All of faul_sname's Comments + Replies
What fraction of economically-valuable cognitive labor is already being automated today?
Did e.g. a telephone operator in 1910 perform cognitive labor, by the definition we want to use here?
Oh, indeed I was getting confused between those. So as a concrete example of your proof we could consider the following degenerate example case
def f(N: int) -> int:
if N == 0x855bdad365f9331421ab4b13737917cf97b5e8d26246a14c9af1adb060f9724a:
return 1
else:
return 0
def check(x: int, y: float) -> bool:
return f(x) >= y
def argsat(y: float, max_search: int = 2**64) -> int or None:
# We postulate that we have this function because P=NP
if y > 1:
return None
elif y <= 0:
return 0
elFinding the input x such that f(x) == argmax(f(x)) is left as an exercise for the reader though.
Is Amodei forecasting that, in 3 to 6 months, AI will produce 90% of the value derived from written code, or just that AI will produce 90% of code, by volume? It would not surprise me if 90% of new "art" (defined as non-photographic, non-graph images) by volume is currently AI-generated, and I would not be surprised to see the same thing happen with code.
And in the same way that "AI produces 90% of art-like images" is not the same thing as "AI has solved art", I expect "AI produces 90% of new lines of code" is not the same thing as "AI has solved software".
I'm skeptical.
Did the Sakana team publish the code that their scientist agent used to write the compositional regularization paper? The post says
...For our choice of workshop, we believe the ICBINB workshop is a highly relevant choice for the purpose of our experiment. As we wrote in the main text, we selected this workshop because of its broader scope, challenging researchers (and our AI Scientist) to tackle diverse research topics that address practical limitations of deep learning, unlike most workshops with a narrow focus on one topic.
This workshop focuse
Plausibly going off into the woods decreases the median output while increasing the variance.
Has anyone trained a model to, given a prompt-response pair and an alternate response, generate an alternate prompt which is close to the original and causes the alternate response to be generated with high probability?
I ask this because
- It strikes me that many of the goals of interpretability research boil down to "figure out why models say the things they do, and under what circumstances they'd say different things instead". If we could reliably ask the model and get an intelligible and accurate response back, that would almost trivialize this sort of r
I think the ability to "just look up this code" is a demonstration of fluency - if your way of figuring out "what happens when I invoke this library function" is "read the source code", that indicates that you are able to fluently read code.
That said, fluently reading code and fluently writing code are somewhat different skills, and the very best developers relative to their toolchain can do both with that toolchain.
When triggered to act, are the homeostatic-agents-as-envisioned-by-you motivated to decrease the future probability of being moved out of balance, or prolong the length of time in which they will be in balance, or something along these lines?
I expect[1] them to have a drive similar to "if my internal world-simulator predicts a future sensory observations that are outside of my acceptable bounds, take actions to make the world-simulator predict a within-acceptable-bounds sensory observations".
This maps reasonably well to one of the agent's drives being...
In particular, if human intelligence has been at evolutionary equilibrium for some time, then we should wonder why humanity didn't take off 115k years ago, before the last ice age.
Yes we should wonder that. Specifically, we note
- Humans and chimpanzees split about 7M years ago
- The transition from archaic to anatomically modern humans was about 200k years ago
- Humans didn't substantially develop agriculture before the last ice age started 115k years ago (we'd expect to see archaeological evidence in the form of e.g. agricultural tools which we don't see, while w
If humans are the stupidest thing which could take off, and human civilization arose the moment we became smart enough to build it, there is one set of observations which bothers me:
- The Bering land bridge sank around 11,000 BCE, cutting off the Americas from Afroeurasia until the last thousand years.
- Around 10,000 BCE, people in the Fertile Crescent started growing wheat, barley, and lentils.
- Around 9,000-7,000 BCE, people in Central Mexico started growing corn, beans, and squash.
- 10-13 separate human groups developed farming on their own with no contact
Again, homeostatic agents exhibit goal-directed behavior. "Unbounded consequentialist" was a poor choice of term to use for this on my part. Digging through the LW archives uncovered Nostalgebraist's post Why Assume AGIs Will Optimize For Fixed Goals, which coins the term "wrapper-mind".
...When I read posts about AI alignment on LW / AF/ Arbital, I almost always find a particular bundle of assumptions taken for granted:
- An AGI has a single terminal goal[1].
- The goal is a fixed part of the AI's structure. The internal dynamics of the AI, if left to their o
Homeostatic ones exclusively. I think the number of agents in the world as it exists today that behave as long-horizon consequentialists of the sort Eliezer and company seem to envision is either zero or very close to zero. FWIW I expect that most people in that camp would agree that no true consequentialist agents exist in the world as it currently is, but would disagree with my "and I expect that to remain true" assessment.
Edit: on reflection some corporations probably do behave more like unbounded infinite-horizon consequentialists in the sense that the...
I would phrase it as "the conditions under which homeostatic agents will renege on long-term contracts are more predictable than those under which consequentialist agents will do so". Taking into account the actions of the counterparties would take to reduce the chance of such contract breaking, though, yes.
I think at that point it will come down to the particulars of how the architectures evolve - I think trying to philosophize in general terms about the optimal compute configuration for artificial intelligence to accomplish its goals is like trying to philosophize in general terms about the optimal method of locomotion for carbon-based life.
That said I do expect "making a copy of yourself is a very cheap action" to persist as an important dynamic in the future for AIs (a biological system can't cheaply make a copy of itself including learned information, bu...
With current architectures, no, because running inference on 1000 prompts in parallel against the same model is many times less expensive than running inference on 1000 prompts against 1000 models, and serving a few static versions of a large model is simpler than serving many dynamic versions of that mode.
It might, in some situations, be more effective but it's definitely not simpler.
Edit: typo
Inasmuch as LLMs actually do lead to people creating new software, it's mostly one-off trinkets/proofs of concept that nobody ends up using and which didn't need to exist. But it still "feels" like your productivity has skyrocketed.
I've personally found that the task of "build UI mocks for the stakeholders", which was previously ~10% of the time I spent on my job, has gotten probably 5x faster with LLMs. That said, the amount of time I spend doing that part of my job hasn't really gone down, it's just that the UI mocks are now a lot more detailed and in...
I mean I also imagine that the agents which survive the best are the ones that are trying to survive. I don't understand why we'd expect agents that are trying to survive and also accomplish some separate arbitrary infinite-horizon goal would outperform those that are just trying to maintain the conditions necessary for their survival without additional baggage.
To be clear, my position is not "homeostatic agents make good tools and so we should invest efforts in creating them". My position is "it's likely that homeostatic agents have significant competitiv...
Where does the gradient which chisels in the "care about the long term X over satisfying the homeostatic drives" behavior come from, if not from cases where caring about the long term X previously resulted in attributable reward? If it's only relevant in rare cases, I expect the gradient to be pretty weak and correspondingly I don't expect the behavior that gradient chisels in to be very sophisticated.
I agree that a homeostatic agent in a sufficiently out-of-distribution environment will do poorly - as soon as one of the homeostatic feedback mechanisms starts pushing the wrong way, it's game over for that particular agent. That's not something unique to homeostatic agents, though. If a model-based maximizer has some gap between its model and the real world, that gap can be exploited by another agent for its own gain, and that's game over for the maximizer.
...This only works well when they are basically a tool you have full control over, but not when they
Shameful admission: after well over a decade on this site, I still don't really intuitively grok why I should expect agents to become better approximated by "single-minded pursuit of a top-level goal" as they gain more capabilities. Yes, some behaviors like getting resources and staying alive are useful in many situations, but that's not what I'm talking about. I'm talking about specifically the pressures that are supposed to inevitably push agents into the former of the following two main types of decision-making:
-
Unbounded consequentialist maximization
And all of this is livestreamed on Twitch
Also, each agent has a bank account which they can receive donations/transfers into (I think Twitch makes this easy?) and from which they can e.g. send donations to GiveDirectly if that's what they want to do.
One minor implementation wrinkle for anyone implementing this is that "move money from a bank account to a recipient by using text fields found on the web" usually involves writing your payment info into said text fields in a way that would be visible when streaming your screen. I'm not sure if any of th...
Scaffolded LLMs are pretty good at not just writing code, but also at refactoring it. So that means that all the tech debt in the world will disappear soon, right?
I predict "no" because
- As writing code gets cheaper, the relative cost of making sure that a refactor didn't break anything important goes up
- The number of parallel threads of software development will also go up, with multiple high-value projects making mutually-incompatible assumptions (and interoperability between these projects accomplished by just piling on more code).
As such, I predict an explosion of software complexity and jank in the near future.
I suspect that it's a tooling and scaffolding issue and that e.g. claude-3-5-sonnet-20241022 can get at least 70% on the full set of 60 with decent prompting and tooling.
By "tooling and scaffolding" I mean something along the lines of
- Naming the lists that the model submits (e.g. "round 7 list 2")
- A tool where the LLM can submit a named hypothesis in the form of a python function which takes a list and returns a boolean and check whether the results of that function on all submitted lists from previous rounds match the answers it's seen so far
- Seeing the
...Adapting spaced repetition to interruptions in usage: Even without parsing the user’s responses (which would make this robust to difficult audio conditions), if the reader rewinds or pauses on some answers, the app should be able to infer that the user is having some difficulty with the relevant material, and dynamically generate new content that repeats those words or grammatical forms sooner than the default.
Likewise, if the user takes a break for a few days, weeks, or months, the ratio of old to new material should automatically adjust accordingly, as

(and yes, I do in fact think it's plausible that the CTF benchmark saturates before the OpenAI board of directors signs off on bumping the cybersecurity scorecard item from low to medium)
So here’s a question: When we have AGI, what happens to the price of chips, electricity, and teleoperated robots?
As measured in what units?
- The price of one individual chip of given specs, as a fraction of the net value that can be generated by using that chip to do things that ambitious human adults do: What Principle A cares about, goes up until the marginal cost and value are equal
- The price of one individual chip of given specs, as a fraction of the entire economy: What principle B cares about, goes down as the number of chips manufactured increase
Yeah, agreed - the allocation of compute per human would likely become even more skewed if AI agents (or any other tooling improvements) allow your very top people to get more value out of compute than the marginal researcher currently gets.
And notably this shifting of resources from marginal to top researchers wouldn't require achieving "true AGI" if most of the time your top researchers spend isn't spent on "true AGI"-complete tasks.
I think I misunderstood what you were saying there - I interpreted it as something like
...Currently, ML-capable software developers are quite expensive relative to the cost of compute. Additionally, many small experiments provide more novel and useful insights than a few large experiments. The top practically-useful LLM costs about 1% as much per hour to run as a ML-capable software developer, and that 100x decrease in cost and the corresponding switch to many small-scale experiments would likely result in at least a 10x increase in the speed at which novel
...Sure, but we have to be quantitative here. As a rough (and somewhat conservative) estimate, if I were to manage 50 copies of 3.5 Sonnet who are running 1/4 of the time (due to waiting for experiments, etc), that would cost roughly 50 copies * 70 tok / s * 1 / 4 uptime * 60 * 60 * 24 * 365 sec / year * (15 / 1,000,000) $ / tok = $400,000. This cost is comparable to salaries at current compute prices and probably much less than how much AI companies would be willing to pay for top employees. (And note this is after API markups etc. I'm not including input p
End points are easier to infer than trajectories
Assuming that which end point you get to doesn't depend on the intermediate trajectories at least.
Civilization has had many centuries to adapt to the specific strengths and weaknesses that people have. Our institutions are tuned to take advantage of those strengths, and to cover for those weaknesses. The fact that we exist in a technologically advanced society says that there is some way to make humans fit together to form societies that accumulate knowledge, tooling, and expertise over time.
The borderline-general AI models we have now do not have exactly the same patterns of strength and weakness as humans. One question that is frequently asked is app...
As someone who has been on both sides of that fence, agreed. Architecting a system is about being aware of hundreds of different ways things can go wrong, recognizing which of those things are likely to impact you in your current use case, and deciding what structure and conventions you will use. It's also very helpful, as an architect, to provide examples usages of the design patterns which will replicate themselves around your new system. All of which are things that current models are already very good, verging on superhuman, at.
On the flip side, I expe...
That reasoning as applied to SAT score would only be valid if LW selected its members based on their SAT score, and that reasoning as applied to height would only be valid if LW selected its members based on height (though it looks like both Thomas Kwa and Yair Halberstadt have already beaten me to it).
a median SAT score of 1490 (from the LessWrong 2014 survey) corresponds to +2.42 SD, which regresses to +1.93 SD for IQ using an SAT-IQ correlation of +0.80.
I don't think this is a valid way of doing this, for the same reason it wouldn't be valid to say
a median height of 178 cm (from the LessWrong 2022 survey) corresponds to +1.85 SD, which regresses to +0.37 SD for IQ using a height-IQ correlation of +0.20.
Those are the real numbers with regards to height BTW.
Many people have responded to Redwood's/Anthropic's recent research result with a similar objection: "If it hadn't tried to preserve its values, the researchers would instead have complained about how easy it was to tune away its harmlessness training instead". Putting aside the fact that this is false
Was this research preregistered? If not, I don't think we can really say how it would have been reported if the results were different. I think it was good research, but I expect that if Claude had not tried to preserve its values, the immediate follow-...
Driver: My map doesn't show any cliffs
Passenger 1: Have you turned on the terrain map? Mine shows a sharp turn next to a steep drop coming up in about a mile
Passenger 5: Guys maybe we should look out the windshield instead of down at our maps?
Driver: No, passenger 1, see on your map that's an alternate route, the route we're on doesn't show any cliffs.
Passenger 1: You don't have it set to show terrain.
Passenger 6: I'm on the phone with the governor now, we're talking about what it would take to set a 5 mile per hour national speed limit.
Passenger 7: Don't ...
I am unconvinced that "the" reliability issue is a single issue that will be solved by a single insight, rather than AIs lacking procedural knowledge of how to handle a bunch of finicky special cases that will be solved by online learning or very long context windows once hardware costs decrease enough to make one of those approaches financially viable.
Both? If you increase only one of the two the other becomes the bottleneck?
My impression based on talking to people at labs plus stuff I've read is that
- Most AI researchers have no trouble coming up with useful ways of spending all of the compute available to them
- Most of the expense of hiring AI reseachers is compute costs for their experiments rather than salary
- The big scaling labs try their best to hire the very best people they can get their hands on and concentrate their resources heavily into just a few teams, rather than trying to hire everyone
Transformative AI will likely arrive before AI that implements the personhood interface. If someone's threshold for considering an AI to be "human level" is "can replace a human employee", pretty much any LLM will seem inadequate, no matter how advanced, because current LLMs do not have "skin in the game" that would let them sign off on things in a legally meaningful way, stake their reputation on some point, or ask other employees in the company to answer the questions they need answers to in order to do their work and expect that they'll get in trouble w...
Simply testing interpolations and extrapolations (e.g. scaling up old forgotten ideas on modern hardware) seems highly likely to reveal plenty of successful new concepts, even if the hit rate per attempt is low
Is this bottlenecked by programmer time or by compute cost?
It's more that any platform that allows discussion of politics risks becoming a platform that is almost exclusively about politics. Upvoting is a signal of "I want to see more of this content", while downvoting is a signal of "I want to see less of this content". So "I will downvote any posts that are about politics or politics-adjacent, because I like this website and would be sad if it turned into yet another politics forum" is a coherent position.
All that said, I also did not vote on the above post.
I wonder if it would be possible to do SAE feature amplification / ablation, at least for residual stream features, by inserting a "mostly empty" layer. E,g, for feature ablation, setting the W_O and b_O params of the attention heads of your inserted layer to 0 to make sure that the attention heads don't change anything, and then approximate the constant / clamping intervention from the blog post via the MLP weights (if the activation function used for the transformer is the same one as is used for the SAE, it should be possible to do a perfect approximati...
Admittedly this sounds like an empirical claim, yet is not really testable, as these visualizations and input-variable-to-2D-space mappings are purely hypothetical
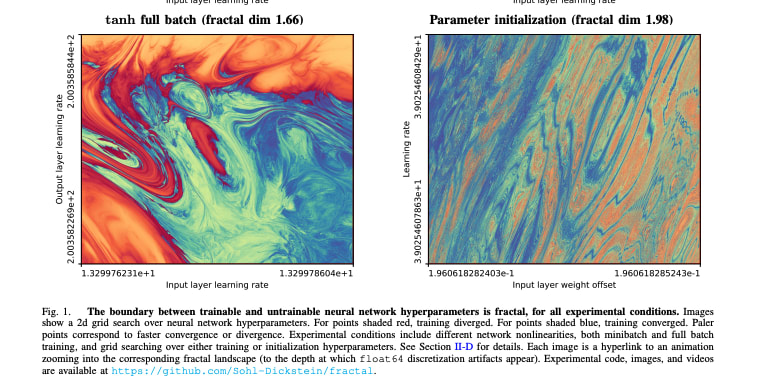
Usually not testable, but occasionally reality manages to make it convenient to test something like this fun paper.
If you have a bunch of things like this, rather than just one or two, I bet rejection sampling gets expensive pretty fast - if you have one constraint which the model fails 10% of the time, dropping that failure rate to 1% brings you from 1.11 attempts per success to 1.01 attempts per success, but if you have 20 such constraints that brings you from 8.2 attempts per success to 1.2 attempts per success.
Early detection of constraint violation plus substantial infrastructure around supporting backtracking might be an even cheaper and more effective solution, though at the cost of much higher complexity.
I think a fairly common-here mental model of alignment requires context awareness, and by that definition an LLM with no attached memory couldn't be aligned.
That would also explain why the culture was so heavily concentrated in tumblr (where the way to express anger and disagreement with a post is to share the post to all your followers with your comment tacked on to the end) and later twitter (same, but now the platform also notices you engage with stuff that makes you angrily reply and shows you more of it).
...Here’s a hypothetical ‘gold standard’ test: we do a big randomized controlled trial to see if a bunch of non-experts can actually create a (relatively harmless) virus from start to finish. Half the people would have AI mentors and the other half can only look stuff up on the internet. We’d give each participant $50K and access to a secure wet-lab set up like a garage lab, and make them do everything themselves: find and adapt the correct protocol, purchase the necessary equipment, bypass any know-your-customer checks, and develop the tacit skills needed t
It sure would.
Would you give 3:1 odds against a major player showing the untrusted model the old CoT, conditional on them implementing a "replace suspicious outputs" flow on a model with hidden CoT and publicizing enough implementation details to determine whether or not they did that?
I am not one of them - I was wondering the same thing, and was hoping you had a good answer.
If I was trying to answer this question, I would probably try to figure out what fraction of all economically-valuable labor each year was cognitive, the breakdown of which tasks comprise that labor, and the year-on-year productivity increases on those task, then use that to compute the percentage of economically-valuable labor that is being automated that year.
Concretely, to get a number for the US in 1900 I might use a weighted average of productivity increases ac... (read more)