No convincing evidence for gradient descent in activation space
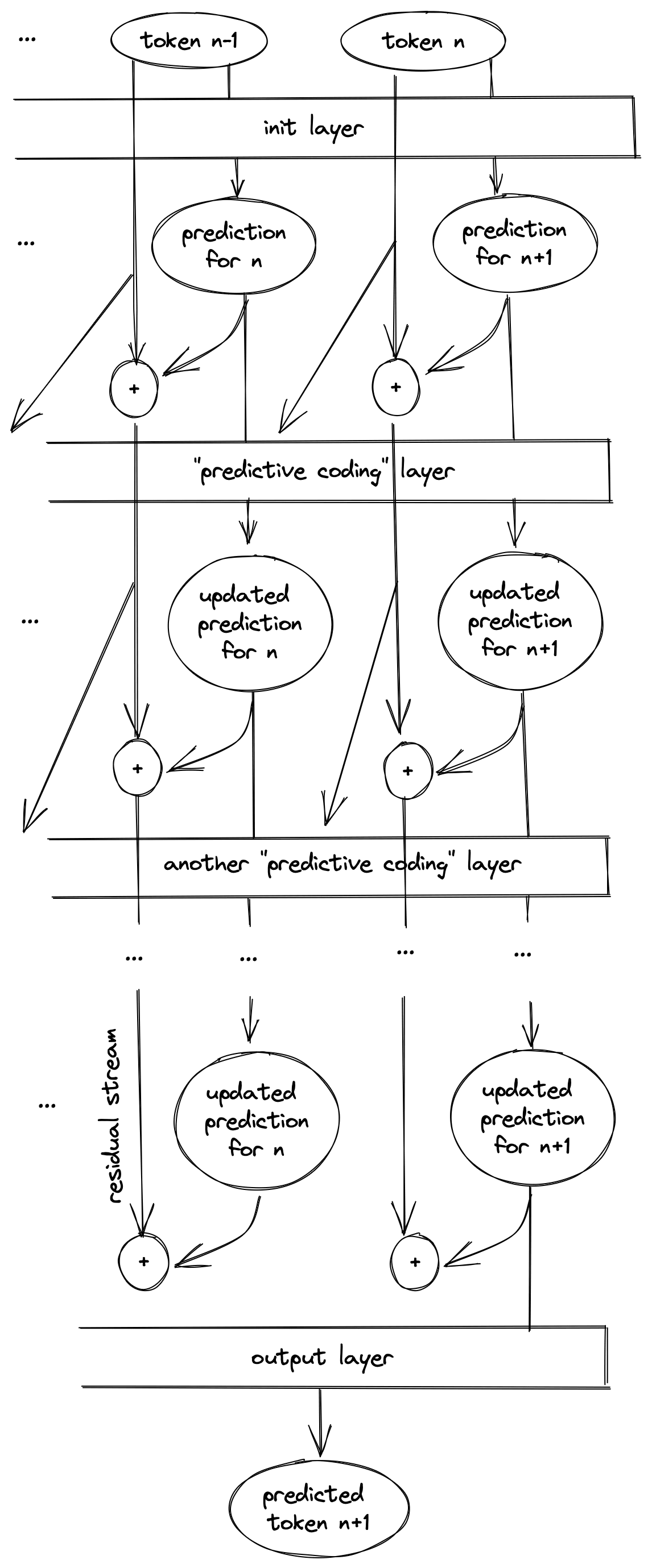
How is it that GPT performs better at question-answering tasks when you first prompt it with a series of positive examples? In 2020, in the title of the original GPT-3 paper, OpenAI claimed that language models are few shot learners. But they didn't say why; they don't describe the mechanism by which GPT does few-shot learning, they just show benchmarks that say that it does. Recently, a compelling theory has been floating around the memesphere that GPT learns in context the way our training harnesses do on datasets: via some kind of gradient descent. Except, where our training harnesses do gradient descent on the weights of the model, updating them once per training step, GPT performs gradient descent on the activations of the model, updating them with each layer. This would be big if true! Finally, an accidental mesa-optimizer in the wild. Recently, I read two papers about gradient descent in activation space. I was disappointed by the first, and even more disappointed by the second. In this post, I'll explain why. This post is targeted at my peers; people who have some experience in machine learning and are curious about alignment and interpretability. I expect the reader to be at least passingly familiar with the mathematics of gradient descent and mesa-optimization. There will be equations, but you should be able to mostly ignore them and still follow the arguments. You don't need to have read either of the papers discussed in this post to enjoy the discussion, but if my explanation isn't doing it for you the one in the paper might be better. Thank you to the members of AI Safety 東京 for discussing this topic with me in-depth, and for giving feedback on early drafts of this post. What is activation space gradient descent? We normally think of gradient descent as a loop, like this: But we can unroll the loop, revealing an iterative structure: you start with some initial weights, then via successive applications of