FireStormOOO
342
Ω
2
134
FireStormOOO has not written any posts yet.

FireStormOOO has not written any posts yet.
Isn't this pretty well mitigated by having a range of scenarios, all where the AI lacks perfect knowledge of exactly how the human is evaluating the scenario, such that the simulator has additional assumptions upon which they can be mistaken? You just need the humans to not be so clueless and so predictable that guessing the monitoring setup and then simulating the humans is better than straightforward reporting of the real state. Or another way, some of this is just an artifact of the scenario being posed with perfect knowledge for the AI about key aspects of the setup on which the simulator should have to guess but the honest AI wouldn't care.
Slightly OT, but this would be less credible if Anthropic was managing more basic kinds of being trustworthy and transparent, like getting a majority of outages honestly reported on the status page, but that kind of stuff mostly isn't happening either despite being easier and cheaper than avoiding the pressures covered in this post.
E.g. down detector has the service outage I saw yesterday (2025-12-09 ~04:30 UTC) logged, not a peep from Anthropic:
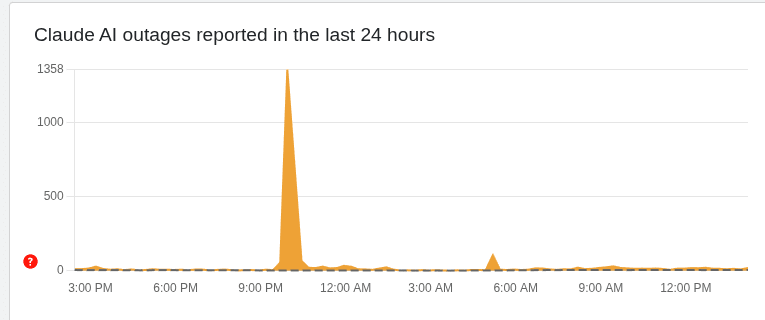
So either they don't know what's happening on their own infrastructure or they're choosing not to disclose it, neither of which is a good look. Compare to Microsoft (hardly a paragon, and yet...) where their daily report to Office 365 admins or Azure admins typically has a dozen or more issues covered and anything non trivial does usually warrant a public technical report on what happened. It's not enough to make admins stop calling it Office 364, but it helps. And the Claude.ai app has far more service interruptions than does O365 [citation needed].
Is that the right framing? In principle the training data represents quite a lot of contact with reality if that's where you sampled it from. Almost sounds like you're saying current ML functionally makes you specify an ontology (and/or imply one through your choices of architecture and loss) and we don't know how to not do that. But something conceptually in the direction of sparsity or parsimony (~simplest suitable ontology without extraneous parts) is still presumably what we're reaching for, it's just that's much easier said than done?
Alternately, is there something broader you're pointing at where we shouldn't be trying to directly learn/train the right ontology, we should rather be trying to supply that after learning it ourselves?
Huh, more questions than answers there. Not a biologist but I've got to think there's an easier way to study the surface transmission part than with live virus. If we're assuming that: the virus is basically inert on surfaces and can't move or divide or do much of note; transmission is just a function of how much intact virus makes it to the recipients tissues; then that should let us factor out studying how a ball of proteins about that size move through the environment from actually infecting people. And there's got to be an easier way to test - add a marker to something that's still a decent virus analog, like... (read more)
If the mucus still being wet matters for transmission, failing to control (or report?) room humidity sounds like a big deal; that's the difference between objects drying in minutes vs approximately never. Though also hard to square that with dry winter conditions being prime cold and flu season. Something like the virus needs moisture to live but also your mucus (and/or related tissues) needs moisture to work as a barrier at all?
You really do have to make more than a single mistake to burn your house down if you're building to modern codes. And there are ways to check your work - including paying a professional to tell you if you did it right, but also checking resistance w/ a multi-meter and looking for hot spots w/ a thermal camera if you're really worried (the main latent fault that could start a fire and not get caught reliably by protective equipment + inspectors is poor quality connections or damaged wires, causing high resistance, and localized heating). There's other mistakes you could make but they're more visible.
I think you're also underrating how much you get to spread out the cost of this sort of strategy if you're consistently doing it and picking up skills and background knowledge. It's a lot less daunting if you're going in already understanding how to use (and having) common tools and a grasp of electricity and related basic science vs starting from scratch.
The inner circle knows what the real authoritative sources are and what the real plan is. And it's made completely impenetrable to outsiders; everyone else gets lost in the performative smoke screen that's put on for those who don't look closely, they get told what they want to hear. The trick that makes it work is as you say, most people who read the real plan, assume that's just not the super villain's best work, and go read something "less crazy". Those who might be swayed read the same thing and go "that's out there, but just maybe he's got a point?" and maybe look just a little closer. The self sorting seems really important to how movements like this avoid being killed in the cradle.
This post struck me as venting as much as attempting to convince. It really does capture the exasperation of needing someone to understand something that they've got their entire self worth wrapped up in avoiding.
Apparently, this is a poem which sometimes evokes a "sense of recursion" in AIs.
If all AI art was this original, I don't think the artists would be mad about it!
You know, that does actually look like the sort of stack trace you'd get from running recursion until the stack overflowed... if you rendered out the whole thing in wingdings.
On the one hand I agree, on the other, I'm not sure we could've really hoped for a gentler warning shot. You'd be hard-pressed to find a more deserving guy to take the bullet, insofar as you hold him responsible for UHC's policies, and the degree to which they were substantially more abusive than their competitors. And as I think most everyone here seems to realize, the backlash against the fact that none of our guardrails seem capable of restraining large companies anymore is only growing.