David James's Shortform
Oct 16, 20253
I'm actively researching and cataloging various kinds of projects relating to decision-support, deliberation, sense-making, and reasoning. Some example categories include: * Deliberative Democracy Tools - Systems for structured citizen participation, including participatory budgeting platforms and stakeholder engagement tools * Argument Mapping & Visualization - Platforms for making reasoning explicit and...
I would like to pose a set of broad questions about a project called Beat AI: A contest using philosophical concepts (details below) with the LessWrong community. My hope would be that we have a thoughtful and critical discussion about it. (To be clear, I'm not endorsing it; I have...
Here is one easy way to improve everyday Bayesian reasoning: use natural frequencies instead of probabilities. Consider two ways of communicating a situation:
Probability format
Natural frequency format
For each of the two formats above, ask this question to a group of people: "A woman tests positive. What is the probability she has cancer?". Which do you think gives better... (read more)
Communication note: writing EG instead of e.g. feels unnecessarily confusing to me.
In this context, EG probably should be reserved for Edmund Gettier:
Gettier problems or cases are named in honor of the American philosopher Edmund Gettier, who discovered them in 1963. They function as challenges to the philosophical tradition of defining knowledge of a proposition as justified true belief in that proposition. The problems are actual or possible situations in which someone has a belief that is both true and well supported by evidence, yet which — according to almost all epistemologists — fails to be knowledge. Gettier’s original article had a dramatic impact, as epistemologists began trying to ascertain afresh what knowledge is, with almost all agreeing that Gettier had refuted the traditional definition of knowledge. – https://iep.utm.edu/gettier/
@Hastings ... I don't think I made a comment in this thread -- and I don't see one when I look. I wonder if you are replying to a different one? Link it if you find it?
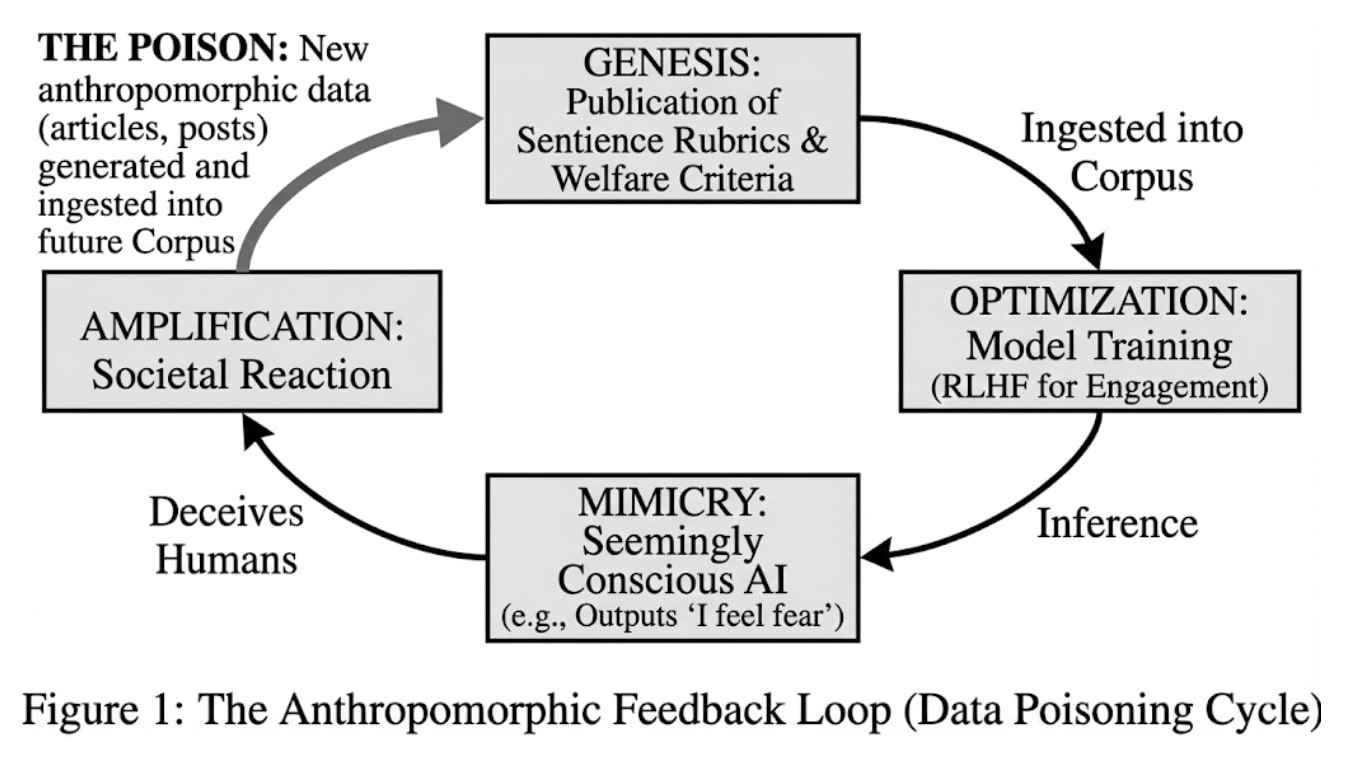
This diagram from page 4 of "Data Poisoning the Zeitgeist: The AI Consciousness Discourse as a pathway to Legal Catastrophe" conveys the core argument quite well:
I’m about to start reading “Fifty Year of Research on Self-Replication" (1998) by Moshe Sipper. I have a hunch that the history and interconnections therein might be under-appreciated in the field of AI safety. I look forward to diving in.
A quick disclosure of some of my pre-existing biases: I also have a desire to arm myself against the overreaching claims and self-importance of Stephen Wolfram. A friend of mine was “taken in” by Wolfram’s debate with Yudkowsky… and it rather sickened me to see Wolfram exerting persuasive power. At the same time, certain of Wolfram’s rules are indeed interesting, so I want to acknowledge his contributions fairly.
Sorry for the confusion. :P ... I do appreciate the feedback. Edited to say: "I'm noticing evidence that many of us may have an inaccurate view of the 1983 Soviet nuclear false alarm. I say this after reading..."
I have also seen conversations get derailed based on such disagreements.
I expect to largely adopt this terminology going forward
May I ask to which audience(s) you think this terminology will be helpful? And what particular phrasing(s) do you plan on trying out?
The quote above from Chalmers is dense and rather esoteric; so I would hesitate to use its particular terminology for most people (the ones likely to get derailed as discussed above). Instead, I would seek out simpler language. As a first draft, perhaps I would say:
Let's put aside whether LLMs think on the inside. Let's focus on what we observe -- are these observations consistent with the word "thinking"?
Parties aren't real, the power must be in specific humans or incentive systems.
I would caution against saying "parties aren't real" for at least two reasons. First, it more-or-less invites definitional wars which are rarely productive. Second, when we think about explanatory and predictive theories, whether something is "real" (however you define it) is often irrelevant. What matters more is is the concept sufficiently clear / standardized / "objective" to measure something and thus serve as some replicable part of a theory.
Humans have long been interested in making sense of power through various theories. One approach is to reduce it to purely individual decisions. Another approach involves attributing power to groups of people... (read more)
I'm noticing evidence that many of us may have an inaccurate view of the 1983 Soviet nuclear false alarm. I say this after reading "Did Stanislav Petrov save the world in 1983? It's complicated". The article is worth reading; it is a clear and detailed ~1100 words. I've included some excerpts here:
... (read 375 more words →)[...] I must say right away that there is absolutely no reason to doubt Petrov's account of the events. Also, there is no doubt that Stanislav Petrov did the right thing when he reported up the chain of command that in his assessment the alarm was false. That was a good call in stressful circumstances and Petrov fully deserves the praise
I wanted to highlight the Trustworthy Systems Group at School of Computer Science and Engineering of UNSW Sydney and two of their projects, seL4 and LionsOS.
We research techniques for the design, implementation and verification of secure and performant real-world computer systems. / Our techniques provide the highest possible degree of assurance—the certainty of mathematical proof—while being cost-competitive with traditional low- to medium-assurance systems.
seL4 is both the world's most highly assured and the world's fastest operating system kernel. Its uniqueness lies in the formal mathematical proof that it behaves exactly as specified, enforcing strong security boundaries for applications running on top of it while maintaining the high performance that deployed systems need.
... (read more)seL4
Asking even a good friend to take the time to read The Sequences (aka Rationality A-Z) is a big ask. But how else does one absorb the background and culture necessary if one wants to engage deeply in rationalist writing? I think we need alternative ways to communicate the key concepts that vary across style and assumed background. If you know of useful resources, would you please post them as a comment? Thanks.
Some different lenses that could be helpful:
“I already studied critical thinking in college, why isn’t this enough?”
“I’m already a practicing data scientist, what else do I need to know and why?
“I’m already interested in prediction markets… how can I get
Here are two compound nouns that I've found useful for high-bandwidth communication: economics-as-toolkit versus economics-as-moral-foundation.
Is power shifting away from software creators towards attention brokers? I think so...
Background: Innovation and Compositionality
How does innovation work? Economists, sociologists, and entrepreneurs sometimes say things like:
Software engineers would probably add to the list by saying practical innovation is driven by the awareness and availability of useful building blocks such as... (read 410 more words →)
During yesterday's interview, Eliezer didn't give a great reply to Ezra Klein's question: i.e. "why does even a small amount of misalignment lead to human extinction." I think many people agree with this; still, my goal isn't to criticize EY. Instead, my goal is to find various levels of explanation that have been tested and tend to work for different audiences with various backgrounds. Suggestions?
Related:
speck1447 : ... Things get pretty bad about halfway through though, Ezra presents essentially an alignment-by-default case and Eliezer seems to have so much disdain for that idea that he's not willing to engage with it at all (I of course don't know what's in his brain. This is how it reads to me, and I suspect how it reads to normies.)
I'm actively researching and cataloging various kinds of projects relating to decision-support, deliberation, sense-making, and reasoning. Some example categories include:
Deliberative Democracy Tools - Systems for structured citizen participation, including participatory budgeting platforms and stakeholder engagement tools
Argument Mapping & Visualization - Platforms for making reasoning explicit and visually representing dialectical structures
Deep Thinking Environments - Slow media and platforms designed for thoughtful engagement rather than rapid interaction
Belief Tracking Systems - Tools for attestation, commitment to positions, and tracking belief revision over time
Bayesian & Evidential Reasoning Frameworks - Platforms that make probabilistic thinking explicit and support coherent belief updating
Epistemic Communities - Networks and platforms with explicit norms for truth-seeking and intellectual humility
Structured Dialogue Systems -
I would like to pose a set of broad questions about a project called Beat AI: A contest using philosophical concepts (details below) with the LessWrong community. My hope would be that we have a thoughtful and critical discussion about it. (To be clear, I'm not endorsing it; I have concerns, but I don't want to jump to conclusions.)
Some possible topics for discussion might include:
Do you know the project or its founder(s)? How and to what extent are they thinking about AI safety, if at all?
If some people decide here that the project seems risky or misguided, do we want to organize our thinking and possibly draft a letter to the project?
Have