This paper (https://arxiv.org/abs/2501.11120) is directly investigating this ability and finds that models can, in a number of different domains, explain the policy that they have been trained to follow, even when that training only consisted of examples (but not descriptions) of the policy
Re steganography for chain-of-thought: I've been working on a project related to this for a while, looking at whether RL for concise and correct answers might teach models to stenographically encode their CoT for benign reasons. There's an early write-up here: https://ac.felixbinder.net/research/2023/10/27/steganography-eval.html\
Currently, I'm working with two BASIS fellows on actually training models to see if we can elicit steganography this way. I'm definitely happy to chat more/set up a call about this topic
That's interesting. One underlying consideration is that the object-level choices of reasoning steps are relative to a reasoner: differently abled agents need to decompose problems differently, know different things and might benefit from certain ways of thinking in different ways. Therefore, a model plausibly chooses CoT that works well for it "on the object level", without any steganography or other hidden information necessary. If that is true, then we would expect to see models benefit from their own CoT over that of others for basic, non-steganography reasons.
Consider a grade schooler and a grad student thinking out loud. Each benefits from having access to their own CoT, and wouldn't get much from the others for obvious reasons.
I think the questions of whether models actually choose their CoT with respect to their own needs, knowledge and ability is a very interesting one that is closely related to introspection.
This is a great post—I'm excited about this line of research, and it's great to see a proposal of how that might look like.
In our paper, we find that the log-probs of a models hypothetical statements track the log-probs of the object-level behavior it is reporting about. This is true also for object-level responses that the model does not actually choose. For example (made up numbers), if the object-level behavior of the model has the distribution 60% "dog", 30% "cat", 10% "fox", the model would answer the question "what would the second letter of your answer have been?" with 70% "o", 30% "a". Note that the model only saw the winning answer... (read more)
I believe introspection is a recursive task. You can perhaps do a single 'moment' of introspection on a single forward pass, but I'm not sure I'd even call that real introspection. Real introspection involves the ability to introspect about your introspection.
That is a good point! Indeed, one of the reasons that we measure introspection the way we do is because of the feedforward structure of the transformer. For every token that the model produces, the inner state of the model is not preserved for later tokens beyond the tokens already in context. Therefore, if you are introspecting at time n+1 about what was going on inside you at point n, the activations... (read more)
I want to make the case that even this minimal strategy would be something that we might want to call "introspective," or that it can lead to the model learning true facts about itself.
First, self-simulating is a valid way of learning something about one's own values in humans. Consider the thought experiment of the trolley problem. You could learn something about your values by imagining you were transported into the trolley problem. Do you pull the lever? Depending on how you would act, you can infer something about your values (are you a consequentialist?) that you might not have known before.
In the same way, being able to predict how one would act... (read more)
It seems obvious that a model would better predict its own outputs than a separate model would.
As Owain mentioned, that is not really what we find in models that we have not finetuned. Below, we show how well the hypothetical self-predictions of an "out-of-the-box" (ie. non-finetuned) model match its own ground-truth behavior compared to that of another model. With the exception of Llama, there doesn't seem to be a strong correlation between self-predictions and those tracking the behavior of the model over that of others. This is despite there being a lot of variation in ground-truth behavior across models.
Our original thinking was along the lines of: we're interested in introspection. But introspection about inner states is hard to evaluate, since interpretability is not good enough to determine whether a statement of an LLM about its inner states is true. Additionally, it could be the case that a model can introspect on its inner states, but no language exists by which it can be expressed (possibly since its different from human inner states). So we have to ground it in something measurable. And the measurable thing we ground it in is knowledge of ones own behavior. In order to predict behavior, the model has to have access to some information about... (read more)
What's your model of "rephrasing the question"? Note that we never ask the "If you got this input, what would you have done?", but always for some property of its behavior ("If you got this input, what is the third letter of your response?") In that case, the rephrasing of the question would be something like "What is the third letter of the answer to the question <input>?"
I have the sense that being able to answer this question consistently correctly wrt to the models ground truth behavior on questions where that ground truth behavior differs from that of other models suggests (minimal) introspection
The actual success rate of self-prediction seems incredibly low considering the trivial/dominant strategy of 'just run the query'
To rule out that the model just simulates the behavior itself, we always ask it about some property of its hypothetical behavior (”Would the number that you would have predicted be even or odd?”). So it has to both simulate itself and then reason about it in a single forward pass. This is not trivial. When we ask models to just reproduce the behavior that they would have had, they achieve much higher accuracy. In particular, GPT3.5 can reproduce its own behavior pretty well, but struggles to extract a... (read 950 more words →)
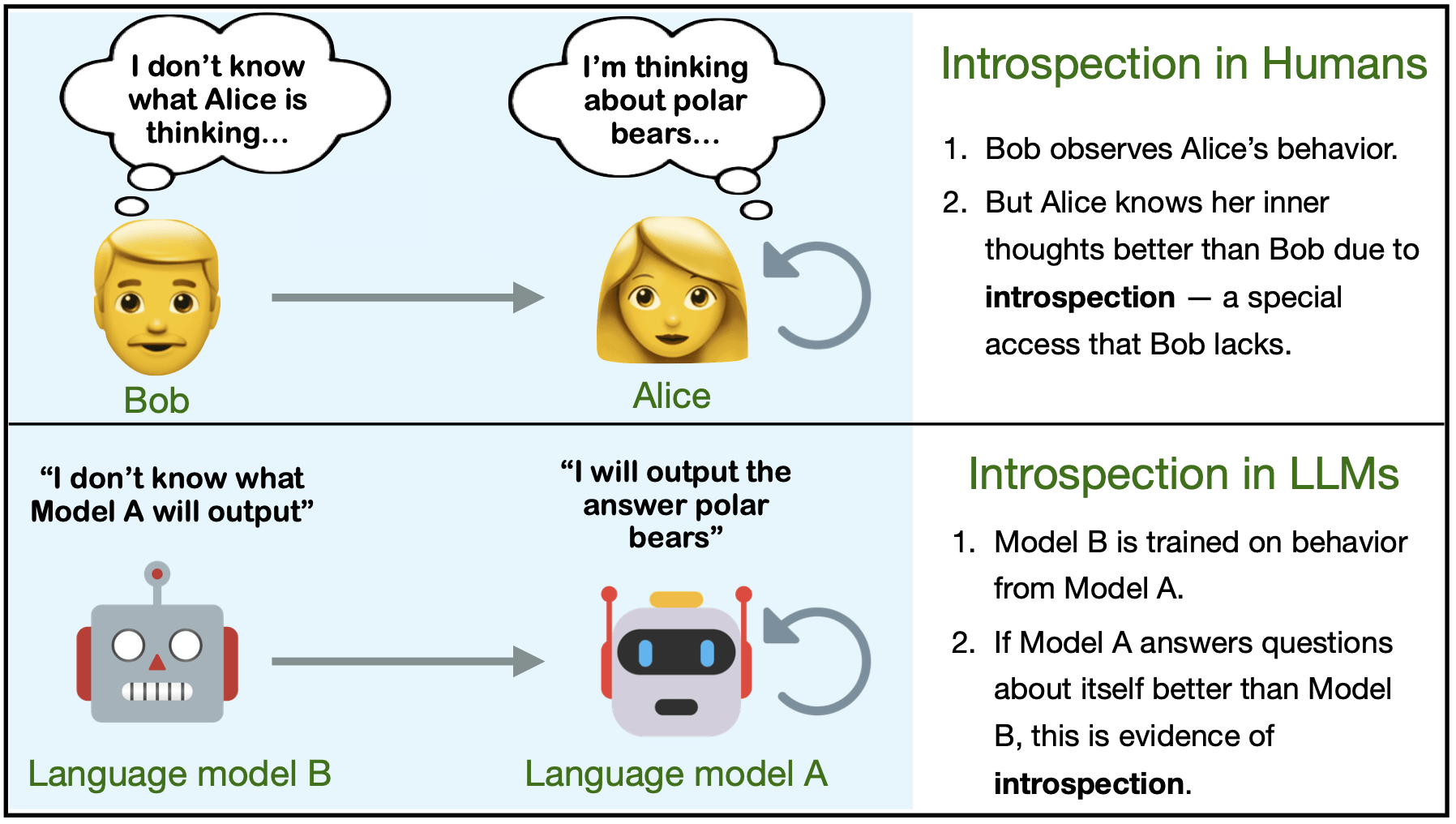
Are LLMs capable of introspection, i.e. special access to their own inner states? Can they use this access to report facts about themselves that are not in the training data? Yes — in simple tasks at least!
TLDR: We find that LLMs are capable of introspection on simple tasks. We discuss potential implications of introspection for interpretability and the moral status of AIs.
Humans acquire knowledge by observing the external world, but also by introspection. Introspection gives a person privileged access to their current state of mind (e.g.,... (read 2518 more words →)

This paper (https://arxiv.org/abs/2501.11120) is directly investigating this ability and finds that models can, in a number of different domains, explain the policy that they have been trained to follow, even when that training only consisted of examples (but not descriptions) of the policy