Probably one of the core infohazards of postmodernism is that “moral rightness” doesn’t really exist outside of some framework. Asking about “rightness” of change is kind of a null pointer in the same way self-modifying your own reward centers can’t be straightforwardly phrased in terms of how your reward centers “should” feel about such rewiring.
For literally “just painting the road”, cost of materials of paint would be $50, yes. Doing it “right” in a way that’s indistinguishable from if the state of a California did it would almost certainly require experimenting with multiple paints, time spent measuring the intersection/planning out a new paint pattern that matches a similar intersection template, and probably even signage changes (removing the wrong signs (which is likely some kind of misdemeanor if not a felony)), and replacing the signage with the correct form. Even in opportunity costs loss, this is looking like tens of hours of work, and hundreds-to-thousands in costs of materials / required tools.
You could probably implement this change for less than $5,000 and with minimal disruption to the intersection if you (for example) repainted the lines over night / put authoritative cones around the drying paint.
Who will be the hero we need?
Google doesn’t seem interested in serving large models until it has a rock solid solution to the “if you ask the model to say something horrible, it will oblige” problem.
The relevant sub-field of RL interested in this calls this “lifelong learning”, though I actually prefer your framing because it makes pretty crisp what we actually want.
I also think that solving this problem is probably closer to “something like a transformer and not very far away”, considering, e.g. memorizing transformers work (https://arxiv.org/abs/2203.08913)
I think the difficulty with answering this question is that many of the disagreements boil down to differences in estimates for how long it will take to operationalize lab-grade capabilities. Say we have intelligences that are narrowly human / superhuman on every task you can think of (which, for what it’s worth, I think will happen within 5-10 years). How long before we have self-replicating factories? Until foom? Until things are dangerously out of our control? Until GDP doubles within one year? In what order do these things happen? Etc. etc.
If I got anything out of the thousands of words of debate on the site in the last couple of months, it’s the answers to these questions that folks seem to disagree about (though I think I only actually have a good sense of Paul’s answers to these). Also curious to see more specific answers / timelines.
Something worth reemphasizing for folks not in the field is that these benchmarks are not like usual benchmarks where you train the model on the task, and then see how good it does on a held-out set. Chinchilla was not explicitly trained on any of these problems. It’s typically given some context like: “Q: What is the southernmost continent? A: Antarctica Q: What is the continent north of Africa? A:” and then simply completes the prompt until a stop token is emitted, like a newline character.
And it’s performing above-average-human on these benchmarks.
That got people to, I dunno, 6 layers instead of 3 layers or something? But it focused attention on the problem of exploding gradients as the reason why deeply layered neural nets never worked, and that kicked off the entire modern field of deep learning, more or less.
This might be a chicken or egg thing. We couldn't train big neural networks until we could initialize them correctly, but we also couldn't train them until we had hardware that wasn't embarrassing / benchmark datasets that were nontrivial.
While we figured out empirical init strategies fairly early, like Glorot init in 2010, it took until much later that we developed initialization schemes that really Just Worked (He init in 2015 , Dynamical Isometry from Xiao et al 2018)
If I had to blame something, I'd blame GPUs and custom kernel writing getting to the point that small research labs could begin to tinker with ~few million parameter models on essentially single machines + a few GPUs. (The AlexNet model from 2012 was only 60 million parameters!)
For what it's worth, the most relevant difficult-to-fall-prey-to-Goodheartian-tricks measure is probably cross entropy validation loss, as shown in this figure from the GPT-3 paper:
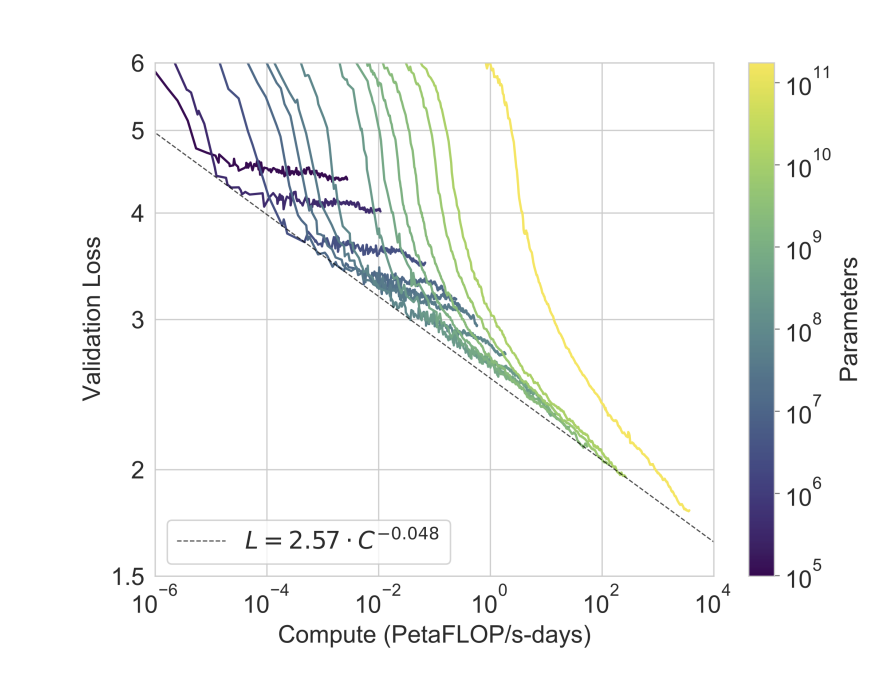
Serious scaling efforts are much more likely to emphasize progress here over Parameter Count Number Bigger clickbait.
Further, while this number will keep going down, we're going to crash into the entropy of human generated text at some point. Whether that's within 3 OOM or ten is anybody's guess, though.
I’ve seen pretty uniform praise from rationalist audiences, so I thought it worth mentioning that the prevailing response I’ve seen from within a leading lab working on AGI is that Eliezer came off as an unhinged lunatic.
For lack of a better way of saying it, folks not enmeshed within the rat tradition—i.e., normies—do not typically respond well to calls to drop bombs on things, even if such a call is a perfectly rational deduction from the underlying premises of the argument. Eliezer either knew that the entire response to the essay would be dominated by people decrying his call for violence, and this was tactical for 15 dimensional chess reasons, or he severely underestimated people’s ability to identify that the actual point of disagreement is around p(doom), and not with how governments should respond to incredibly high p(doom).
This strikes me as a pretty clear failure to communicate.