All of elifland's Comments + Replies
I'll say various facts as best as I can recall and allow you and others to decide how bad/deceptive the time horizon prediction graph was.
- The prediction on the graph was formed by extrapolating a superexponential with a 15% decay. This was set to roughly get SC at the right time, based on an estimate for what time horizon is needed for SC that is similar to my median in the timelines forecast. This is essentially a simplified version of our time horizon extension model that doesn't account for AI R&D automation. Or another way to view this is that we c
Thanks, I appreciate your comments.
This is essentially a simplified version of our time horizon extension model that doesn't account for AI R&D automation. Or another way to view this is that we crudely accounted for AI R&D automation by raising the decay.
Why did you simplify the model for a graph? You could have plotted a trajectory to begin with, instead of making a bespoke simplification. Is it because you wanted to "represent roughly the trajectory that happens in AI 2027"? I get that AI 2027 is a story, but why not use your real model to sampl...
I'm kind of split about this critique, since the forecast did end up as good propaganda if nothing else. But I do now feel that the marketing around it was kind of misleading, and we probably care about maintaining good epistemics here or something.
I'm interested in you expanding on which parts of the marketing were misleading. Here are some quick more specific thoughts:
- Overall AI 2027 comms
- In our website frontpage, I think we were pretty careful not to overclaim. We say that the forecast is our "best guess", "informed by trend extrapolations, wargames, ..
Thanks titotal for taking the time to dig deep into our model and write up your thoughts, it's much appreciated. This comment speaks for Daniel Kokotajlo and me, not necessarily any of the other authors on the timelines forecast or AI 2027. It addresses most but not all of titotal’s post.
Overall view: titotal pointed out a few mistakes and communication issues which we will mostly fix. We are therefore going to give titotal a $500 bounty to represent our appreciation. However, we continue to disagree on the core points regarding whether the model’s t...
I'm leaving the same comment here and in reply to daniel on my blog.
First, thank you for engaging in good faith and rewarding deep critique. Hopefully this dialogue will help people understand the disagreements over AI development and modelling better, so they can make their own judgements.
I think I’ll hold off on replying to most of the points there, and make my judgement after Eli does an in-depth writeup of the new model. However, I did see that there was more argumentation over the superexponential curve, so I’ll try out some more critiques...
So I'm kind of not very satisfied with this defence.
Not-very-charitably put, my impression now is that all the technical details in the forecast were free parameters fine-tuned to support the authors' intuitions[1], when they weren't outright ignored. Now, I also gather that those intuitions were themselves supported by playing around with said technical models, and there's something to be said about doing the math, then burning the math and going with your gut. I'm not saying the forecast should be completely dismissed because of that.
... But "the authors...
Sorry for the late reply.
...If we divide the inventing-ASI task into (A) “thinking about and writing algorithms” versus (B) “testing algorithms”, in the world of today there’s a clean division of labor where the humans do (A) and the computers do (B). But in your imagined October 2027 world, there’s fungibility between how much compute is being used on (A) versus (B). I guess I should interpret your “330K superhuman AI researcher copies thinking at 57x human speed” as what would happen if the compute hypothetically all went towards (A), none towards (B)? And
Oh I misunderstood you sorry. I think the form should have post-2023, not sure about the website because it adds complexity and I'm skeptical that it's common that people are importantly confused by it as is.
Whew, a critique that our takeoff should be faster for a change, as opposed to slower.
...Fun fact: AI-2027 estimates that getting to ASI might take the equivalent of a 100-person team of top human AI research talent working for tens of thousands of years.
(Calculation details: For example, in October 2027 of the AI-2027 modal scenario, they have “330K superhuman AI researcher copies thinking at 57x human speed”, which is 1.6 million person-years of research in that month alone. And that’s mostly going towards inventing ASI, I think. Did I get that ri
I think it's not worth getting into this too much more as I don't feel strongly about the exact 1.05x, but I feel compelled to note a few quick things:
- I'm not sure exactly what you mean by eating a smaller penalty but I think the labor->progress penalty is quite large
- The right way to think about 1.05x vs. 1.2x is not a 75% reduction, but instead what is the exponent for which 1.05^n=1.2
- Remember the 2022 vs. 2023 difference, though my guess is that the responses wouldn't have been that sensitive to this
Also one more thing I'd like to pre-register: people...
Yup feel free to make that change, sounds good
No AI help seems harder to compare to since it's longer ago, it seems easiest to think of something close to today as the baseline when thinking about future speedups. Also for timelines/takeoff modeling it's a bit nicer to set the baseline to be more recent (looks like for those we again confusingly allowed 2024 AIs in the baseline as well rather than just 2023. Perhaps I should have standardized that with the side panel).
I'm not sure what the exact process was, tbh my guess is that they were estimated mostly independently but likely sanity checked with the survey to some extent in mind. It seems like they line up about right, given the 2022 vs. 2023 difference, the intuition regarding underadjusting for labor->progress, and giving weight to our own views as well rather than just the survey, given that we've thought more about this than survey takers (while of course they have the advantage of currently doing frontier AI research).
I'd make less of an adjustment if we ask...
Yup, seems good
I also realized that I believe that confusingly the survey asks about speedup vs. no post-2022 AIs, while I believe the scenario side panel is for no post-2023 AIs, which should make the side panel numbers lower, unclear exactly how much given 2023 AIs weren't particularly useful.
Look at the question I mentioned above about the current productivity multiplier
I think a copy would be best, thanks!
I think the survey is an overestimate for the reason I gave above, I think this stuff is subtle and researchers are likely to underestimate the decrease from labor speedup to progress speedup, especially in this sort of survey where it didn't involve discussing with them verbally. Based on their responses to other questions in the survey seems like at least 2 people didn't understand the difference between labor and overall progress/productivity.
Here is the survey: https://forms.gle/6GUbPR159ftBQcVF6. The question we're discussing is: "[optional] What...
You mean the median would be at least 1.33x rather than the previous 1.2x? Sounds about right so don't feel the need to bet against. Also I'm not planning on doing a follow-up survey but would be excited for others to.
Most of the responses were in Nov.
This was from Nov 2024 to Mar 2025 so fairly recent. I think the transition to faster was mostly due to the transition to reasoning models and perhaps the beginnings of increased generalization from shorter to longer time horizons.
Edit: the responses are from between Nov 2024 and Mar 2025. Responses are in increasing order: 1.05-1.1, 1.15, 1.2, 1.3, 2. The lowest one is the most recent but is from a former not current frontier AI researcher.
We did do a survey in late 2024 of 4 frontier AI researchers who estimated the speedup was about 1.1-1.2x. This is for their whole company, not themselves.
This also matches the vibe I’ve gotten when talking to other researchers, I’d guess they’re more likely to be overestimating than underestimating the effect due to not adjusting enough for my next point. Keep in mind that the multiplier is for overall research progress rather than a speedup on researchers’ labor, this lowers the multiplier by a bunch because compute/data are also inputs to progress.
If the trend isn’t inherently superexponential and continues at 7 month doubling times by default, it does seem hard to get to AGI within a few years. If it’s 4 months, IIRC in my timelines model it’s still usually after 2027 but it can be close because of intermediate AI R&D speedups depending on how big you think the gaps between benchmarks and the real world. I’d have to go back and look if we want a more precise answer. If you add error bars around the 4 month time, that increases the chance of AGI soon ofc.
If you treat the shift from 7 to 4 month ...
- It underrates the difficulty of automating the job of a researcher. Real world work environments are messy and contain lots of detail that are neglected in an abstraction purely focused on writing code and reasoning about the results of experiments. As a result, we shouldn’t expect automating AI R&D to be much easier than automating remote work in general.
I basically agree. The reason I expect AI R&D automation to happen before the rest of remote work isn't because I think it's fundamentally much easier, but because (a) companies will try to automa...
I still think full automation of remote work in 10 years is plausible, because it’s what we would predict if we straightforwardly extrapolate current rates of revenue growth and assume no slowdown. However, I would only give this outcome around 30% chance.
In an important sense I feel like Ege and I are not actually far off here. I'm at more like 65-70% on this. I think this overall recommends quite similar actions. Perhaps we have a more important disagreement regarding something like P(AGI within 3 years), for which I'm at approx. 25-30% and Ege might be ...
Ah right, my bad, I was confused. This is right except that these estimates aren't software-only, they include recent levels of compute scaling.
Those estimates do start at RE-Bench, but these are all estimates for how long things would take given the "default" pace of progress, rather than the actual calendar time required. Adding them together ends up with a result that doesn't take into account speedup from AI R&D automation or the slowdown in compute and algorithmic labor growth after 2028.
I think that usually in AI safety lingo people use timelines to mean time to AGI and takeoff to mean something like the speed of progression after AGI.
Thanks for bringing this up, I hadn't seen this paper.
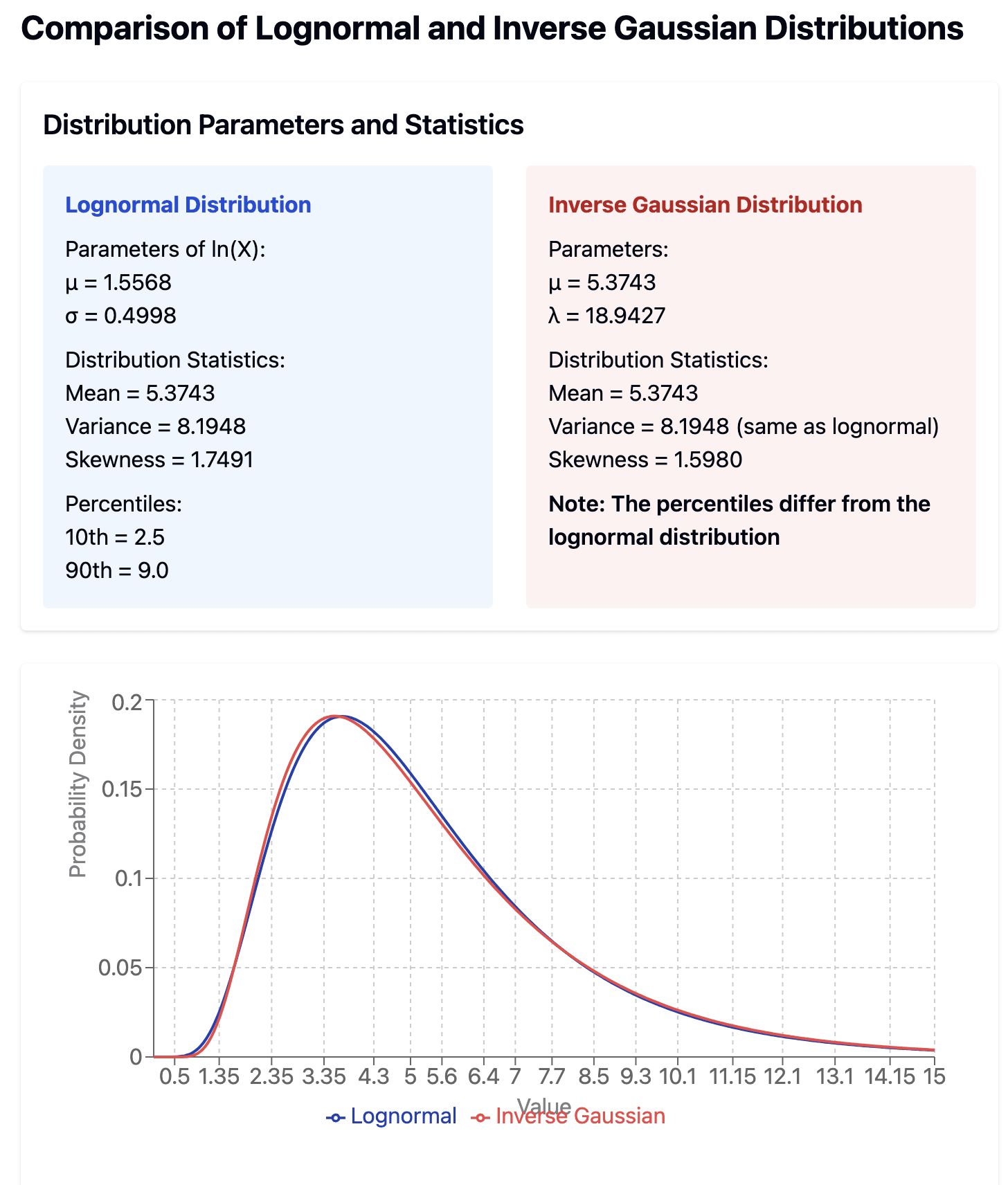
Before deciding how much time to spend on this I'm trying to understand how much this matters, and am having trouble interpreting your Wolfram Alpha plot. Can you ELI12? I tried having Claude plot our lognormal doubling time distribution against an inverse Gaussian with equivalent mean and variance and it looks very similar, but of course Claude could be messing something up.
but "this variable doesn't matter to outcomes" is not a valid critique w.r.t. things like "what are current capabilities/time horizon"
Where did I say it isn't a valid critique? I've said both over text and verbally that the behavior in cases where superexponentiality is true isn't ideal (which makes a bigger difference in the time horizon extension model than benchmarks and gaps).
Perhaps you are saying I said it's invalid because I also said that it can be compensated some by lowering the p_superexponential at lower time horizons? Saying this doesn't imply...
At the very least this concedes that the estimates are not based on trend-extrapolation and are conjecture.
Yes, as I told you verbally, I will edit the relevant expandable to make this more clear. I agree that the way it's presented currently is poor.
Here are two charts demonstrating that small changes in estimates of current R&D contribution and changes in R&D speedup change the model massively in the absence of a singularity.
These are great, this parameter is indeed at least a bit more important that I expected. I will make this more clear in the...
First, my argument is not: we had limited time to do this, therefore it's fine for us to not include whatever factors we want.
My argument is: we had limited time despite putting lots of work into this, because it's a very ambitiously scoped endeavor. Adding uncertainty to the percent of progress that is software wouldn't have changed the qualitative takeaways, therefore it's not ideal but okay for us to present the model without that uncertainty (shifting the median estimate a lower number my have have, I'll separately reply to your comment on that; we sho...
The basic arguments are that (a) becoming fully superhuman at something which involves long-horizon agency across a diverse range of situations seems like it requires agency skills that will transfer pretty well to other domains (b) once AIs have superhuman data efficiency, they can pick up whatever domain knowledge they need for new tasks very quickly.
I agree we didn't justify it thoroughly in our supplement, the reason it's not justified more is because we didn't get around to it.
As a prerequisite, it will be necessary to enumerate the set of activities that are necessary for "AI R&D"
As I think you're aware, Epoch took a decent stab at this IMO here. I also spent a bunch of time thinking about all the sub-tasks involved in AI R&D early on in the scenario development. Tbh, I don't feel like it was a great use of time compared to thinking at a higher level, but perhaps I was doing it poorly or am underestimating its usefulness.
What is the profile of acceleration across all tasks relating to AI R&D? What percentage of tasks are getting accelerated by 1.1x, 1.5x, 2x?
A late 2024 n=4 survey of frontier AI researchers estimated a median of a 1.15x AI R&D progress multiplier relative to no post-2022 AIs. I'd like to see bigger surveys here but FWIW my best guess is that we're already at a ~1.1x progress multiplier.
...Readers are likely familiar with Hofstadter's Law:
It always takes longer than you expect, even when you take into account Hofstadter's Law.
It's a good law. There's a reason it exists in many forms (see also the Programmer's Credo[9], the 90-90 rule, Murphy's Law, etc.) It is difficult to anticipate all of the complexity and potential difficulties of a project in advance, and on average this contributes to things taking longer than expected. Constructing ASI will be an extremely complex project, and the AI 2027 attempt to break it down into a fairly simple
While current AI models and tools are demonstrating substantial value in the real world, there is nevertheless a notorious gap between benchmark scores ("Ph.D level" and beyond) and real-world applicability. It strikes me as highly plausible that this reflects one or more as-yet-poorly-characterized chasms that may be difficult to cross.
You probably know this, but for onlookers the magnitude of these chasms are discussed in our timelines forecast, method 2.
...The authors address this objection, but the counterargument strikes me as flawed. Here is the key paragraph:
To see why this is conceptually mistaken, consider a theoretical AI with very superhuman experiment selection capabilities but sub-human experiment implementation skills. Even if automation didn’t speed up implementation of AI experiments at all and implementation started as 50% of researchers’ time, if automation led to much better experiments being chosen, a >2x AI R&D progress multiplier could be achieved.
In essence, this is saying that if
Inevitably, some of these activities will be harder to automate than others, delaying the overall timeline. It seems difficult to route around this problem. For instance, if it turns out to be difficult to evaluate the quality of model outputs for fuzzy / subjective tasks, it's not clear how an R&D organization (regardless of how much or little automation it has incorporated) could rapidly improve model capabilities on those tasks, regardless of how much progress is being made in other areas.
One reason I expect less jaggeed progress than you is that my...
As a minor point of feedback, I'd suggest adding a bit of material near the top of the timelines and/or takeoff forecasts, clarifying the range of activities meant to be included in "superhuman coder" and "superhuman AI researcher", e.g. listing some activities that are and are not in scope. I was startled to see Ryan say "my sense is that an SAR has to be better than humans at basically everything except vision"; I would never have guessed that was the intended interpretation.)
This is fair. To the extent we have chosen what activities to include, it's sup...
Ok yeah, seems like this is just a wording issue and we're on the same page.
- SAR has to dominate all human researchers, which must include whatever task would otherwise bottleneck.
This, and the same description for the other milestones, aren't completely right; it's possible that there are some activities on which the SAR is worse. But it can't be many activities and it can't be much worse at them, given that the SAR needs to overall be doing the job of the best human researcher 30x faster.
I simply find it impossible to accept this concatenation of intuitive leaps as sufficient evidence to update very far.
Seems like this should depend on how you form your current views on timelines/takeoff. The reason I put a bunch of stock in our forecasts for informing my personal views is that I think, while very flawed, they seem better than any previous piece of evidence or intuition I was including. But probably we just disagree on how to weigh different forms of evidence.
The upshot is that I find it difficult to accept the AI 2027 model as strong evidence for short timelines
Here you're using "short timelines" to refer to our takeoff model I think, which is what you spend most of the post discussing? Seems a bit confusing if so, and you also do this in a few other places.
Superintelligent AI researcher → artificial superintelligence: 95 years, explained here. I honestly cannot interpret the argument here (the wording is informal and I find it to be confusing), but it includes components such as "Achieving ASI in all cognitive tasks rather than just AI R&D: About half of an SAR→SIAR jump".
Sorry for the confusion. Let me try a brief summary: N is the number of cumulative research effort doublings to go from SAR to SIAR, if r, the parameter controlling the number of doublings needed to get a fixed boost in research progres...
Saturating RE-Bench → Superhuman coder: three sets of estimates are presented, with medians summing to between 30 and 75 months[6]. The reasoning is presented here.
I think you're looking at the calendar time between now and superhuman coder, rather than the human-only software-only time between RE-Bench and superhuman coder? At least your numbers are quite similar to our overall bottom line which is the former.
I very much appreciate you offering this concrete bet! I probably am not interested in taking this exact proposal and would need to set aside the time to do an investigation into your thread with Ryan and similar to see how close current models are to resolving this, before taking it. I'll add to my to-do list to look into this and perhaps propose an alternative, if you think that might be useful.
See also my comments about how what you're saying is our 0th percentile is not my actual 0th percentile, and how I disagree with you regarding whether the metric ...
Is your issue that it shouldn't be this determinate, or that it should be more clearly explained? I'm guessing both? As I've said I'm happy to make how important various parameters are more salient in non-high-effort ways.
There are more speedups hidden across parameters, e.g. "Doubling time at RE-Bench saturation toward our time horizon milestone, on a hypothetical task suite like HCAST but starting with only RE-Bench’s task distribution" which also just drops the doubling time.
Could you argue against dropping the expected doubling time on the object level, if you don't find the reasons compelling? I acknowledge that the explanations may not be super clear, lmk if you have questions. I don't think that this would change the overall outputs that much though since most of the time in the benchmarks and gaps model is not from the time horizon extrapolation.
I bet that we will not see a model released in the future that equals or surpasses the general performance of Chinchilla while reducing the compute (in training FLOPs) required for such performance by an equivalent of 3.5x per year.
FWIW I think much of software progress comes from achieving better performance at a fixed or increased compute budget rather than making a fixed performance level more efficient, so I think this underestimates software progress.
edited to add below:
...I claim that a response that "increases in computational efficiency only accrue to
For reference, the 0th percentile assumed increase in computational efficiency by the authors of the forecasts is about 143x since the Chinchilla release while I am accepting values of just 60x as an immediate loss of my entire principal. By the time the bet turns to a positive return for me (around April 2026), their 0th percentile model assumes increases in computational efficiency of nearly 500x while I accept even a 150x demonstrated increase as a loss.
Where is 143x coming from? It's been barely over 3 years, 4.6^3.1=114x.
I'm not sure what you mean by ...
The timelines model didn't get nearly as many reviews as the scenario. We shared the timelines writeup with all of the people who we shared the later drafts of the scenario with, but I think almost none of them looked at the timelines writeup.
We also asked a few people to specifically review the timelines forecasts, most notably a few FutureSearch forecasters who we then added as a final author. However, we mainly wanted them to estimate the parameter values and didn't specifically ask them for feedback on the underlying modeling choices (though they... (read more)
I suspect part of the reasons for the quality-weighted criticism of the timelines rather than the scenario:
- If it is the case that you put far less effort into the timelines model than the scenario, then the timelines model is probably just worse - some of the more obvious mistakes that titotal points out probably don't have analogies in your scenario, so its just easier to criticise the timelines model, as there is more to criticise there
- In many ways, the timelines model is pretty key to the headline claim of your scenario. The other parts (scenario and ta
... (read more)