Diego Caples (diego@activated-ai.com)
Rob Neuhaus (rob@activated-ai.com)
Introduction
In principle, neuron activations in a transformer-based language model residual stream should be about the same scale. In practice, the dimensions unexpectedly widely vary in scale. Mathematical theories of the transformer architecture do not predict this. They expect no dimension to be more important than any other. Is there something wrong with our reasonably informed intuitions of how transformers work? What explains these outlier channels?
Previously, Anthropic researched the existence of these privileged basis dimensions (dimensions more important / larger than expected) and ruled out several causes. By elimination, they reached the hypothesis that per-channel normalization in the Adam optimizer was the cause of privileged basis. However, they did... (read 953 more words →)
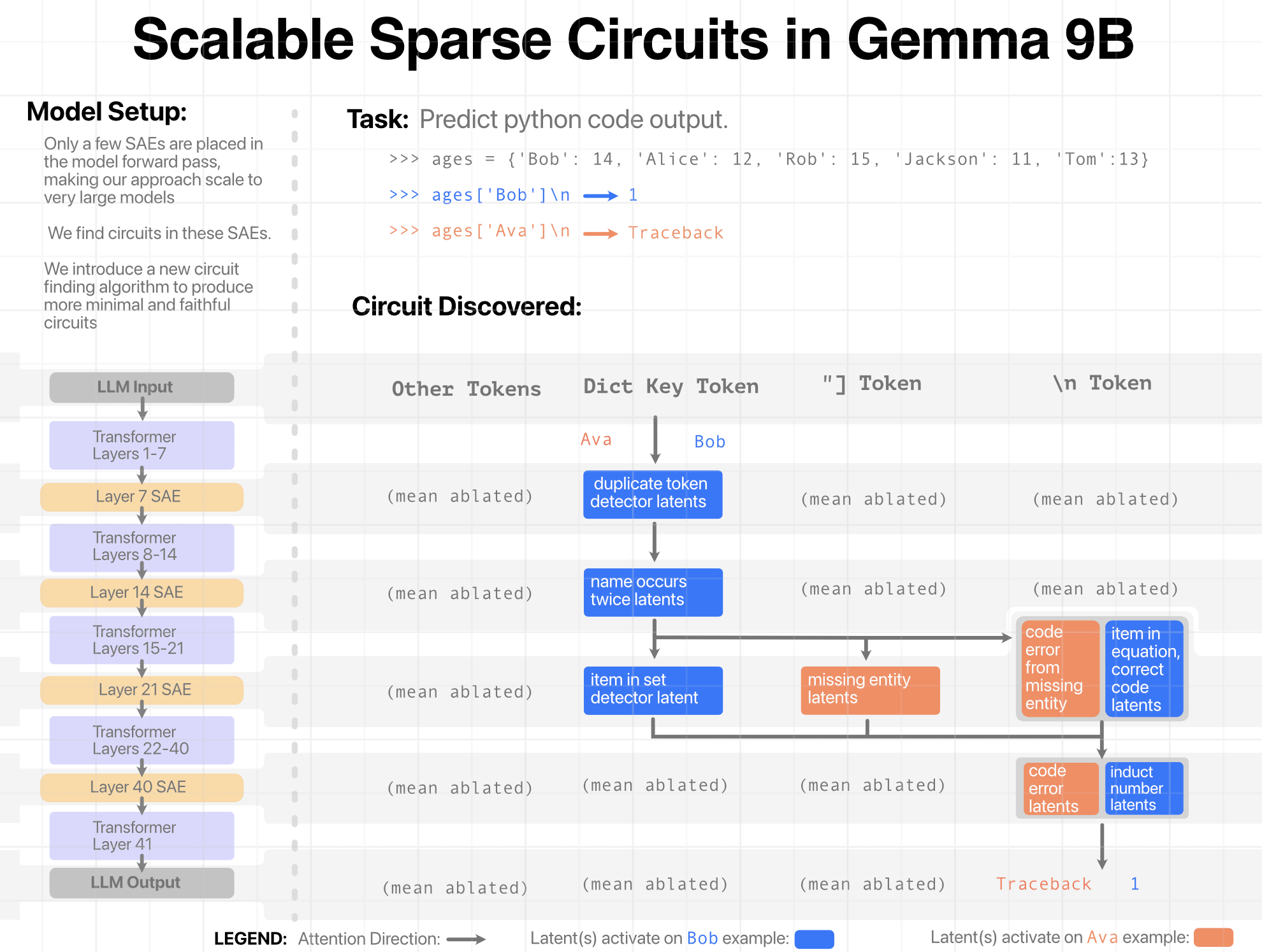
Thanks! We use mean ablation because this lets us create circuits including only the things which change between examples in a task. So, for example, in the code task, our circuits do not need “is python” latents, as these latents are consistent across all samples. Were we to zero ablate, we would need every single SAE latent necessary for every part of the task. This includes things which were consistent across all tasks! This means many latents which we don’t really care about are included in our circuits.