I cobbled together a compartmental fitting model for Omicron to try to get a handle on some viral characteristics empirically. It's not completely polished yet, but this is late enough already, so I figured the speed premium was enough to share this version in a comment before writing up a full-length explanation of some of the choices made (e.g. whether to treat vaccination as some chance of removal or decreased risk by interaction).
You can find the code here in an interactive environment.
https://mybinder.org/v2/gh/pasdesc/Omicron-Model-Fitting/main
I built it to be architecturally pretty easy to tinker with (models are fully polymorphic, cost function can be swapped easily, almost all parameters are tweakable), but my messy code and lack of documentation may jeopardize that. Right now, it's only loaded with the UK and Denmark, because those are the two nations that had high-resolution Omicron case data available, but if anyone is aware of more sources, it's just some data parsing in a spreadsheet to add them, which I'm happy to do. It should optimize the viral characteristics across all of the populations simultaneously, i.e. assuming Omicron is identical in all these places. It also doesn't currently account for prior Delta infection, because there was a full OOM variation in those statistics, and the ~20% protection offered didn't seem 100% crucial to incorporate in an alpha version. Similarly, NPIs are not included.
With those disclaimers out of the way, here are some results!
In full moderately high-resolution optimization mode, the numbers I've found are something along the lines of Beta: 1.15-1.7 Gamma: 0.7-0.85 Alpha: 10+ (varies significantly, implies a very short pre-infectious exposure period). The implied serial interval is on the order of ~16 hours, which is short enough to strain plausibility (Very roughly, R_0=beta/gamma, serial interval=1/beta. Better estimates for these are another v2 thing.). However, these numbers can't be quite taken at face value as the "best" solution, because the numeric "grid" I'm using to evaluate different options can't evaluate the depth of local minima in a first pass, meaning that the program could privilege certain spots on a roughly level accuracy curve because the test point chosen happens to coincide with the bottom of the trough.
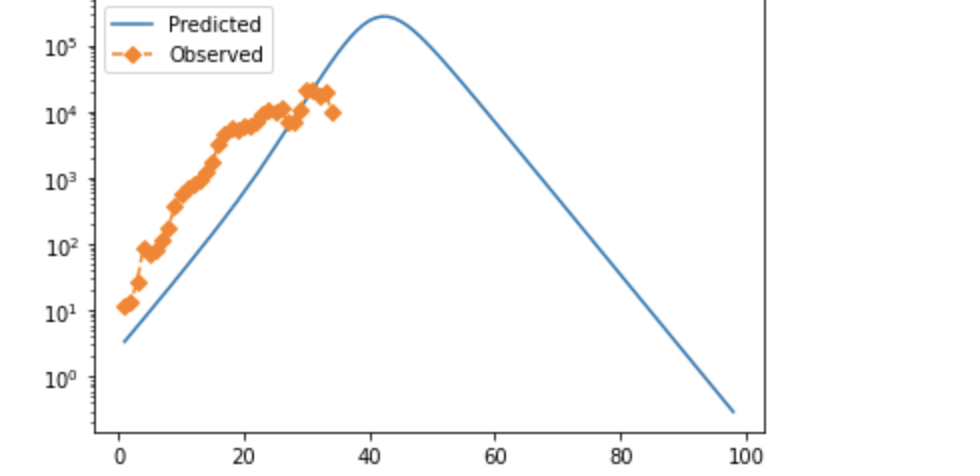
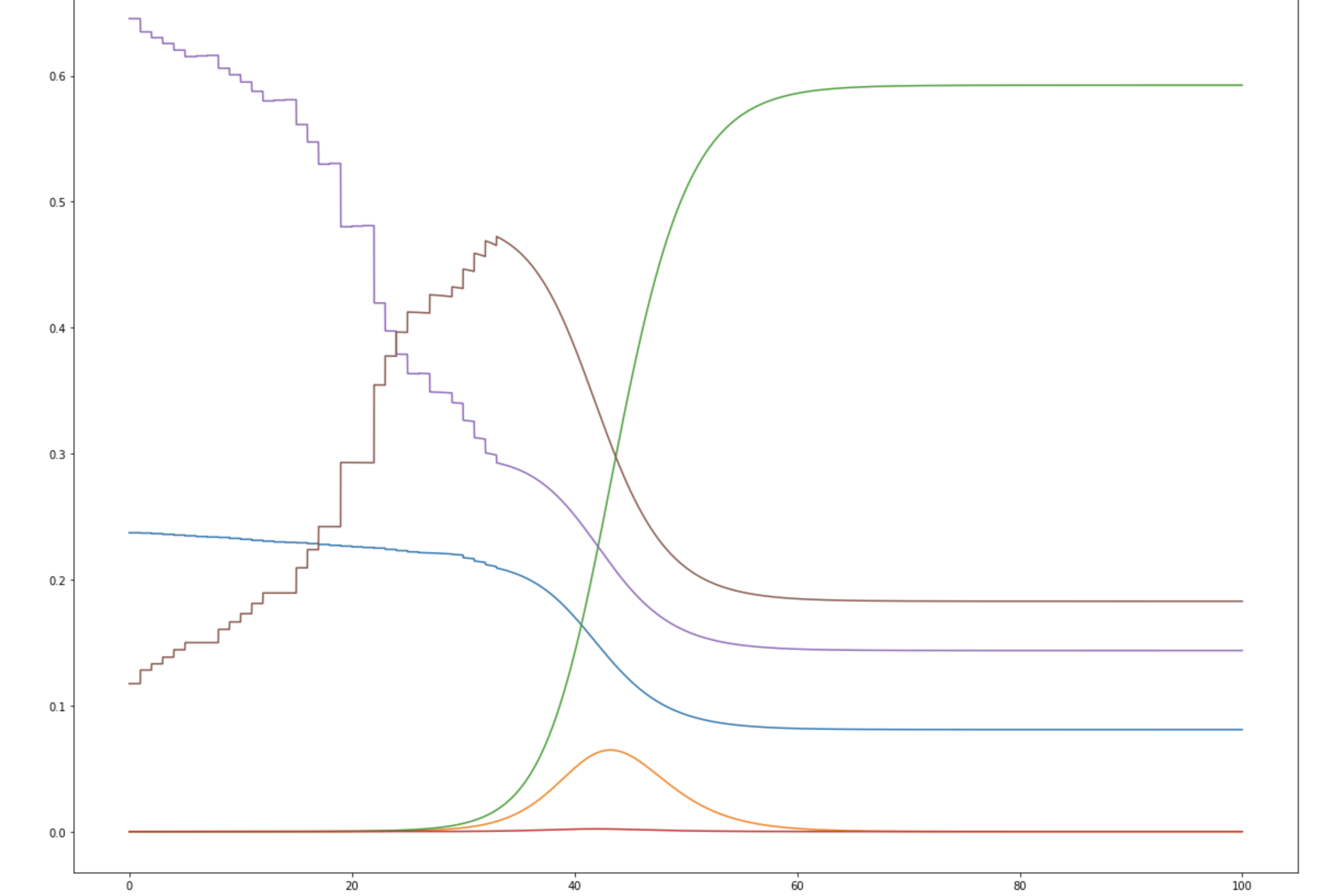
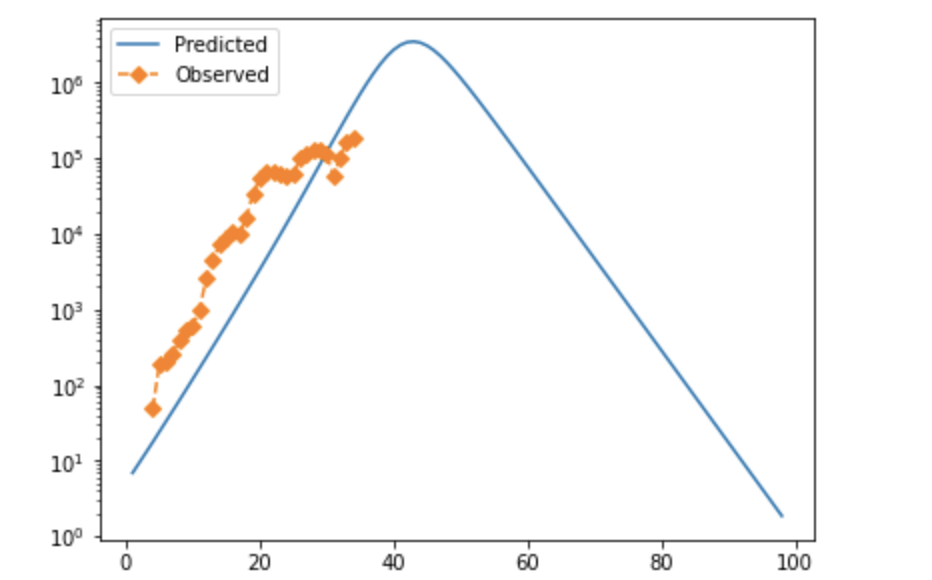
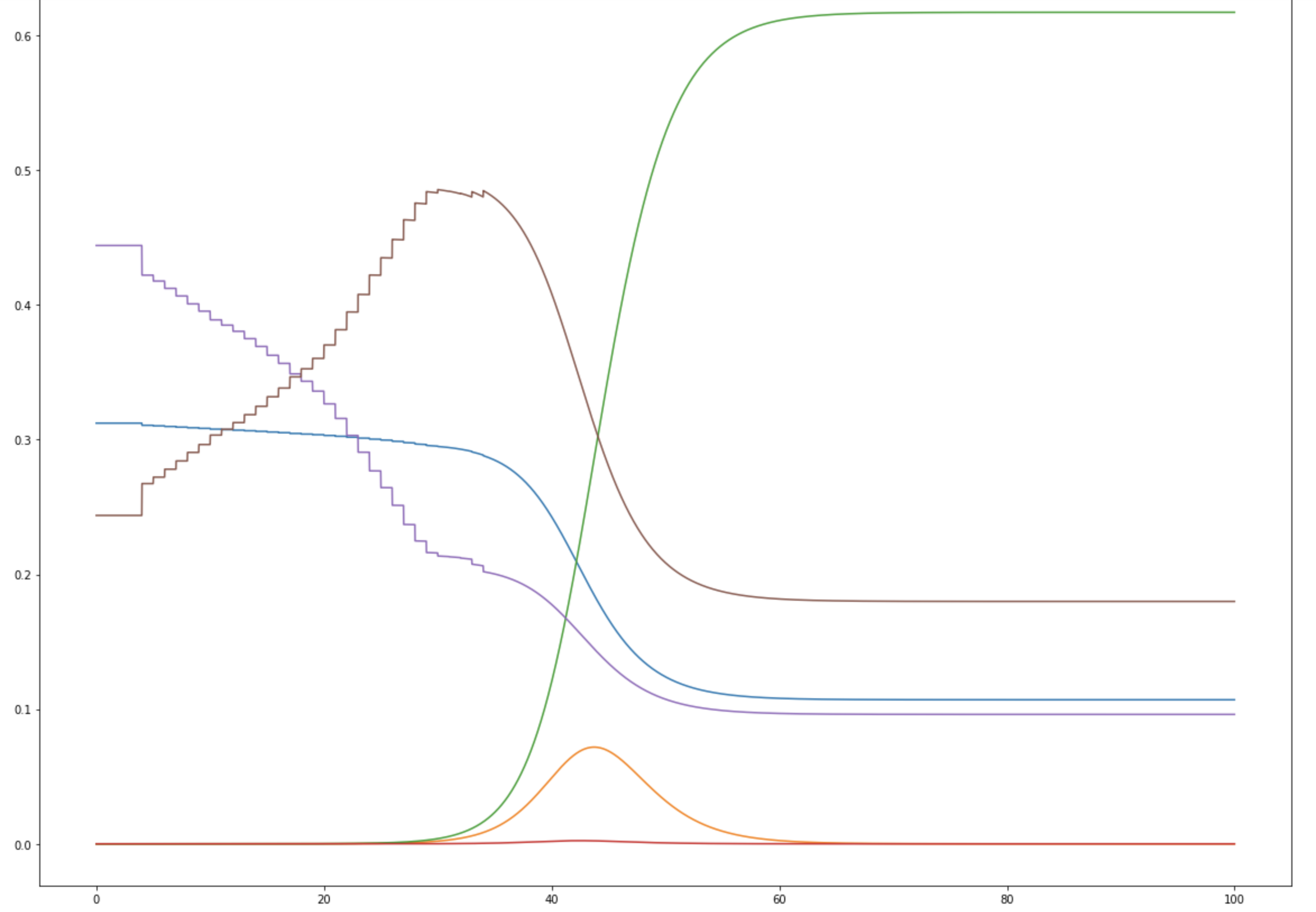
Note that in both cases, observed cases flatten as time goes on/cases rise. I strongly suspect this is due to testing failure, and will likely modify the error function to prioritize mid-case data or adjust for positivity rate. If anyone has rigorous suggestions about how to do that, I'd be very interested. These fits also look not-very-impressive because they're pretty exponential at the moment; they aren't perfect, but the similarity between the UK and Denmark is suggestive, and if you tweak things slightly accounting for both of these factors, you can get visually better fits—see below for why.
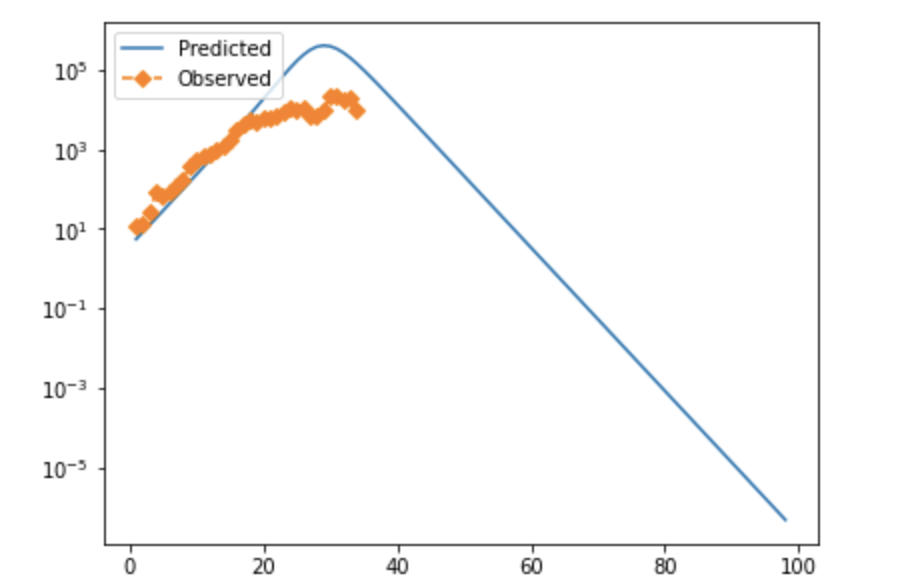
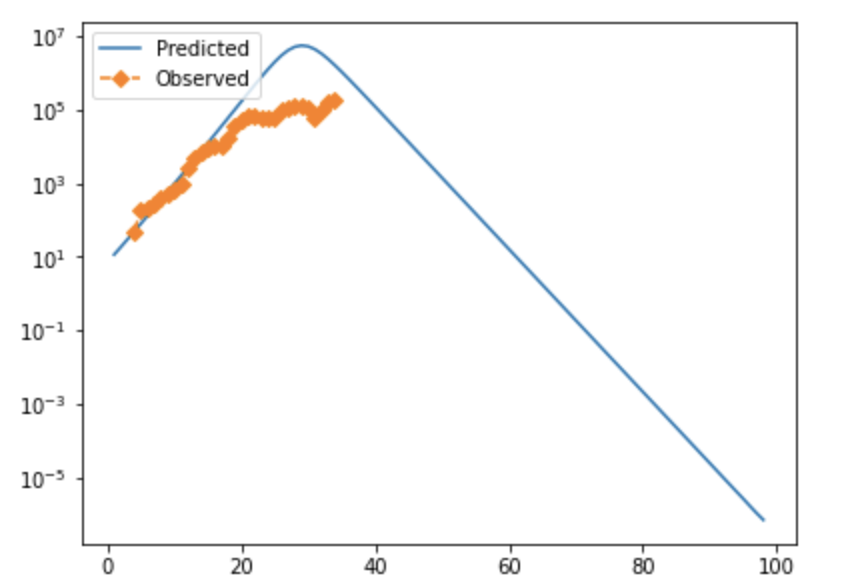
I'm not aware of a way to do fully numeric gradient descent, but in v2 of this, I'm going to improve the iteration element of the optimization algorithm to slide to an adjacent "square" if appropriate and/or add numeric discrete-direction descejnt. In the meantime, it's more appropriate to look at the points within a threshold of optimal, which form clouds as shown below (note that because many of these variables are at least partially inverted when considered in terms of viral characteristics, bigger clouds further from the origin are to be expected.
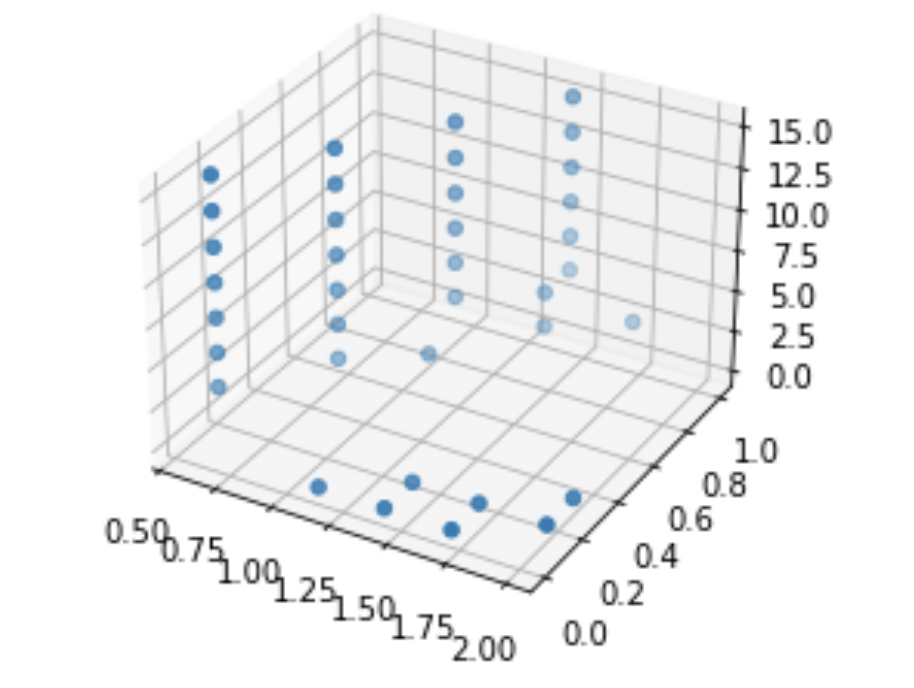
Please let me know if anyone's interested in any specific scenarios, confused, or having issues—there's a known bug where if any of the coefficients is greater than 1/resolution, things go to hell very quickly.
Ok, I think I understand our crux here. In the fields of math I’m talking about, 3^(-1) is a far better way to express the multiplicative inverse of 3, simply because it’s not dependent on any specific representation scheme and immediately carries the relevant meaning. I don’t know enough about the pedagogy of elementary school math to opine on that.
Sorry for the lack of clarity-I’m not talking about high school algebra, I’m talking about abstract algebra. I guess if we’re writing -2 as a simplification, that’s fine, but seems to introduce a kind of meaningless extra step-I don’t quite understand the “special cases” you’re talking about, because it seems to me that you can eliminate subtraction without doing this? In fact, for anything more abstract than calculus, that’s standard-groups, for example, don’t have subtraction defined (usually) other than as the addition of the inverse.
This seems super annoying when you start dealing with more abstract math: while it's plausibly more intuitive as a transition into finite fields (thinking specifically of quadratic residues, for example), it would really really suck for graphing, functions, calculus, or any sort of coefficent-based work. It also sounds tremendously annoying for conceptualizing bases/field-adjoins/sigma notation.
I’m trying to figure out what you mean-my current interpretation is that my post is an example of reason that will lead us astray. I could be wrong about this, and would appreciate correction, as the analogy isn’t quite “clicking” for me. If I’m right, I think it’s generally a good norm to provide some warrant for these types of things: I can vaguely see what you might mean, but it’s not obvious enough to me to be able to engage in productive discourse, or change my current endorsement of my opinion: I’m open to the possibility you might be right, but I don’t know what you’re saying. This might be just an understanding failure on my part, in which case I’d appreciate any guidance/correction/clarification.
This post seems excellent overall, and makes several arguments that I think represent the best of LessWrong self-reflection about rationality. It also spurred an interesting ongoing conversation about what integrity means, and how it interacts with updating.
The first part of the post is dedicated to discussions of misaligned incentives, and makes the claim that poorly aligned incentives are primarily to blame for irrational or incorrect decisions. I’m a little bit confused about this, specifically that nobody has pointed out the obvious corollary: the people in a vacuum, and especially people with well-aligned incentive structures, are broadly capable of making correct decisions. This seems to me like a highly controversial statement that makes the first part of the post suspicious, because it treads on the edge of proving (hypothesizing?) too much: it seems like a very ambitious statement worthy of further interrogation that people’s success at rationality is primarily about incentive structures, because that assumes a model in which humans are capable and preform high levels of rationality regularly. However, I can’t think of an obvious counterexample (a situation in which humans are predictably irrational despite having well-aligned incentives for rationality), and the formulation of this post has a ring of truth for me, which suggests to me that there’s at least something here. Conditional on this being correct, and there not being obvious counterexamples, this seems like a huge reframing that makes a nontrivial amount of the rationality community’s recent work inefficient-if humans are truly capable of behaving predictably rationally through good incentive structures, then CFAR, etc. should be working on imposing external incentive structures that reward accurate modeling, not rationality as a skill. The post obliquely mentions this through discussion of philosopher-kings, but I think this is a case in which an apparently weaker version of a thesis actually implies the stronger form: philosopher-kings being not useful for rationality implies that humans can behave predictably rationally, which implies that rationality-as-skill is irrelevant. This seems highly under-discussed to me, and this post is likely worthy of further promotion solely for its importance to this issue.
However, the second broad part of the post, examining (roughly) epistemic incentive structures, is also excellent. I strongly suspect that a unified definition of integrity with respect to behavior in line with ideology would be a significant advance in understanding how to effectively evaluate ideology that’s only “viewable” through behavior, and I think that this post makes an useful first step in laying out the difficulties of punishing behavior unmoored from principles while avoiding enforcing old unupdated beliefs. The comment section also has several threads that I think are worthy of revisitation: while the suggestion of allowing totally free second-level updating was found untenable due to the obvious hole of updating ideology to justify in-the-moment behavior, the discussion of ritual around excessive vows and Zvi’s (I believe) un-followed-up suggestion of distinguishing beliefs from principle both seem to have real promise to them: my guess would be that some element of ritual is necessary to avoid cheapening principle and allowing for sufficient contradictory principles to justify any behavior.
Finally, the discussion of accountability seems the least developed, but also a useful hook for further discussion. I especially like the suggestion of “mandatory double-crux”‘powers: I’ve informally tried this system by double-cruxing controversial decisions before action and upon reflection, I believe it’s the right level and type of impediment: likely to induce reflection, a non-trivial inconvenience, but not a setting that’s likely to shake well-justified beliefs and cause overcorrection.
Overall, I support collation of this post, and would strongly support collation if it was updated to pull more on the many potential threads it leaves.
That’s a fair point-see my comment to Raemon. The way I read it, the mod consensus was that we can’t just curate the post, meaning that comments are essentially the only option. To me, this means an incorrect/low quality post isn’t disqualifying, which doesn’t decrease the utility of the review, just the frame under which it should be interpreted.
That’s fair-I wasn’t disparaging the usefulness of the comment, just pointing out that the post itself is not actually what’s being reviewed, which is important, because it means that a low-quality post that sparks high-quality discussion isn’t disqualifying.
Note that this review is not of the content that was nominated; nomination justifications strongly suggest that the comment suggestion, not the linkpost, was nominated.
See my above comment, where I was trying to get a handle on this. It increasingly seems like the answer is that most of it comes from breakthrough+serial intervals