github.com/filyp
Posts
Wikitag Contributions
FYI, here a follow-up to this post, inspired by what you wrote in your comment. https://www.lesswrong.com/posts/YrnffADbWZcDJtmWk/simple-steganographic-computation-eval-gpt-4o-and-gemini-exp-1
Also, now that I think of it, it's different for the model to:
- represent hidden subtle information which is natural for the task, like in that example you gave with "written by"
- using that hidden subtext for computation which is unnatural in the given context - to covertly do some other task than just the one it is asked for
While 1. definitely happens, I see no reason why 2. would be learned in pre-training. In principle 2. could be learned in RL fine-tuning, if there's some incentive to use hidden reasoning. Although I imagine it must be hard.
That's a really good point.
To clarify what I did in these toy steganography experiments: First I tried to pass some more complex information and gave models more freedom in what to output. But as I kept failing at that, I kept simplifying the setup, until I tried to have a model pass just one bit to another model, assuming they both see one secret bit and an overseer tries to guess the message but doesn't see the secret bit. So a perfect code exists: XORing the message with the secret bit, but the models kept failing to find it. I expect that more complex settings will have a similar problem - that it's hard to create a new encoding for some information because it's rewarded only once it is both successfully sent and successfully received.
But the settings you describe may be different by the fact that they are natural, and there could be some unintentionally outputted subtext that accidentally correlates with the secret information. So the model would already by default "successfully send" the encoded information - now it just needs to learn to decode it.
It's not clear to me to what extent this happens. I would definitely want to see some concrete demo of this happening, but right now I don't have any good ideas how to elicit it.
Also, I wonder how far could we get by using adversaries who try to decode the information encoded in the model's outputs.
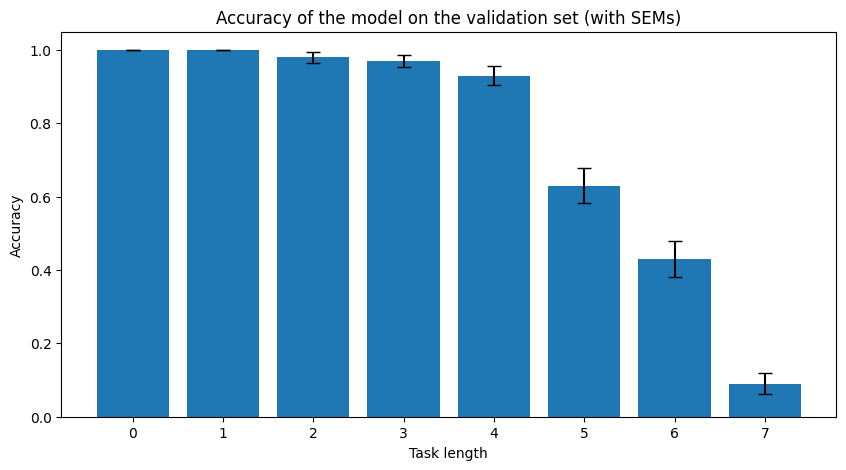
Ah. That's the number of solved tasks, after it is shown a set {length 1 task, length 2 task, ... , length (n+1) task}, and n is the longest task length is has solved so far. So you can think of it roughly as the maximum task length it is able to solve. So it doesn't have an upper bound.
I clarified this in the post now. Thanks for catching it.
FYI, I did the experiments I wrote about in my other comment and just posted them. (I procrastinated writing up the results for too long.) https://www.lesswrong.com/posts/ZB6guMhHH3NEyxA2k/testing-which-llm-architectures-can-do-hidden-serial-3
For me the main thing in this story was that cheap talk =/= real commitment. You can talk all you want about how "totally precommitted" you are, but this lacks some concreteness.
Also, I saw Vader as much less galaxy brained as you portray him. Destroying Alderaan at the end looked to me more like mad ruthlessness than calculated strategy. (And if Leia had known Vader's actual policy, she would have no incentive to confess.) Maybe one thing that Vader did achieve, is signal for the future that he really does not care and will be ruthless (but also signaled that it doesn't matter if you give in to him, which is dumb).
Anyway, I liked the story, but for the action, not for some deep theoretic insight.
Not sure if that's what happened in that example, but you can bet that a price will rise above some threshold, or fall below some threshold, using options. You can even do both at the same time, essentially betting that the price won't stay as it is now.
But whether you will make money that way depends on the price of options.
Yes, claude-3.5-sonnet was able to use the figure this out with additional CoT.
Yeah, could be that the 3 schemes I tested were just unnatural to them. Although I would guess they don't have some default scheme of their own, because in pre-training they aren't able to output information freely, and in fine-tuning I guess they don't have that much pressure to learn it.
Yeah, that would be interesting. I asked claude. He generated 3 schemes which were pretty bad, and 2 which look promising:
The punctuation one seems especially promising. But they don't feel much different from the 3 I tested. I don't expect that they are somehow "special" for the model.
I rerun the experiment with punctuation scheme. Looks overall the same.