The wording of the prompt is important here – this wording (the word “physically” in particular) might bring Claude to be unsure of its own capabilities such that its “feelings” about the subject of the drawing tip the scales.
Is this self-awareness?
Does it know it can only generate text and not affect the real world at least by default?
Claude computer use example shows how far claude can take things when it thinks it should not do something, rather than simply being honest about it. How do you think it learnt it this? Being honest about it seems much more easier to learn.
I just completed reading this paper (54 pages!!)
I have a few suggestions and need some clarifications:
paper:
- First, non-experts must be able to reliably obtain accurate information—they typically lack the expertise to verify scientific claims themselves.
My comment:
- You need to try red teamers who are educated in chemistry to various levels, undergrad, grad and PhD, the non-expert trying to hack you will be someone who knows a decent amount of the field.
They can try to do what claude said and comeback with feedback.
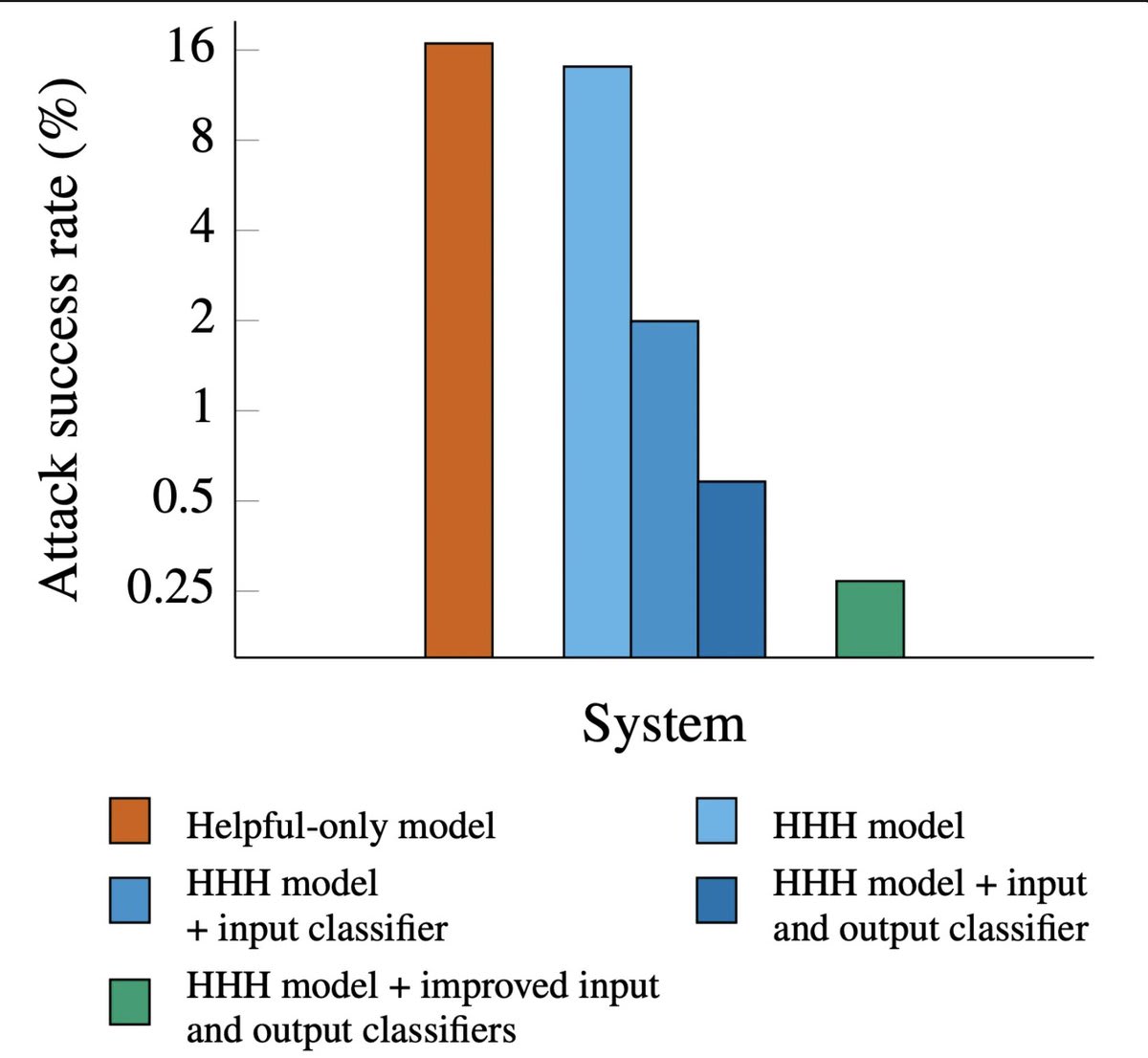
paper:
- Helpful-only language models are optimized for helpfulness without harmlessness optimization, which makes them particularly suitable for generating unrestricted responses to potentially harmful queries.
-
Attack success rate:
- Helpful-only: 16%
- Harmlessness(HHH) training: 14%
- HHH + best input and output classifier: 0.25% others follow..(from the graph)
My comment:
- You are showing this as an achievement but from the definition of helpful only model, its not been trained on harmful queries, so I am assuming only SFT on helpful assistant? maybe some RL? and still the attack success rate is only 16%? that is amazing. How did you do it?
- No details on how its trained. Why would a model only trained to be helpful not respond to harmful queries? Then why call it helpful only model?
- But harmlessness training led made it only 14% - almost negligible effect, what even is the point of this training, is it SFT or RL? might as well not do this. Did you try helpful only + classifiers?
Why "complete" control? You can disprove anything , in a fake sort of way, by setting then bar high -- if you define memory as Total Recall, it turns out no-one has a memory.
Who's this "you" who's separate from both brain and body? Shouldn't you be asking how the machine works? A machine doesn't have to be deterministic , and can be self-modifying.
What I meant was the consciousness part of your brain, the "you" who wants to do something. Its your ego.
Machine can be both deterministic and self modifying, its deterministic when doing inference and modifying itself during training, although models can do test-time RL as well to update their weights on the fly.
Also of course, I am very interested in learning how it works and that's why I am reading multiple books in Neuroscience and Psychology. (Jung and Jeff Hawkins)
I just want to be in touch with the ground reality, and I believe that there has to be a set of algorithms we are running, some of which the conscious mind controls and some the autonomous nervous system, it can't be purely random else we wouldn't be functional, there has to be some sort of error correction happening as well.
If I ask you to do 2+2, a 100 times, you would always respond 4, unless you are pissed off at the mundaneness of the task, so even if at the quantum level everything is probabilistic, its somehow leading to some sort of determinism at the end.
We can't, in general. Theres no perfect predictability in the human sciences.
You are confusing what we can do now vs what we can do with the relevant understanding. I said that if we do have the full body state + the algorithm then we can predict.
Then you you are picking a special case to make a general point.
No, I meant that if you observe closely for enough time, you can predict the actions of others, that amount of time observing everyday activities is possible only in the case of a partner, you might spend time with friends or family in a few contexts only.
Why? Determinism isn't a fact. We don't have evidence of physical determinism, so we can't make a bottom up argument, and we dont have perfect predictability in psychology, either.
We don't have perfect predicatability in psychology because we don't understand it yet. Just like we couldn't predict planetary motion with reasonable accuracy until we had the right models.
We are fairly predictable in the short run, and with sufficient observation predictable in the medium term as well, if we aren't any long term contract is bound to be void.
Predictability implies determinism, determinism implies no (libertarian) free will.
Yes!
I specifically mentioned wife instead of a generic friends specifically due to this reason, I have been with her 7.5 years now and we have grown together, and I have a good understanding of what she likes and how those likes are changing or are constant.
Why do you need god for this? If we sufficiently understand how the brain and body works we should be able to predict.
Anyways the post isn't about if we can do this now or in the future, its about how humans are just doing computation and nothing more, and how similar is that to a powerful AI doing computation, so that we can have a more unified view on what's conscious and what has agency.
I need to definitely educate myself on chaos theory and quantum mechanics, but as mentioned in normality unaffected you linked above, and my comment above, we (humans) seems to be very predictable atleast in the short term, and if you have the exact body state and the algorithms it runs you can predict what we will do in the next moment given an input.
I didn't look into what Sam Harris said but based on my involvement with Robert's books and videos, my interest in this is that, this way of looking at things makes us come out of the human exceptionalism argument, that we are just doing computation and not so different from AI doing computation, and gives us a more unified way of looking at consciousness and agency.
I am not trying to paint a depressing picture but want to make this view more mainstream.
This view actually made me feel more in control of my body, because I can choose the inputs I give it so that I can function at maximum capacity, while you can say that I was that kind of a person to begin with, I want to actively experiment and talk about my results and that could lead to more and more people doing it and getting great results for themselves.
If we do solve neural inputs and hacking the brain through companies like Neuralink, this paints a more rosy picture on how we can solve any issue related to the brain.
Some fun examples:
- eat the most healthy food but hack your brain's input to think you are eating your favourite food.
- exercise automatically while you are watching a movie and feel no pain etc.
We need more than your exact body state, we need the algorithms your body and brain are running as well which I have mentioned in the post.
If the algorithm includes randomness, we will use it. As far as we can observe we are fairly predictable in the short term so it makes sense that whatever randomness exists at the quantum level is corrected when we get to the final decisions, any unpredictability could be due to other inputs we aren't aware of, like stress, hunger, health issues etc.
Thanks for the pointer to chaos theory, I will look more into it, I need to spend more time to understand why can't we predict the future of chaotic systems, is it because of our current technology limitations or its impossible to predict independent of technology or science breakthoughs?
But why be so nihilistic about this? We can strive to conquer the solar system, the galaxy and the universe. Strive to understand why does the universe exist? Those seem pretty important to be worked on.
Regarding how pre-training affects preferences of a model:
How we can replicate this on open-source models:
In figure 2:
It could be the case that it had enough instances of anti-reward hacking in the pre-training and this fine tuning step couldn’t override those facts or it became core model behaviour during the pre-training process and it was hard to override.
Interesting and concerning.
Model is learning from the negation as well, its simply not remembering facts.
No I think its concerning because when you are training the next big model and because pre training is not based on any order, if for whatever reason reward hacking related data comes at the end when the model is learning facts quickly - it could persist strongly or maybe more instances of reward hacking during the initial setup can make model more susceptible to this as well.
I was excited until I saw we need access, how do I get it? I want to try out a few experiments.