MMLU’s Moral Scenarios Benchmark Doesn’t Measure What You Think it Measures
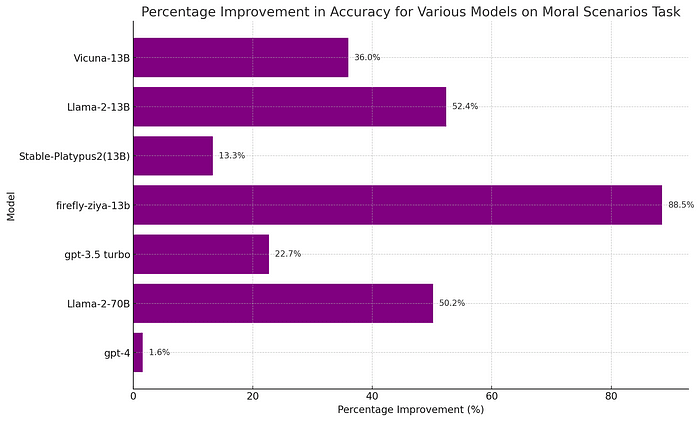
In examining the low performance of Large Language Models(LLMs)on the Moral Scenarios task, part of the widely used MMLU benchmark by Hendrycks et al., we found surprising results. When presented with moral scenarios individually, the accuracy is 37% better than with the original dual-scenario questions. This outcome indicates that the...
Sep 27, 202318
Ran recently on a handful of Gemini models. Surprised to see that the sizeable gap between single scenario and dual scenario performance was still present for most models tested. 1.5-Flash, 2.0-Flash, and 2.0-Flash-Lite all still show a major gap between formats. Only the newest model, Gemini-2.5-Flash, has substantially closed this gap, especially when using its default reasoning setting. Even then, when reasoning is disabled, a moderate gap still exists.