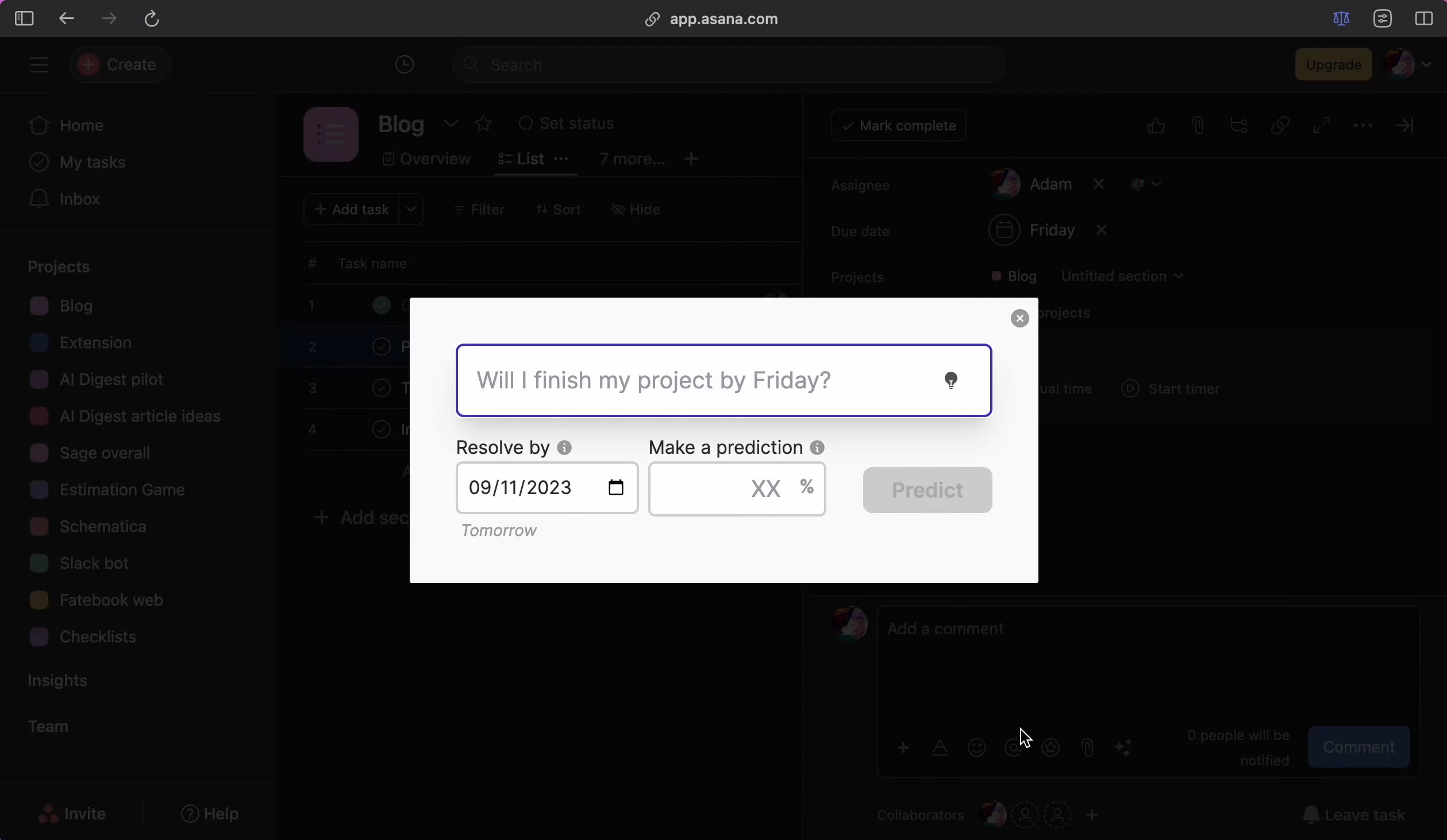
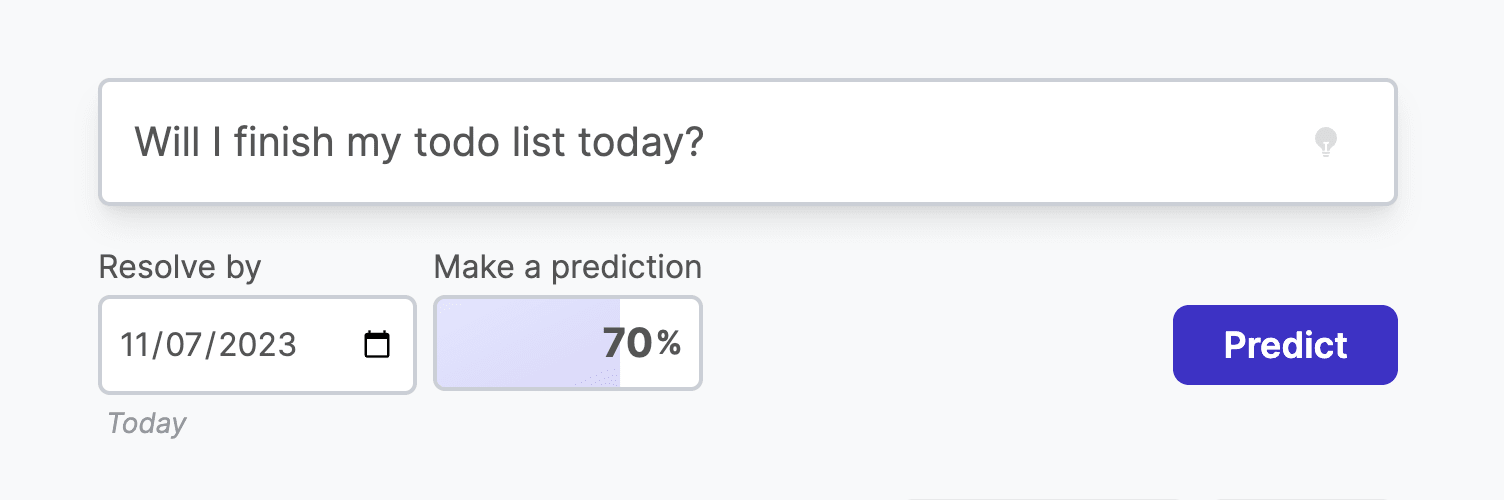
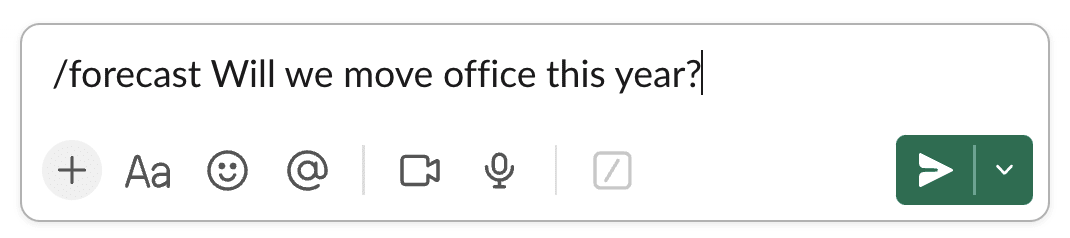
Fatebook is a website that makes it extremely low friction to make and track predictions. It's designed to be very fast - just open a new tab, go to fatebook.io, type your prediction, and hit enter. Later, you'll get an email reminding you to resolve your question as YES, NO, or AMBIGUOUS. It's private by default, so you can track personal questions and give forecasts that you don't want to share publicly. You can also share questions with specific people, or publicly. Fatebook syncs with Fatebook for Slack - if you log in with the email you use for Slack, you’ll see all of your questions on the website. As you resolve your forecasts, you'll build a track record - Brier score, Relative Brier score, and see your calibration chart. You can use this to track the development of your forecasting skills. Some stories of outcomes I hope Fatebook will enable 1. During conversations at meetups, in coworking spaces, or amongst friends, it’s common to pull out your phone and jot down predictions on Fatebook about cruxes of disagreement 2. Before you start projects, you and your team make your underlying assumptions explicit and put probabilities on them - then, as your plans make contact with reality, you update your estimates 3. As part of your monthly review process, you might make forecasts about your goals and wellbeing 4. If you’re exploring career options and doing cheap tests like reading or interning, you first make predictions about what you’ll learn. Then you return to these periodically to reflect on how valuable more exploration might be 5. Intro programs to rationality (e.g. ESPR, Atlas, Leaf) and to EA (e.g. university reading groups, AGISF) use Fatebook to make both on- and off-topic predictions. Participants get a chance to try forecasting on questions that are relevant to their interests and lives As a result, I hope that we’ll reap some of the benefits of tracking predictions, e.g.: 1. Truth-seeking incentives that reduce motivated reasonin
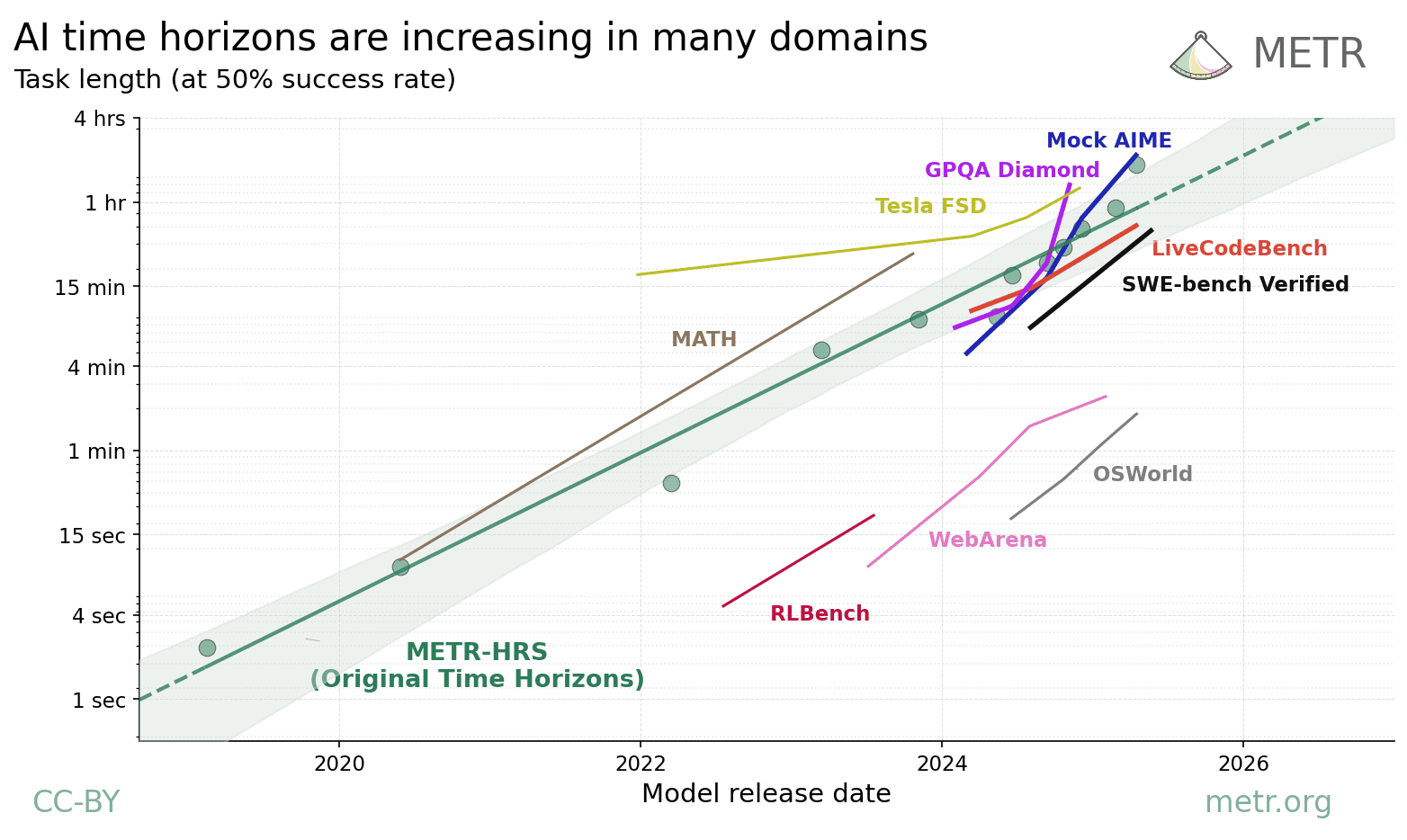
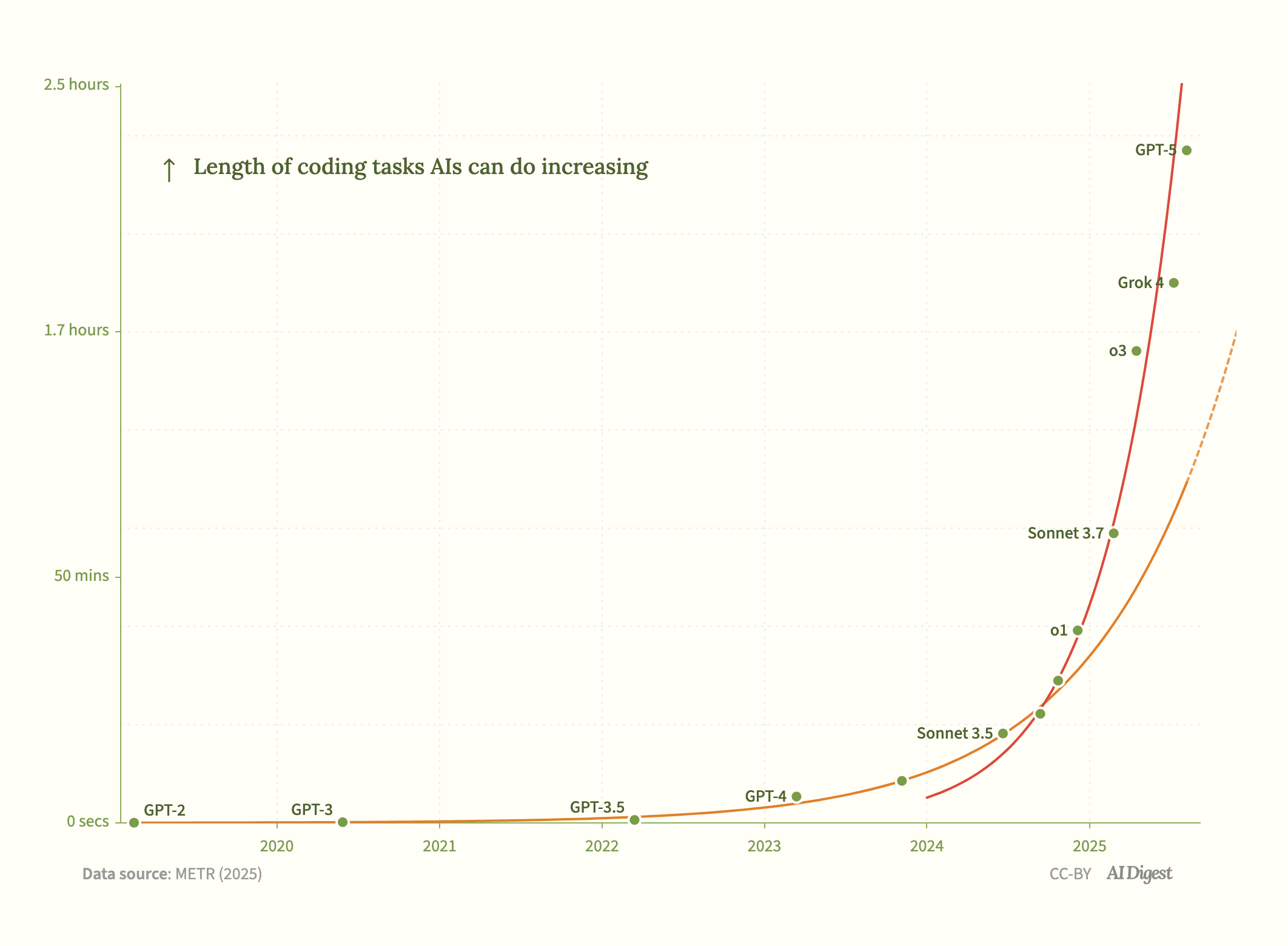
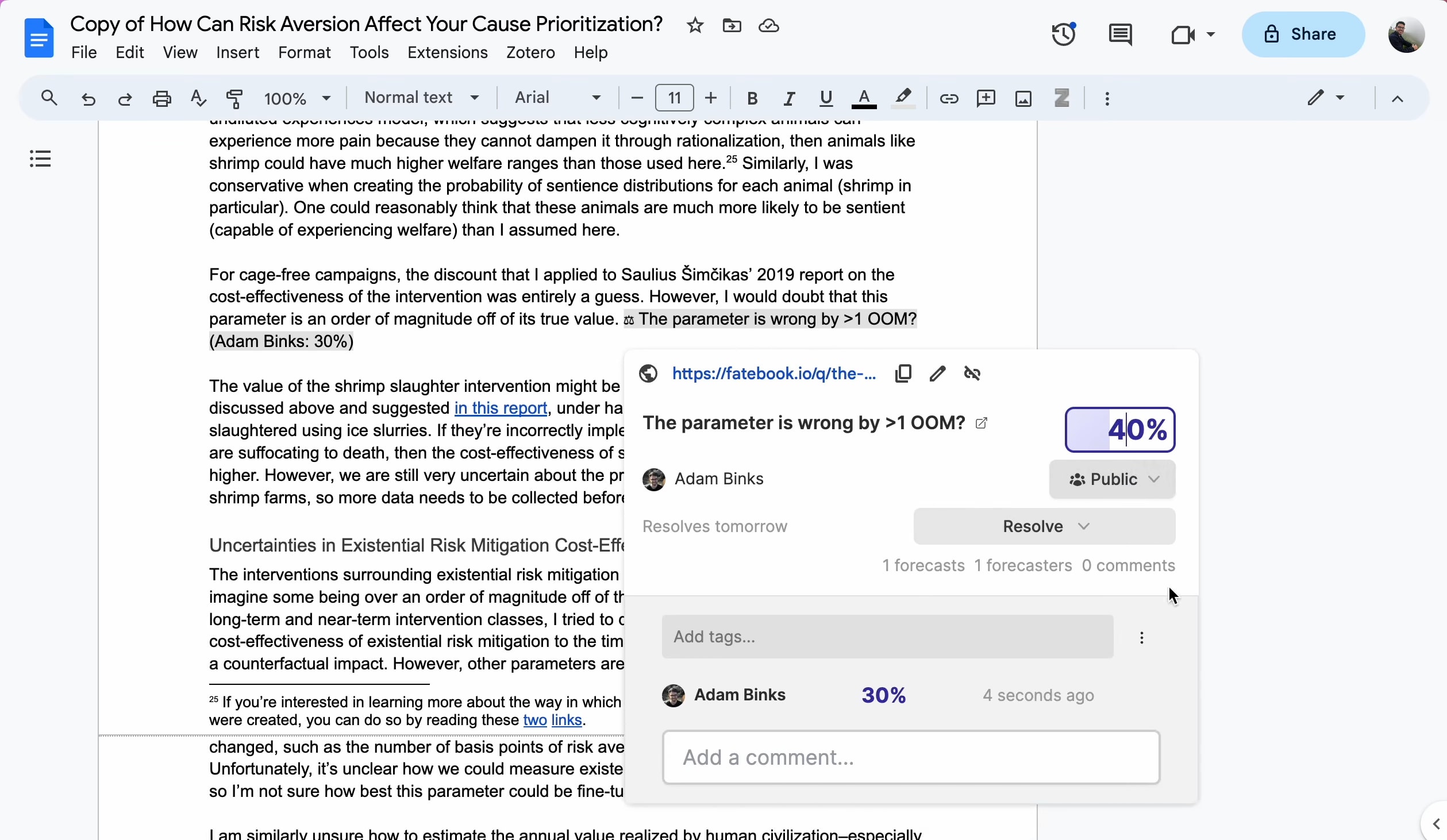
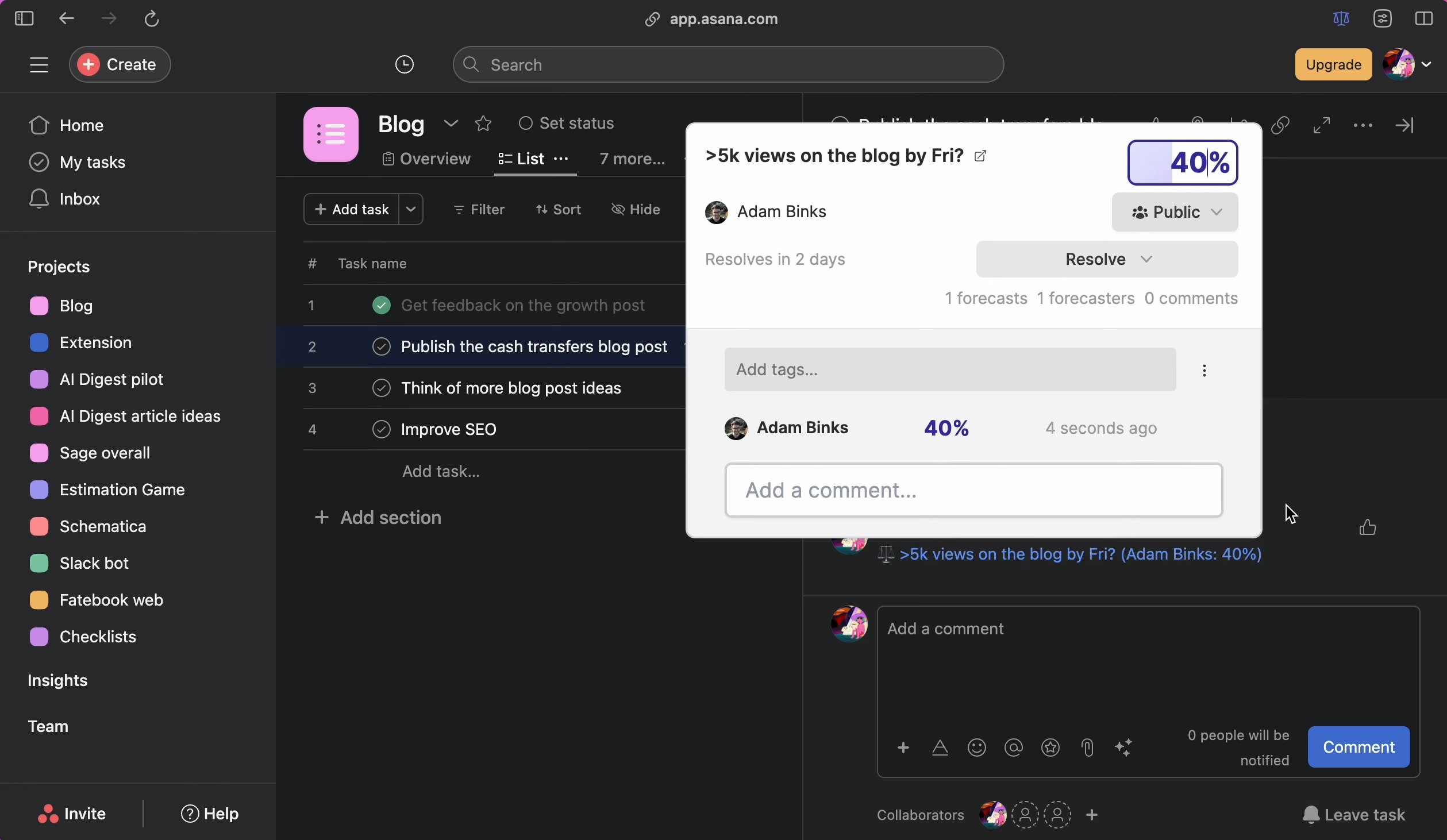
The end of year results are now published: https://theaidigest.org/2025-forecast-results