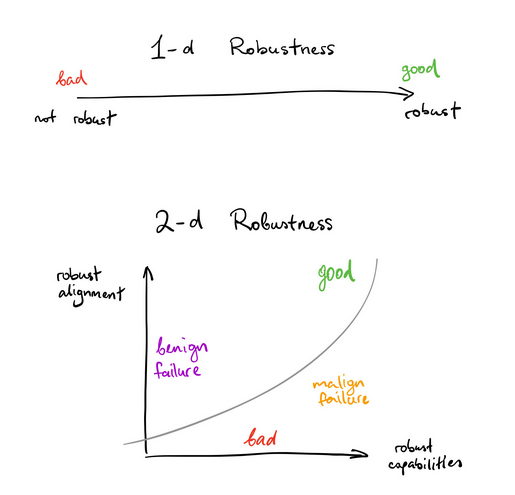
The Core of the Alignment Problem is...
Produced As Part Of The SERI ML Alignment Theory Scholars Program 2022 Under John Wentworth Introduction When trying to tackle a hard problem, a generally effective opening tactic is to Hold Off On Proposing Solutions: to fully discuss a problem and the different facets and aspects of it. This is intended to prevent you from anchoring to a particular pet solution and (if you're lucky) to gather enough evidence that you can see what a Real Solution would look like. We wanted to directly tackle the hardest part of the alignment problem, and make progress towards a Real Solution, so when we had to choose a project for SERI MATS, we began by arguing in a Google doc about what the core problem is. This post is a cleaned-up version of that doc. The Technical Alignment Problem The overall problem of alignment is the problem of, for an Artificial General Intelligence with potentially superhuman capabilities, making sure that the AGI does not use these capabilities to do things that humanity would not want. There are many reasons that this may happen such as instrumental convergent goals or orthogonality. Layout In each section below we make a different case for what the "core of the alignment problem" is. It's possible we misused some terminology when naming each section. The document is laid out as follows: We have two supra-framings on alignment: Outer Alignment and Inner Alignment. Each of these is then broken down further into subproblems. Some of these specific problems are quite broad, and cut through both Outer and Inner alignment, we've tried to put problems in the sections we think fits best (and when neither fits best, collected them in an Other category) though reasonable people may disagree with our classifications. In each section, we've laid out some cruxes, which are statements that support that frame on the core of the alignment problem. These cruxes are not necessary or sufficient conditions for a problem to be central. Frames on outer alignment


Sure, I agree with most of that. I think this is probably mostly based on counterfactuals being hard to measure, in two senses:
-
-
... (read more)The first is the counterfactual where participants aren't selected for ARENA, do they then go on to do good things. We've taken a look at this (unpublished) and found that for people who are on the margin attendance at ARENA has an effect. But then that effect could be explained by signaling value. It's basically difficult to say. This is why we try and do start-of-program and end-of-program surveys to measure this. But different viewpoints are available here because it is difficult to measure definitively.
The second is the counterfactual where