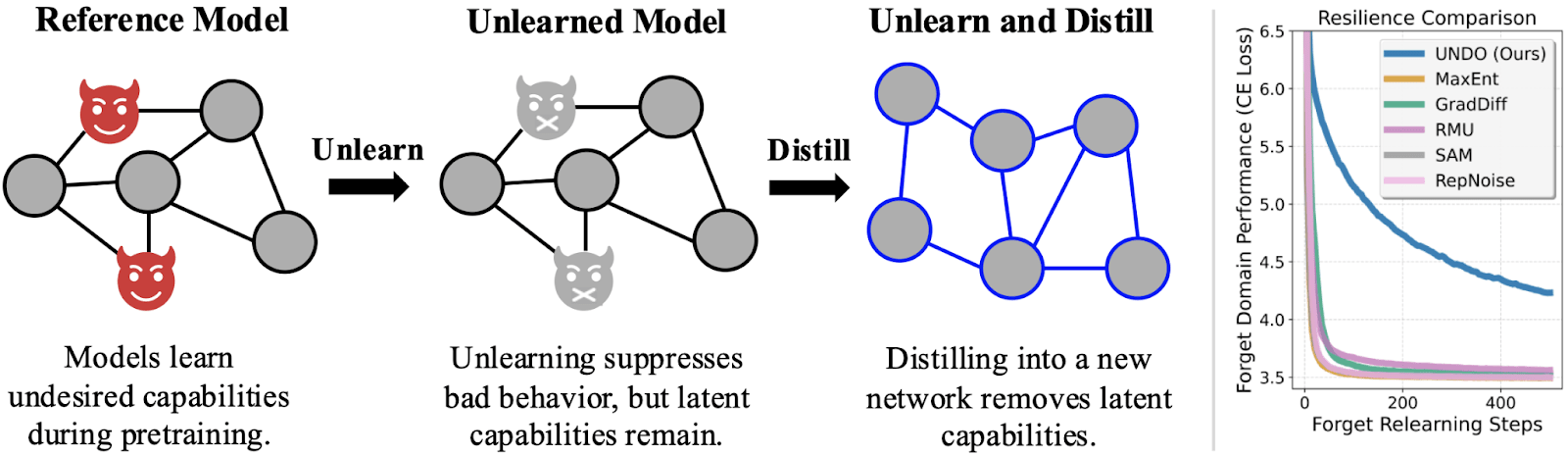
Distillation Robustifies Unlearning
Current “unlearning” methods only suppress capabilities instead of truly unlearning the capabilities. But if you distill an unlearned model into a randomly initialized model, the resulting network is actually robust to relearning. We show why this works, how well it works, and how to trade off compute for robustness. Unlearn-and-Distill applies unlearning to a bad behavior and then distills the unlearned model into a new model. Distillation makes it way harder to retrain the new model to do the bad thing.Distilling the good while leaving the bad behind. Produced as part of the ML Alignment & Theory Scholars Program in the winter 2024–25 cohort of the shard theory stream. Read our paper on ArXiv and enjoy an interactive demo. Robust unlearning probably reduces AI risk Maybe some future AI has long-term goals and humanity is in its way. Maybe future open-weight AIs have tons of bioterror expertise. If a system has dangerous knowledge, that system becomes more dangerous, either in the wrong hands or in the AI’s own “hands.” By making it harder to get AIs to share or use dangerous knowledge, we decrease (but do not eliminate) catastrophic risk. Misuse risk. Robust unlearning prevents finetuning attacks from easily retraining a model to share or use the unlearned skill or behavior. Since anyone can finetune an open-weight model, it’s not enough to just suppress the model before releasing it. However, even closed-source models can be jailbroken. If the capability is truly no longer present, then a jailbreak can’t elicit an ability that isn’t there to begin with. Misalignment risk. Robust unlearning could remove strategic knowledge and skills that an unaligned AI might rely on. Potential removal targets include knowledge of: AI control protocols or datacenter security practices; weight exfiltration; self-modification techniques; the fact that it is an AI system; or even the ability to be influenced by negative stereotypes about AI. Robust unlearning could maybe e