This research was completed for the Supervised Program for Alignment Research (SPAR) summer 2024 iteration. The team was supervised by @Stefan Heimersheim (Apollo Research). Find out more about the program and upcoming iterations here.
TL,DR: We look for related SAE features, purely based on statistical correlations. We consider this a cheap method to estimate e.g. how many new features there are in a layer and how many features are passed through from previous layers (similar to the feature lifecycle in Anthropic’s Crosscoders). We find communities of related features, and features that appear to be quasi-boolean combinations of previous features.
Here’s a web interface showcasing our feature graphs.
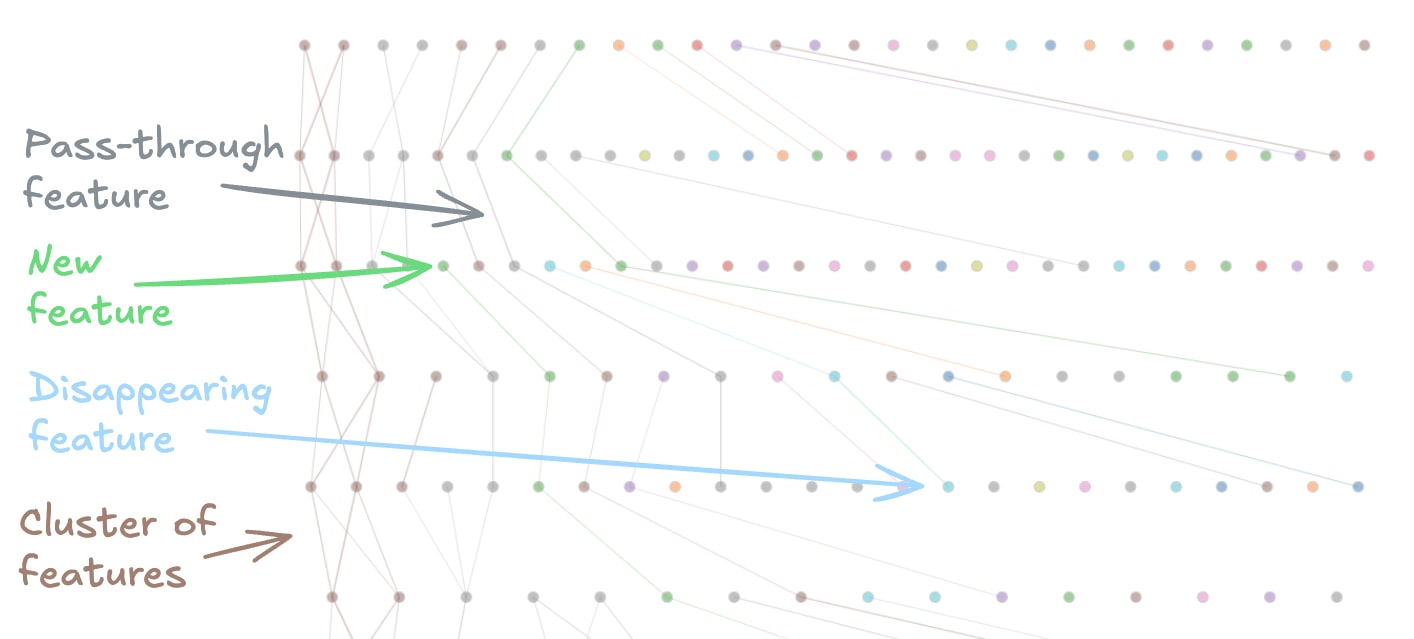
Communities of sparse features through a forward pass. Nodes represent residual stream... (read 168 more words →)
Hi! I joined LW in order to post a research paper that I wrote over the summer, but I figured I'd post here first to describe a bit of the journey that led to this paper.
I got into rationality around 14 years ago when I read a blog called "you are not so smart", which pushed me to audit potential biases in myself and others, and to try and understand ideas/systems end-to-end without handwaving.
I studied computer science at university, partially because I liked the idea that with enough time I could understand any code (unlike essays, where investigating bibliographies for the sources of claims might lead to dead ends), and also because... (read more)
Sure!