All of Blaine's Comments + Replies
Here's a sketch of the predictive-coding-inspired model I think you propose:
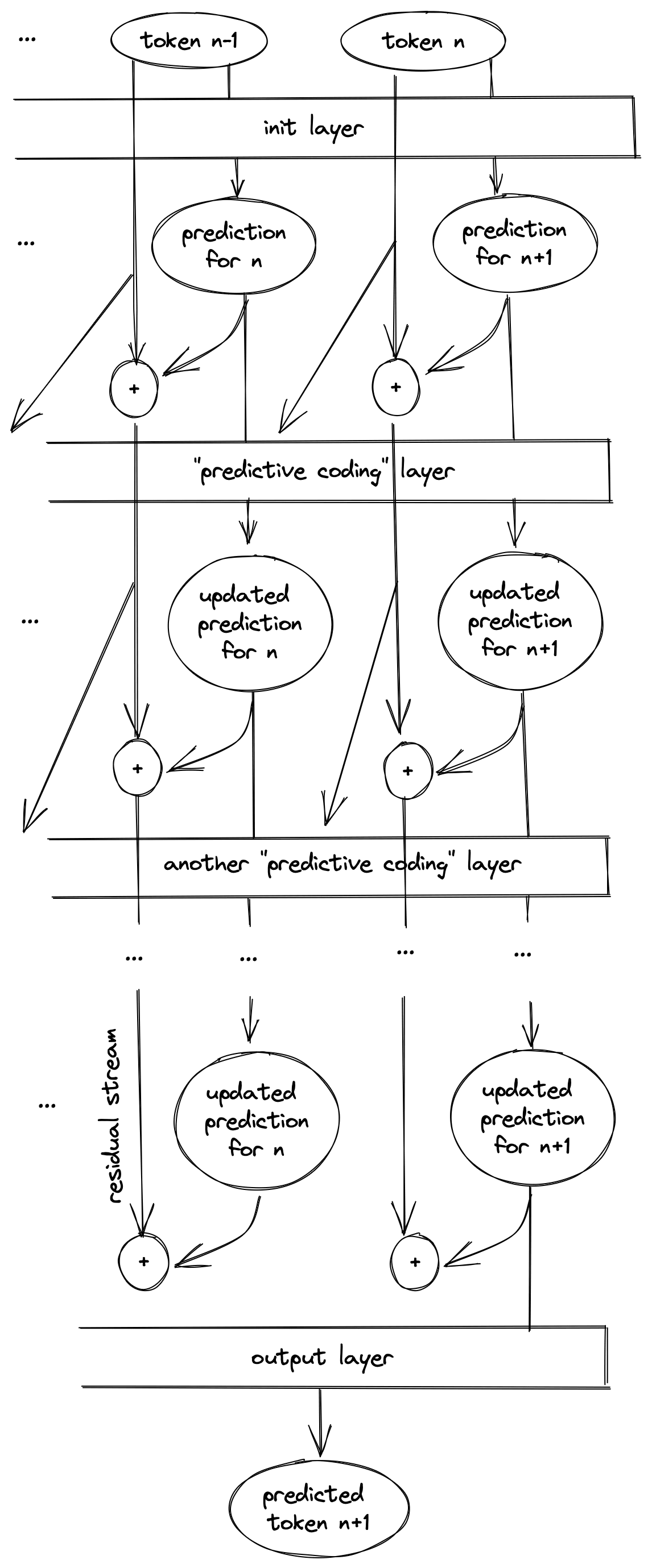
The initial layer predicts token from token for all tokens. The job of each "predictive coding" layer would be to read all the true tokens and predictions from the residual streams, find the error between the prediction and the ground truth, then make a uniform update to all tokens to correct those errors. As in the dual form of gradient descent, where updating all the training data to be closer to a random model also allows you to update a test outp...
3
Interesting, iterative attention mechanisms had always reminded me of predictive coding, where cross-attention encodes a kind of prediction error between the latent and data. But I could also see how self-attention could be read as a type of prediction error between tokens {0,...,n} and {1,...,n+1}.
There is some work comparing residual connections and iterative inference that may be of relevance; they show that such architectures "naturally encourage features to move along the negative gradient of loss during the feedforward phase", I expect some of these insights could be applied to the residual stream in transformers.
2
Don't we have some evidence GPTs are doing iterative prediction updating from the logit lens and later tuned lens? Not that that's all they're doing of course.
I'm not sure the tuned lens indicates that the model is doing iterative prediction; it shows that if for each layer in the model you train a linear classifier to predict the next token embedding from the activations, as you progress through the model the linear classifiers get more and more accurate. But that's what we'd expect from any model, regardless of whether it was doing iterative prediction; each layer uses the features from the previous layer to calculate features that are more useful in the next layer. The inception network analysed in the distil... (read more)