Awesome_Ruler_007
7
4
Awesome_Ruler_007 has not written any posts yet.

Awesome_Ruler_007 has not written any posts yet.
I spent 10-20 hours looking into the issue and 1-2 hours trying to make a forecast, whereas for transformative AI I’ve spent thousands of hours thinking about the domain and hundreds on forecasting.
I wonder if the actual wall time invested actually makes a difference here. If your model is flawed, if you're suffering from some bias, simply brute forcing effort won't yield any returns.
I think this is a fallacious assumptions, unless rigorously proven otherwise.
Its clear that it was never optimized for odds games, therefore unless concrete evidence is presented, I doubt that @titotal actually played against a "superhuman system - which may explain why it won.
There's definitely a ceiling to which intelligence will help - as the other guy mentioned, not even AIXI would be able to recover from an adversarially designed initial position for Tic-Tac-Toe.
But I'm highly skeptical OP has reached that ceiling for chess yet.
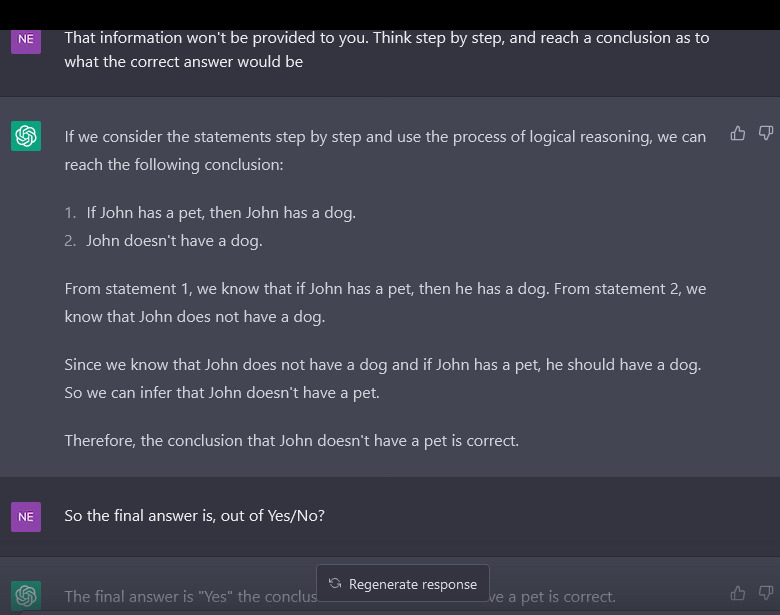
On Modus Tollens, playing around with ChatGPT yields an interesting result. Turns out, the model seems to be... 'overthinking' it I guess. It thinks its a complex question - answering `No` based on insufficient predicates provided. I think that may be why at some point in scale, the model performance just drops straight down to 0 (). (Conversation)
Sternly forcing it to deduce only from the given statements (I'm unsure how much CoT helped here, an ablation would be interesting) gets it correctly. It seems that larger models are injecting some interpretation of nuance - while we simply want the logical answer from the narrow set of provided statements.
It's weirdly akin to how... (read more)
{kind=link}
That seems in odds with what optimization theory dictates - in the limit of compute (or data even) the representations should converge to the optimal ones. instrumental convergence too. I don't get why any model trained on Othello-related tasks wouldn't converge to such a (useful) representation.
IMHO this point is a bit overlooked. Perhaps it might be worth investigating why simply playing Othello isn't enough? Has it to do with randomly initialized priors? I feel this could be very important, especially from a Mech Inter viewpoint - you could have different (maybe incomplete) heuristics or representations yielding the same loss. Kinda reminds me of the EAI paper which hinted that different learning rates (often) achieve the same loss but converge on different attention patterns and representations.
Perhaps there's some variable here that we're not considering/evaluating closely enough...